







MapReduce 算法设计-Local Aggregation
本文主要内容来自由马里兰大学的Jimmy Lin 和 Chris Dyer写的《Data-Intensive Text Processing with MapReduce》一书中的第三章,如有错误,欢迎指正。
更新说明:我发现已经有很多人翻译过这本书的该部分内容,因而以后的博客会更关注程序实现以及实验部分,理论部分会给出其他博客的参考链接。
1 技术原理
在数据密集型分布式处理环境中,同步化最重要的一个特征是中间数据的转移,即从产生数据的步骤到使用这些数据的步骤。在Hadoop中,中间结果在通过网络发送出去之前先写入本地磁盘。由于网络传输以及磁盘延迟相对于其他操作比较费时,因而减少中间数据的产生则会提高算法的效率。在MapReduce中,对中间结果的local aggregation是提升算法效率的几种关键手段之一。
为了说明local aggregation的几种不同手段,我们使用一个简单的例子-word count问题。图1给出了最基本的word count程序的伪代码,原理非常简单:mapper函数为其观测到的每一个单词发送一个中间结果的key-value对,其中key为其观测到的单词本身,value的值为1;reducers函数累加所有的中间结果并输出最终结果。

local aggregation的第一种手段是利用combiner,combiners为在MapReduce框架下减少由mapper产生的中间数据提供了一个通用的机理,它们可以理解为为 “mini-reducers“来处理mappers的输出结果。在本例中,combiners会聚合被不同mapper处理出来的term count值。因而,需要通过网络shuffled的中间结果key-value对的数量就会减少,即从划分出的所有的terms的数量减少为独有的terms的数量(通过combine聚合了重复的key-value对)。
一种对上面基本算法的改进算法如下图所示,其中reducer保持不变。主要区别在于在map函数中加入一关联数组来总结来自同一个文档(或同一行,看mapper split方式)的term counts值。因而,不再是对该文档(行)中的每一个单词都发送一个key-value对,而是对该文档(行)中每一个不同的单词发送key-value对。如果某文档(行)含有大量重复terms,这种方法可以极大地减少中间结果的数量。简单举例如“a b a a b b b“,基本方法将会发送7个key-value对,而改进方法只需发送2个key-value对。
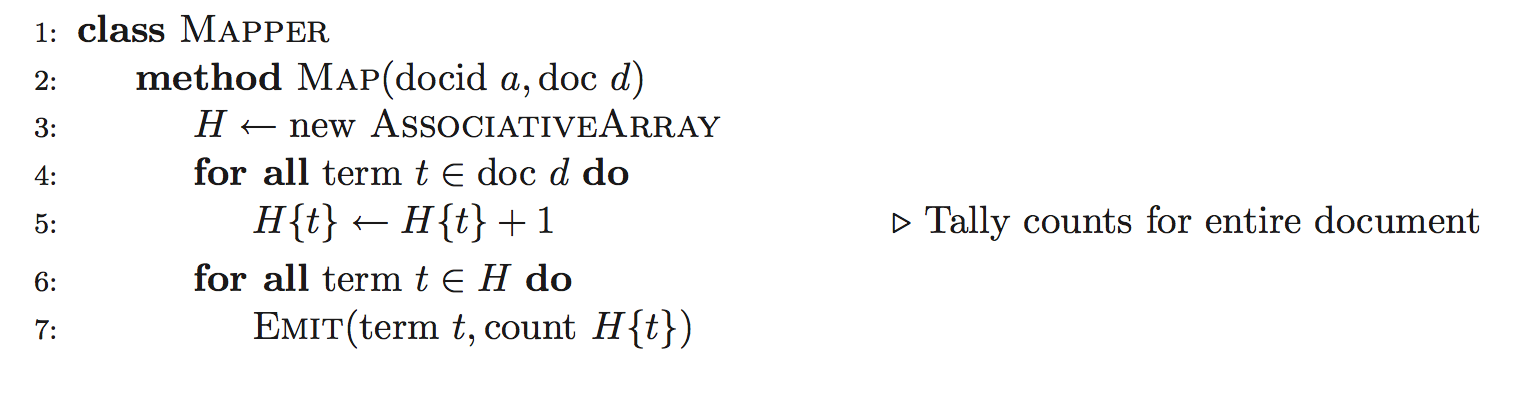
上述的思想可以更进一步,如下图的算法变种。同样,只需改变mapper,而reducer无需改变。改算法的运行得益于Hadoop中的mapper和reducer是如何运行的。mapper开始于一个初始化函数,在该函数中在处理任何输入key-value对之前初始化一关联数组。由于可以保存跨越多个map函数的状态,因而我们可以继续利用该关联数据来累加来自跨越多个文档(行)中的term counts,然后等所有的mapper处理完了所有的文档(行)再发送中间结果key-value对。也就是,在伪代码中,中间结果key-value对的发送是被延迟到了close函数中,即等map函数处理完所有的输入key-value对。
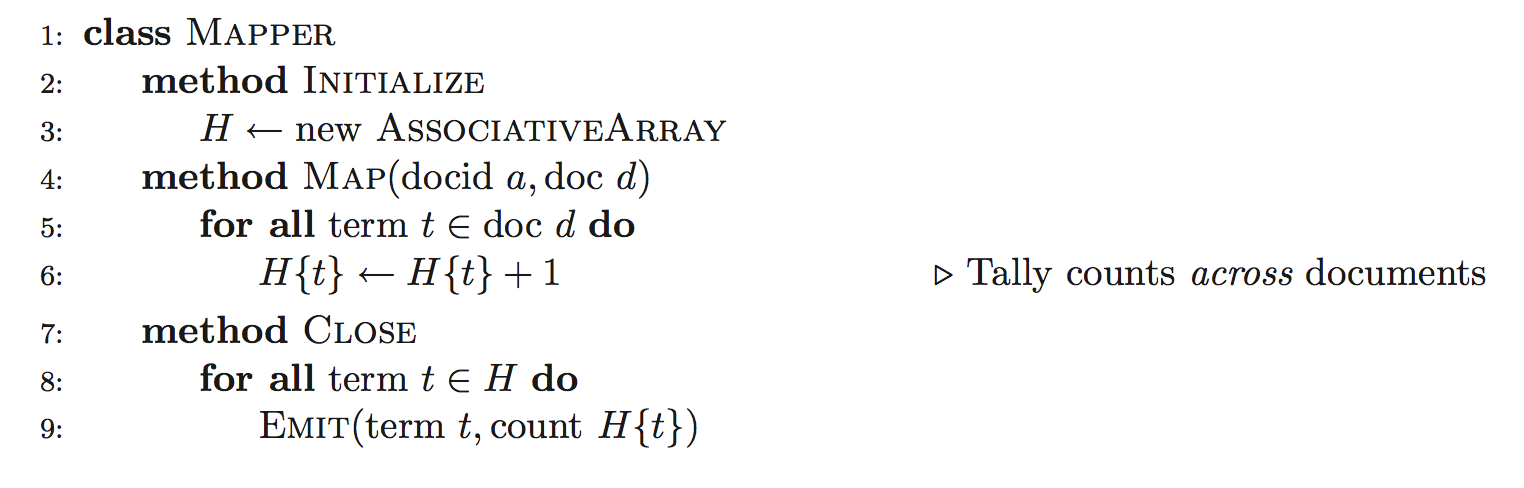
在上述的技术手段中,我们把combiner的函数功能直接迁移进了mapper中,这种设计模式被称为“in-mapper combining“。这种设计模式有几种明显的优点:
- 提供对local aggregation 的何时发生以及怎样发生的完全控制。相反,combiner的语义在MapReduce中是不指定的。Hadoop并不保证combiner会被应用多少次或者一次都不用。在某些情况下,这种中间机制是不可接受的,这也是为什么程序员经常会在mapper里使用local aggregation。
- in-mapper combining比实际的combiner要更高效。其中的一个原因是combiner虽然减少了通过网络shuffled中间结果key-value对数量,但并没有真正的减少在mapper第一阶段产生的中间结果key-value对数量。而在这一阶段包含许多不必要的对象创建与销毁(垃圾回收需要时间),更进一步,以及对象的序列化与反序列化(中间结果存本地与再读入内存)。相反,使用in-mapper combining只需为那些真正需要在网络上shuffled的中间结果key-value对创建上述那些东西。
当然,in-mapper combining设计模式也存在缺点。
- 其打破了MapReduce的函数式编程理念,因为其保存了来自多个输入key-value对的状态。这一点也不是个大问题,因为为了提高效率,人们经常牺牲一下理论的“纯净性“。保存来自不同输入对的状态意味着算法依赖于遇到的输入key-value对的顺序,这可能会导致顺序依赖的bugs,而当数据量很大时却又很难debug。
- in-mapper combining技术有一个最基本的可扩展性瓶颈问题。因为其依赖于有足够的内存来保存中间结果,直到所有的mapper处理完所有的输入key-value对。图3的算法只能扩展到某一个点,超出后,内存中将放不下关联数组中的数据。
一种常用的限制内存使用的解决方案是当使用in-mapper combining技术时去“block“输入key-value对并且周期性的“flush“在内存中的数据。想法很简单:当每处理完n个输入key-value对发送部分结果,而不是等每一个输入key-value对处理完再发送key-value对。可以直接地通过一个计数变量实现,该计数变量记录着已经被处理过的输入key-value对的数量。另外一种实现时,mapper可以追踪其自身的内存痕迹,当内存使用率到达一定阈值时“flush“中间结果key-value对。
本部分也有很多人直接翻译过书本第三章内容,这里给出参考链接:
Data-Intensive Text Processing with MapReduce 第三章(1)——local aggregation
2 程序实现与实验
针对上述技术原理,我编写了相应的word count程序,并在hadooop集群上做了对比试验。
2.1 程序代码
本文程序采用java编写,利用Hadoop-2.6.0 版本提供接口。
package mp.wordcount;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
*
* @author liupenghe
* 描述:word count
*/
public class WordCount {
public static class WordMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
/**
* 描述:map阶段,
* input_key:文件的行索引,input_value:文件的每一行的内容
* output_key:每一个切分后的单词, output_value:1
*/
@Override
public void map(LongWritable key, Text value, Context context)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









