







1.什么是决策树
1.1 决策规则
决策树是线性决策,其每个非叶节点表示一个特征属性上的判断,叶节点表示出现的结果。
决策树的决策过程(即每个分支)是从决策树的根节点开始,待测数据与决策树中的特征节点进行比较,并按照比较结果选择下一个比较节点,直到叶节点作为最终的决策结果。可以表示为:
If 条件1 and 条件2 and 条件3 then 结果
1.2决策树绘制
决策节点:使用矩形框表示;
机会节点:使用圆圈表示;
终结点:使用三角形表示。
1.3决策树的经典算法 ID3、C4.5、CART
2. 决策树的建立
特征选择:从训练数据的特征中选择一个特征作为当前节点的分裂标准
决策树生成:依据选择特征标准,从上至下递归生成子节点,直到数据集不可再分则停止。
剪枝:决策树易过拟合,需要通过剪枝来缩小树的结构和规模。
3. 决策树-ID3算法
3.1 特征选择
决策树的目标是将数据集按对应类标签进行分类。通过特征的选择将不同类别的数据集“赋予”对应的标签。特征选择的目标使得分类后的数据更佳“有序”。如何衡量一个数据集“有序”程度(或称纯度),通过数据纯度函数来判断,这里介绍两种纯度函数:
1.0 信息增益(information gain)
信息熵(entropy)表示信息的期望(即不确定程度)。当选择某个特征对数据集进行分类,划分前后数据集信息熵的差值表示为信息增益。信息增益衡量某个特征对分类结果的影响大小。
假设:训练数据集为D,数据类别数为c。在构建决策树时,根据某个特征对数据集进行分类。在此,计算出该数据中的信息熵:
A.分类前的信息熵计算公式
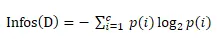
Pi表示类别i样本数量占所有样本的比例。
B.分类后的信息熵计算公式 对应数据集D,选择特征A作为决策树判断节点时,在特征A作用后信息熵为Infosa(D),其计算公式如下:
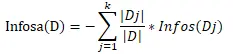
K表示顺联数据集D被划分为k个部分。
C.数据集的信息增益
信息增益表示数据集D在特征A的作用后,其信息熵减少的值,计算公式如下: Gain(A)=Infos(D)−Infosa(D)
2.0 基尼不纯度(Gini impurity) 从一个数据集中随机选取子项,度量其被错误分类到其它分组里的概率。
分类前信息熵计算公式
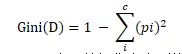
c表示数据集中类别的数量;pi表示类别i样本数量所占样本比例。
分类后信息熵计算公式

数据集的信息增益 ∆Gini(A)=Ginia(D)−Gini(D)
选择增益最大的特征作为该节点的分裂条件。
3.2 剪枝
在分类模型建立过程中,容易出现过拟合情况。
过拟合是指在模型学习训练中,训练样本精确度非常高,导致非训练样本的精确度的误差随着训练次数先下降后上升的现象。 标准定义:给定一个假设空间H,一个假设h属于H,如果存在其他的假设h’属于H,使得在训练样例上h的错误率比h’小,但在整个实例分布上h’比h的错误率小,那么就说假设h过度拟合训练数据。 ----《Machine Learning》Tom M.Mitchell
决策树的拟合现象通过“剪枝”技术做一定的修复。“剪枝”分为“预剪枝”和“后剪枝”。
预剪枝:在决策树创建过程中,算法中加入一定的限制条件来终止树的生长,以避免过拟合度。通常的方法,信息增益小于一定阀值的请示后通过剪枝使决策树停止生长。阀值设置不当导致模型拟合不足和过拟合情况。
后剪枝:在决策树生长之后,按照自下而上的方式进行修剪决策树。通常两种方式:一种用新的叶节点来替换分支;另一种用最常使用分支来替换。
3.3 优点和缺点
优点:计算复杂度不高,输出结构易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。 N缺点:可能会产生过度匹配问题。
4. 决策树-ID3算法实现:基于python 和 numpy
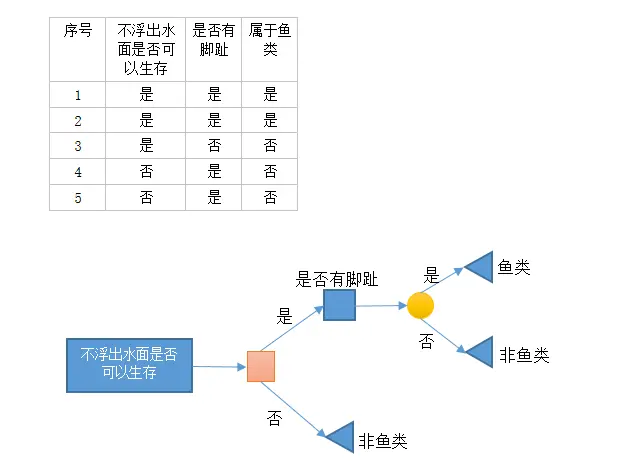
示例:
4.1 算法伪代码
CreateBranch()
检测数据集中的每个子项是否属于同一分类:
If so return 类标签 Else 寻找划分数据集的最好特征
划分数据集
创建分支节点 For 每个划分的子集
调用函数createBranch并增加返回结果到分支节点中
Return 分支节点
4.2 算法实现
-- coding: utf-8 --
"""Created on Sat Jun 18 16:50:40 2016
@author: Paul.lu"""from math import logimport operator
创建样本数据集和标签
def createDataSet(): dataSet = [[1,1,'yes'], [1,1,'yes'], [1,0,'no'], [0,1,'no'], [0,1,'no']] labels = ['no surfacing','flippers'] return dataSet,labels
dataSet,labels = createDataSet()
'''
说明:计算特征值的熵
返回:熵值
'''def calcShannonEnt(dataSet): numEntries = len(dataSet) labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
#计算“熵”
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries
shannonEnt -= prob * log(prob,2)
return shannonEnt
shannonEnt = calcShannonEnt(dataSet)
'''
说明:划分数据集
splitDataSet(待划分的数据集,划分数据集的特征,特征的返回值)
返回:划分数据集
'''def splitDataSet(dataSet,axis,value): retDataSet = [] for featVec in dataSet: if featVec[axis] == value: reducedFeatVec = featVec[:axis] reducedFeatVec.extend(featVec[axis+1:]) retDataSet.append(reducedFeatVec) return retDataSet
'''说明:选择最好的数据划分方式1、计算信息增益:Gain(A) = Info(D) - InfoA(D)
'''def chooseBestFeatureToSplit(dataSet):
#获得标签个数
numFeatures = len(dataSet[0]) - 1
#计算“数据集拆分前信息熵”
baseEntropy = calcShannonEnt(dataSet)
#计算“数据集拆分后信息熵”
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
#计算“信息增益”
infoGain = baseEntropy - newEntropy
#获得“信息增益”最大值
if(infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
chooseBestFeatureToSplit(dataSet)
'''
说明:如果数据集已经处理了所有属性,但是类标签依然不是唯一的,对该类叶子节点,通过多数表决来确定该叶子节点的分类。
'''def majorityCnt(classList): classCount = {} for vote in classList: if vote not in classCount.keys(): classCount[vote] = 0 classCount[vote] += 1 sortedClassCount = sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True) return sortedClassCount
'''
创建决策树
输入:样本数据集、标签列表
返回:决策树
说明:
1、递归终止条件: 程序遍历完所有划分数据集的属性,或者每个分支下的所有实例都具有相同的分类。
2、选择最好的数据集划分; 2.1 计算数据集划分前“信息熵” 2.2 计算数据集划分后“信息熵” 2.3 计算“信息增益” = Info(D) - Infoa(D) 2.4 获得最大的“信息增益”,以获得最好的数据划分。
3、遍历特征值,创建分支。
返回数据集示例:最终返回数据集dict形式的数据: {'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}'''def createTree(dataSet,labels): classList = [example[-1] for example in dataSet] '''递归终止的条件:程序遍历完所有划分数据集的属性,或者每个分支下的所有实例都具有相同的分类。''' if classList.count(classList[0]) == len(classList): return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
'''选择最好的数据集划分'''
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
'''对特征值进行遍历,创建分支'''
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels)
return myTree
ct = createTree(dataSet,labels)print ct原文链接:http://www.jianshu.com/p/5556c97d1b1f















 218
218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









