







- 1、.net8 Logging集成log4net&kafka,扩展log4net 的Appender使日志可统一发至Kafka;
- 自定义日志中间件使用示例(需要源码私聊)
-
public override void ConfigureServices(ServiceConfigurationContext context) { context.Services.AddLogging(c => { c.AddFilter("Microsoft", LogLevel.Warning); //设置默认级别 c.SetMinimumLevel(LogLevel.Information); //过滤掉系统默认的一些日志 c.AddFilter("System", LogLevel.Warning); //默认的配置文件路径是在根目录,且文件名为log4net.kafka.config //c.AddLog4Net(); //如果文件路径或名称有变化,需要重新设置其路径或名称 //比如在项目根目录下创建一个名为 Configure 的文件夹,将 log4net.kafka.config 文件移入其中 //则需要使用下面的代码来进行配置 c.AddLog4Net(new Log4NetProviderOptions() { Log4NetConfigFileName = "Configure/log4net.kafka.config", Watch = true }); }); }//logger使用方式 private readonly ILogger<RoleController> logger; private readonly IRoleService roleService; private readonly IConfiguration configuration; public RoleController(ILogger<RoleController> logger, IRoleService roleService, IConfiguration configuration ) { this.logger = logger; this.roleService = roleService; this.configuration = configuration; } [HttpGet] [Route("get-name")] [AllowAnonymous] public IActionResult GetName() { this.logger.LogInformation("角色管理Controller > 获取角色名称"); this.logger.LogInformation("Role Controller > This is an English log message"); return Response(success: true, data: roleService.getRoleName()); } - 2、Doris在日志分析场景下的库表设计
- 为何选Doris?
- 日志量太大如何归档?
- 文本搜索太慢怎么办?
- 如何多维度查询及关联查询分析等等
- 解决上面的问题
- 需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。ELK就是解决这些问题的一种解决方案。
- 利用Doris的MPP执行框架、向量化计算引擎、列式存储、标准SQL、CBO的查询优化器等特性为用户提供高性能,低成本的日志分析服务。
- 一定要先拿下官网文档:Apache Doris: Open-Source Real-Time Data Warehouse - Apache Doris
- 使用Mysql客户端连接FE(可以是Navicat,只是连接,查看,干不了其他)
- Doris中的引擎
- olap
- mysql
- broker
- Hive
- Doris中的三大数据模型:
- 聚合模型 Aggregate
- 主键模型 Unique
- 明细模型 Duplicate
- Doris中分区类型
- Range:分区列通常为时间列,以方便的管理新旧数据。Range 分区支持的列类型 DATE, DATETIME, TINYINT, SMALLINT, INT, BIGINT, LARGEINT。
- List:分区列支持 BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE, DATETIME, CHAR, VARCHAR 数据类型,分区值为枚举值。只有当数据为目标分区枚举值其中之一时,才可以命中分区。
- [约定]一个微服务对应一个表
- 在 Doris 中,数据以表(Table)的形式进行逻辑上的描述。
- 创建一张合格的表,主要考虑以下几个方面:
- 字段
- 索引
- 引擎
- 模型
- 分区
- 分桶
- 属性
- Doris 的建表是一个同步命令,命令返回成功,即表示建表成功。
- Doris 支持支持单分区和复合分区两种建表方式:
- 1)单分区:只做 HASH 分布,即只分桶。
- 2)复合分区:既有分区也有分桶
- 第一级称为 Partition,即分区。用户可以指定某一维度列作为分区列(当前只支持整型和时间类型的列),并指定每个分区的取值范围。
- 第二级称为 Distribution,即分桶。用户可以指定一个或多个维度列以及桶数对数据进行 HASH 分布。
- 分区和分桶(Partition & Tablet)
- Doris 支持两层的数据划分。第一层是分区(Partition),支持 Range 和 List 的划分方式。
- 第二层是 Bucket(Tablet),支持 Hash 和 Random 的划分方式。建表时如果不建立分区,此时 Doris 会生成一个默认的分区,对用户是透明的。使用默认分区时,只支持 Bucket 划分。
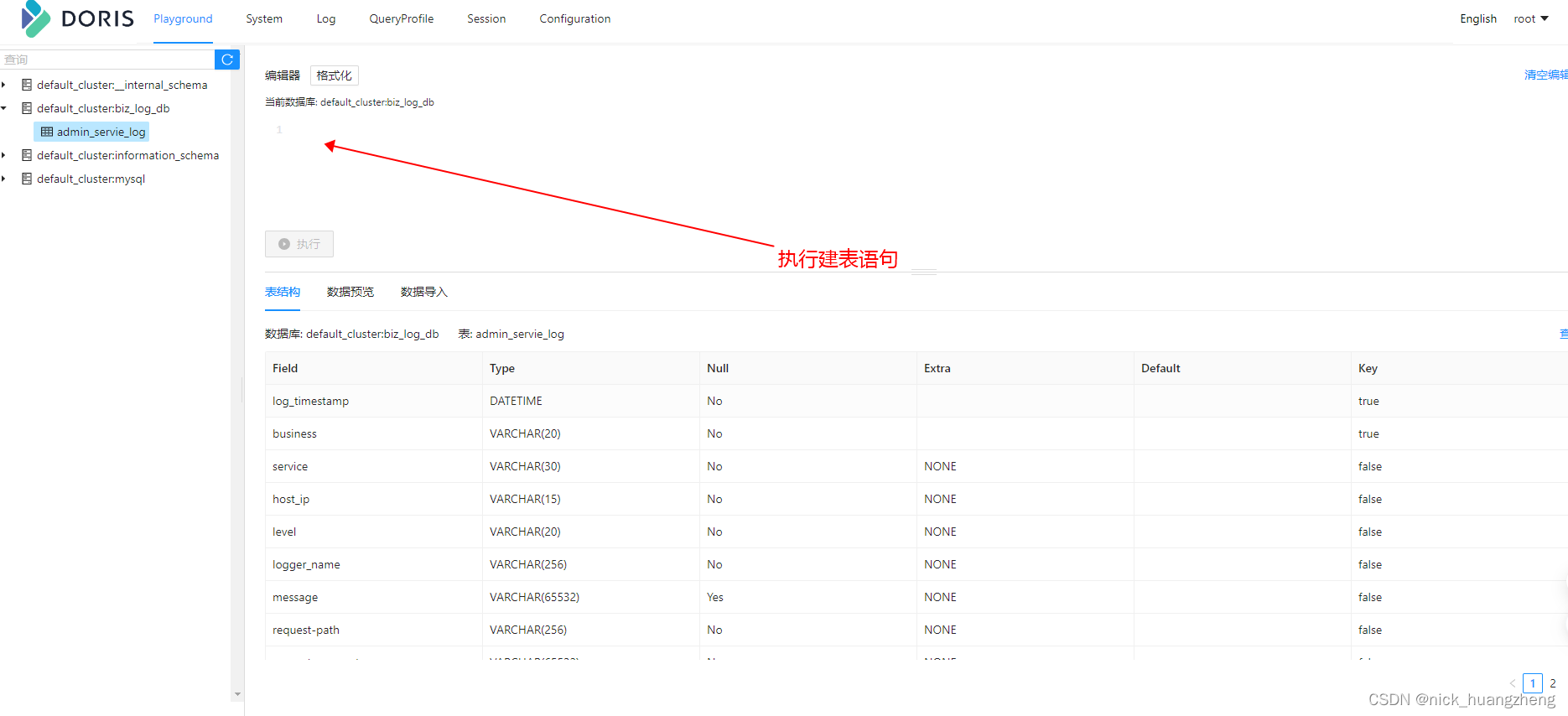
- 系统日志建表语句
CREATE TABLE IF NOT EXISTS biz_log_db.ods_example_service_log (
`log_timestamp` BIGINT NOT NULL DEFAULT "0" COMMENT "记录日志时的时间(时间戳)",
`business` VARCHAR(30) NOT NULL DEFAULT "" COMMENT "业务系统",
`service` VARCHAR(30) NOT NULL DEFAULT "" COMMENT "业务服务",
`host_ip` VARCHAR(20) NOT NULL DEFAULT "" COMMENT "主机 IP",
`level` VARCHAR(30) NOT NULL DEFAULT "" COMMENT "日志级别",
`logger_name` VARCHAR(256) NOT NULL DEFAULT "" COMMENT "日志名",
`message` VARCHAR(65532) NOT NULL DEFAULT "" COMMENT "日志信息",
`request_path` VARCHAR(256) NOT NULL DEFAULT "" COMMENT "请求URL",
`request_parameter` VARCHAR(65532) NOT NULL DEFAULT "" COMMENT "请求参数",
`request_method` VARCHAR(256) NOT NULL DEFAULT "" COMMENT "请求方式",
`request_header` VARCHAR(65532) NOT NULL DEFAULT "" COMMENT "请求头",
`response_content` VARCHAR(65532) NOT NULL DEFAULT "" COMMENT "响应内容",
`status_code` INT NOT NULL DEFAULT "200" COMMENT "状态码",
`request_response_time` INT NOT NULL DEFAULT "0" COMMENT "请求响应时长",
`exception` VARCHAR(65532) COMMENT "异常信息",
`log_time` DATETIME COMMENT "记录日志时的时间(年月日时分秒)",
INDEX idx_name_message(message) USING INVERTED PROPERTIES("parser" = "chinese") COMMENT '日志信息 倒排索引',
INDEX idx_name_exception(exception) USING INVERTED PROPERTIES("parser" = "english") COMMENT '异常信息 倒排索引'
) ENGINE = olap Duplicate KEY(`log_timestamp`)
DISTRIBUTED BY HASH(`log_timestamp`) BUCKETS 16 PROPERTIES("replication_num" = "1");表设计说明
- 使用明细 Duplicate 数据模型 且 指定了按照 log_timestamp + business 进行排序
- 根据 log_timestamp 列进行哈希分布。BUCKETS 16 表示将数据分布到 16 个桶中。
- 设置表属性(按默认)
- 设置分区(按默认)
- 增加倒排索引、以满足字符串类型的全文检索和普通数值/日期等类型的等值、范围检索,同时进一步优化倒排索引的查询性能、使其更加契合日志数据分析的场景需求。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









