







什么是决策树?
决策树是一种解决分类问题的算法。
决策树算法采用树形结构,使用层层推理来实现最终的分类。决策树由下面几种元素构成:
- 根节点:包含样本的全集
- 内部节点:对应特征属性测试
- 叶节点:代表决策的结果
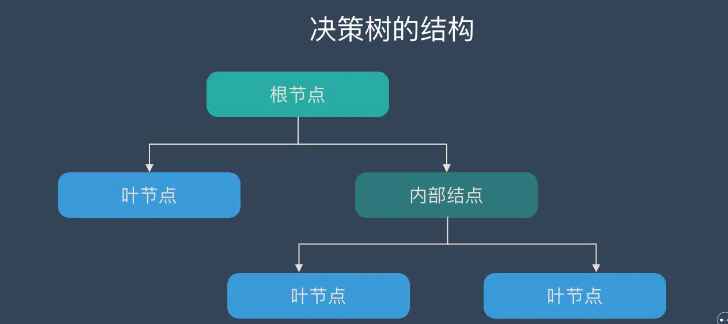
预测时,在树的内部节点处用某一属性值进行判断,根据判断结果决定进入哪个分支节点,直到到达叶节点处,得到分类结果。
举个例子:
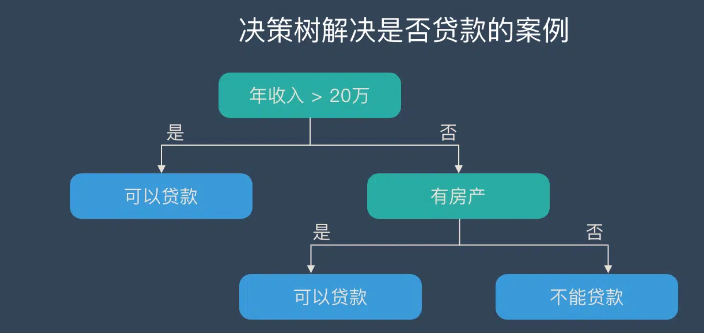
银行要用机器学习算法来确定是否给客户发放贷款,为此需要考察客户的年收入,是否有房产这两个指标。领导安排你实现这个算法,你想到了最简单的线性模型,很快就完成了这个任务。
首先判断客户的年收入指标。如果大于20万,可以贷款;否则继续判断。然后判断客户是否有房产。如果有房产,可以贷款;否则不能贷款。
决策学习的3个步骤
特征选择
特征选择决定了使用哪些特征来做判断。在训练数据集中,每个样本的属性可能有很多个,不同属性的作用有大有小。因而特征选择的作用就是筛选出跟分类结果相关性较高的特征,也就是分类能力较强的特征。
在特征选择中通常使用的准则是:信息增益。
决策树生成
选择好特征后,就从根节点触发,对节点计算所有特征的信息增益,选择信息增益最大的特征作为节点特征,根据该特征的不同取值建立子节点;对每个子节点使用相同的方式生成新的子节点,直到信息增益很小或者没有特征可以选择为止。
决策树剪枝
剪枝的主要目的是对抗「过拟合」,通过主动去掉部分分支来降低过拟合的风险。
3种决策树算法
ID3算法(迭代二分法)
ID3 是最早提出的决策树算法,他就是利用信息增益来选择特征的。基本上ID3树的全部意义在于最大限度地提高信息收益,因此也被称为贪婪的树。
从技术上讲,信息增益是使用熵作为杂质测量的标准。
简单地说,熵是(dis)顺序的衡量标准,它能够表示信息的缺失流量,或者数据的混乱程度。缺失大量信息的东西被认为是无序的(即具有高度熵),反之则是低度熵。
举个例子
假设一个凌乱的房间,地板上是脏衣服,也许还有一些乐高积木,或者switch、iPad等等。总之房间非常乱,那么它就是熵很高、信息增益很低。
现在你开始清理这个房间,把散落各处的东西意义归类。那么就是低熵和高信息增益。
好,回到决策树。ID3树将始终做出让他们获得最高收益的决定,更多信息、更少的熵。
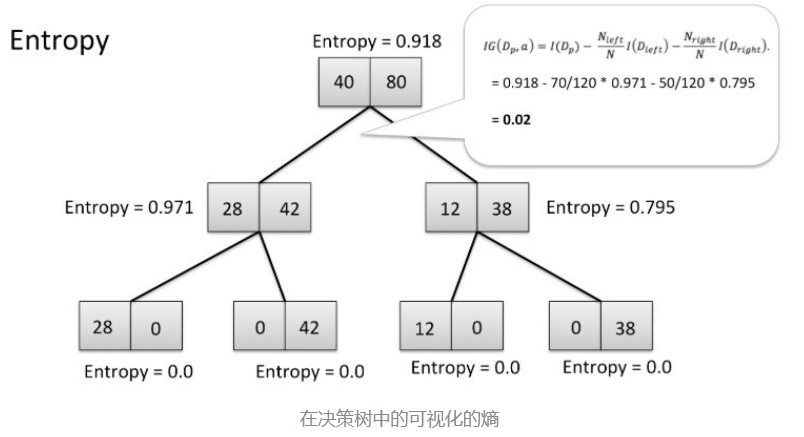
在上面的树中,你可以看到起始点的熵为0.918,而停止点的熵为0.这棵树以高信息增益和低熵结束,这正是我们想要的。
除了向低熵方向发展外,ID3树还将做出让他们获得最高纯度的决定。 因为ID3希望每个决定都尽可能清晰,具有低熵的物质也具有高纯度,高信息增益=低熵=高纯度。
其实结合到现实生活中,如果某些事情令人困惑和混乱(即具有高熵),那么对该事物的理解就会是模糊的,不清楚的或不纯的。
C4.5算法
他是 ID3 的改进版,他不是直接使用信息增益,而是引入“信息增益比”指标作为特征的选择依据。
CART算法(分类和回归树)
这种算法即可以用于分类,也可以用于回归问题。CART 算法使用了基尼系数取代了信息熵模型,旨在最小化基尼指数。
基尼指数可以表示数据集中随机选择的数据点可能被错误分类的频率。 我们总是希望最小化错误标记数据可能性对吧,这就是CART树的目的。















 405
405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









