







DeepSeek 的崛起凸显了成本效益、技术创新和地缘政治对人工智能格局的影响,但也引发了一些误解。这项研究为人工智能领导者澄清了一些关于 DeepSeek 模型的常见误解。
9个常见误解
本研究基于客户咨询和同行社区互动,对 Gartner 在 2025 年 1 月 28 日至 2 月 11 日期间提出的九个常见误解进行了澄清,并进行了总结:
-
所有DeepSeek 模型都会捕获您的数据并将其发送回中国。
-
DeepSeek 大大降低了 AI 模型开发的成本。
-
DeepSeek 大大降低了 AI 模型部署和推理的成本。
-
DeepSeek 的表现已经超越了 OpenAI。
-
只有 DeepSeek 模型受到了审查。
-
DeepSeek 受中国政府控制。
-
DeepSeek 使用 OpenAI 数据来训练其模型。
-
DeepSeek R1 有不同的尺寸。
-
DeepSeek 违反美国出口管制,非法获取高性能 Nvidia 芯片。
详细解释
图 1 中的神话矩阵代表了 Gartner 对每个 DeepSeek 神话的可信度的评估,以及如果每个神话都是真的,对 AI 领域的影响会有多大。
图 1:DeepSeek 神话矩阵
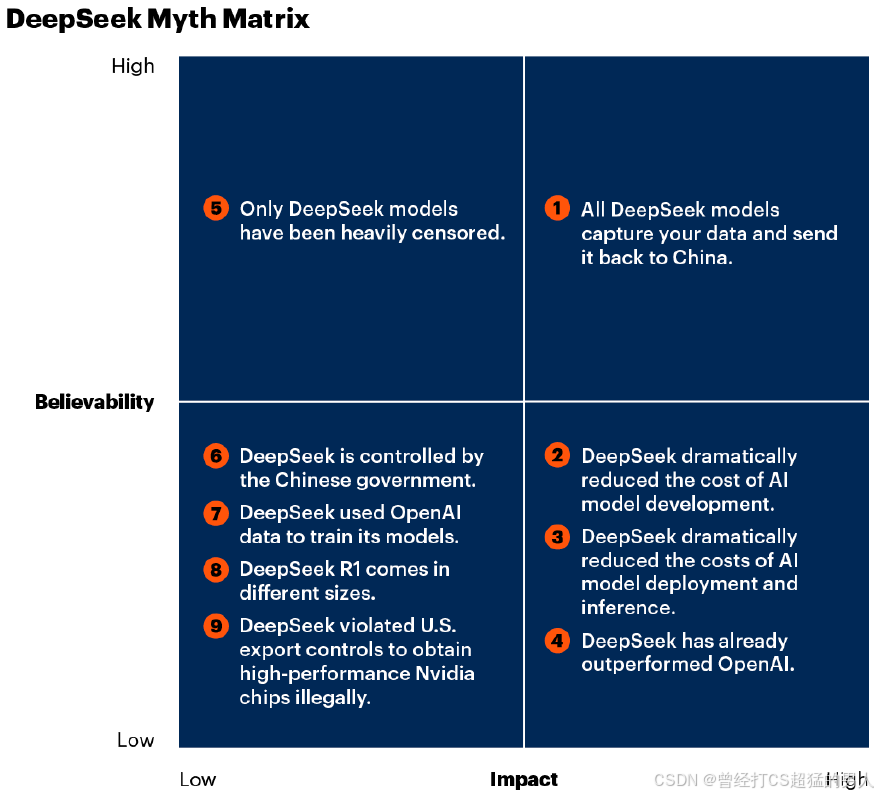
来源:Gartner
误解1:所有 DeepSeek 模型都会捕获您的数据并将其发送回中国。
事实:DeepSeek API 和应用程序收集您的数据并将其发送到中国,而 DeepSeek 模型并不执行此数据传输。
我们需要明确DeepSeek模型和应用程序之间的区别。
对于 DeepSeek 应用程序和 DeepSeek 公司托管的 DeepSeek API,DeepSeek 应用程序的隐私政策确实公开承认它收集各种用户数据,包括聊天记录、搜索查询、按键模式和 IP 地址。此外,它将数据存储在中国境内的服务器上。许多人工智能提供商,如 OpenAI 和 Perplexity,都有类似的数据收集政策,因此这并不是 DeepSeek 独有的。
然而,上述说法并不适用于其他云提供商托管的 DeepSeek 模型和 DeepSeek API。DeepSeek 模型(包括 V3 和 R1)是开放权重模型,可以部署到任何合适的基础设施。通过管理部署环境,组织可以根据自己的要求实施强大的安全措施。在本地托管模型可以简化对数据保护法规的遵守,例如欧盟的《通用数据保护条例》(GDPR)、美国《健康保险流通与责任法案》(HIPAA)或《加州消费者隐私法案》(CCPA)。
误解2:DeepSeek 大幅降低了 AI 模型开发成本。
事实:虽然 DeepSeek 降低了开发成本,但并没有从根本上改变 LLM 开发的经济性。
DeepSeek V3 模型的训练成本为 557 万美元。然而,DeepSeek 的成本效益方法并不能否定在人才、基础设施、数据处理和先前模型训练方面仍然需要的大量财务投入。大型语言模型 (LLM) 领域不断创新以提高效率。DeepSeek 就是这些创新的典范。DeepSeek 在“混合专家”(MoE)架构和 8 位和 32 位混合精度计算2等领域的新颖解决方案可在开发过程中减少计算资源消耗。
误解3:DeepSeek 大幅降低了AI 模型部署和推理的成本。
事实:尽管 DeepSeek 已成功减少模型推理过程中的资源消耗,但 DeepSeek 模型仍然需要高端基础设施和大量计算资源来部署。
DeepSeek R1 和 V3 模型拥有 6710 亿个参数,部署这些模型仍然需要高端基础设施和大量计算资源,尽管 DeepSeek 在模型推理过程中降低了计算资源消耗。
同时,DeepSeek 提炼了多种大小的 Qwen 和 Llama 模型。它们可以部署到任何合适的基础设施:云基础设施、数据中心、笔记本电脑。无需高级硬件(例如 H100 、H800)即可部署提炼后的模型。这些方法使计算资源有限的公司能够利用这些模型。
此外,DeepSeek 还有助于降低推理成本。很明显,DeepSeek 为 DeepSeek R1 API 3和 V3提供了比 OpenAI 的 o1 API 和 GPT4o 更显著的成本优势,使其成为希望优化 AI 相关费用的企业的理想选择。自 R1 发布以来,OpenAI 迅速推出了 o3-mini API 以匹配 R1 的价格。
误解4:DeepSeek 已经超越了 OpenAI。
事实:虽然 DeepSeek 展示了一种提高 LLM 性能的经济有效的方法,但 OpenAI 继续取得卓越的成果。
DeepSeek R1 的灵感来自 OpenAI o1。OpenAI于 2024 年 9 月预览了 o1,为 LLM 开发提供了一种新模式。OpenAI o1 模型通过为训练后和推理阶段分配额外的计算资源而脱颖而出。这种转变增强了模型的复杂推理能力。DeepSeek 复制了 o1 的表现,并通过在解决问题过程中明确分享其思路链,采用了更透明的方法。
V3 和 R1 模型只是展示了工程艺术和成本效益。DeepSeek 还推出了一种纯强化学习方法来优化模型,这种方法非常有效。但是 DeepSeek 并没有创造一种新的模型范式。
误解5:只有DeepSeek 模型受到了严格审查。
事实:所有模型均已受到审查。
大多数由领先提供商制作的 LLM(包括 DeepSeek V3、DeepSeek R1 和 Meta Llama 3 等开源模型,以及 OpenAI GPT4 和 Anthropic Claude 3 等专有模型)都经过了严格审查,旨在拒绝有害请求并遵守法规。作为一家中国公司,DeepSeek 受制于中国治理政策,为了遵守规定,它审查了一些信息和主题。有消融或微调等方法来规避审查;例如,Perplexity AI 通过将模型托管在美国服务器上来绕过 DeepSeek R1 中的审查,确保未经审查和私密的数据处理。
误解6:DeepSeek 受中国政府控制。
事实:没有公开记录表明 DeepSeek 得到了中国政府的支持。
DeepSeek于 2023 年作为量化对冲基金 High-Flyer 的一个副项目启动。这些资源随后被用于通过构建 DeepSeek 扩大基金对人工智能的关注。DeepSeek的资金来自 High-Flyer;没有风险投资或政府参与的证据。
DeepSeek 于 2024 年 5 月开始受到关注,当时 DeepSeek 推出了 V2 模型,价格仅为 GPT-4 Turbo 的 1.3%。这引发了一场 LLM 价格战。DeepSeek 默默地进行技术创新,直到 2025 年 1 月推出 R1。DeepSeek已成为中国技术进步的灯塔。在美国加大力度遏制中国 AI 进步的背景下,该公司未来获得国家支持将变得轻而易举。
误解 7.DeepSeek 使用 OpenAI 数据来训练其模型。
事实:他们是否使用 OpenAI 数据并不重要,但数据已经成为模型性能的关键区别因素。
数据已成为模型性能的关键差异因素,因为创新算法易于复制,计算资源随时可用。DeepSeek尚未披露其数据来源。它描述了使用创新算法和高效消耗计算资源对R1和 V3 模型进行训练的方法,但没有详细提及训练数据。DeepSeek 表示,它通过提高数学和编程样本的比例来优化预训练语料库,同时将多语言覆盖范围扩展到英语和中文之外。
OpenAI 指责 DeepSeek 违反使用条款,将 OpenAI LLM 的输出用作 DeepSeek R1 模型蒸馏过程的一部分。蒸馏涉及训练较小的 AI 模型,以利用其输出来模仿较大的预训练模型的功能。然而,蒸馏是训练 LLM 的常用方法,DeepSeek 已使用蒸馏基于其他开放模型(例如 Meta Llama 和 Alibaba Qwen)创建新模型。在线社区中越来越多的人认为,DeepSeek 的成功很大程度上可能归功于它在预训练阶段加入了中文。
误解8:DeepSeek R1 有不同的大小。
事实:R1 只有一种大小。其他蒸馏模型不是 DeepSeek 模型。
R1和V3模型都只有一种大小,DeepSeek R1模型是基于其V3模型训练的,参数量高达6710亿。但企业可以利用DeepSeek-R1产生的推理数据,对研究社区广泛使用的几种开放权重模型进行微调,这种技术就是所谓的蒸馏。DeepSeek还基于Qwen2.5和Llama3系列向社区蒸馏了6个更小的模型(15亿、70亿、80亿、140亿、320亿和700亿)。这些更小的模型使用的是Qwen和Llama的模型架构,而非DeepSeek R1的模型架构。
资源有限的组织可以使用提炼后的模型,但其性能可能不如 R1 模型。
误解9:DeepSeek 违反美国出口管制,非法获取高性能 Nvidia 芯片。
事实:DeepSeek 在机遇中进行了创新。没有证据表明 DeepSeek 在其模型训练过程中利用了高端 GPU。
DeepSeek 表示,它使用了 2,048 块 H800 GPU 来训练其V3模型。DeepSeek-V3 的经济训练成本是通过其对算法、框架和硬件的优化协同设计实现的。
DeepSeek不断创新新的技术解决方案以克服内存带宽不足的问题,包括在 PTX 而不是 CUDA 上编程。所有token 消耗和计算资源容量的计算都与 H800 性能统计数据保持一致。DeepSeek 在 V3 设计中做出的所有决定只有在您受限于 H800 时才有意义。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









