






1.Linux系统上安装Mongodb
- 在usr/local文件夹下创建mongo文件夹
- 下载mongodb包
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-6.0.5.tgz
- 解压mongodb
tar -zxvf mongodb-linux-x86_64-rhel70-6.0.5.tgz
- 更改文件夹的名字
mv mongodb-linux-x86_64-rhel70-6.0.5 mongodb-6.0.5

- 进入mongodb-6.0.5 文件夹
cd mongodb-6.0.5
- 创建data、log、conf文件夹
mkdir data
mkdir log
mkdir conf

- 启动mongodb服务
bin/mongod --port=27017 --dbpath=/usr/local/mongo/mongodb-6.0.5/data --logpath=/usr/local/mongo/mongodb-6.0.5/log/mongodb.log \--bind_ip=0.0.0.0 --fork
- 配置环境变量(修改配置文件etc/profile)
export MONGODB_HOME=/usr/local/mongo/mongodb-6.0.5
PATH=$PATH:$MONGODB_HOME/bin
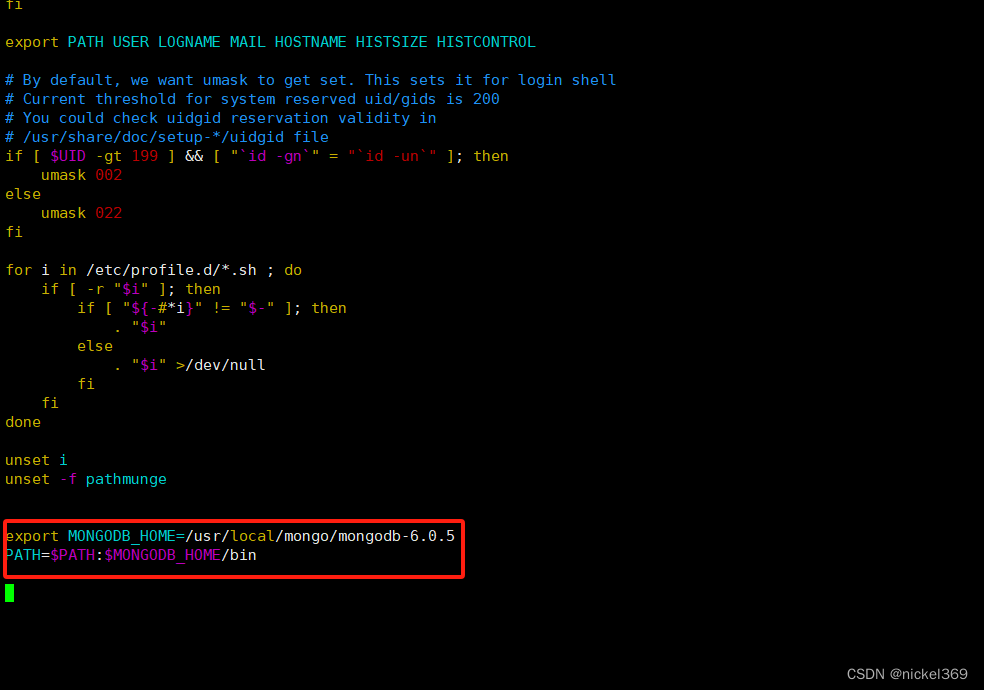
- 在conf文件夹下面创建mongo.conf配置文件
cd conf
vim mongo.conf
配置文件的内容为
systemLog:
destination: file
path: /usr/local/mongo/mongodb-6.0.5/log/mongod.log
logAppend: true
storage:
dbPath: /usr/local/mongo/mongodb-6.0.5/data
engine: wiredTiger #存储引擎
journal:
enabled: true
net:
bindIp: 0.0.0.0
port: 27017
processManagement:
fork: true
- 启动和关闭mongodb
#启动mongodb
mongod -f /usr/local/mongo/mongodb-6.0.5/conf/mongo.conf
#关闭mongodb
mongod --port=27017 --dbpath=/usr/local/mongo/mongodb-6.0.5/data --shutdown
- mongosh使用
#centos7 安装
mongosh wget https://downloads.mongodb.com/compass/mongodb-mongosh-1.8.0.x86_64.rpm
yum install -y mongodb-mongosh-1.8.0.x86_64.rpm
# 连接mongodb server端
mongosh --host=192.168.2.66 --port=27017
mongosh 192.168.2.66:27017
# 指定uri方式连接
mongosh mongodb://192.168.2.66:27017/test
2.Mongodbd的使用
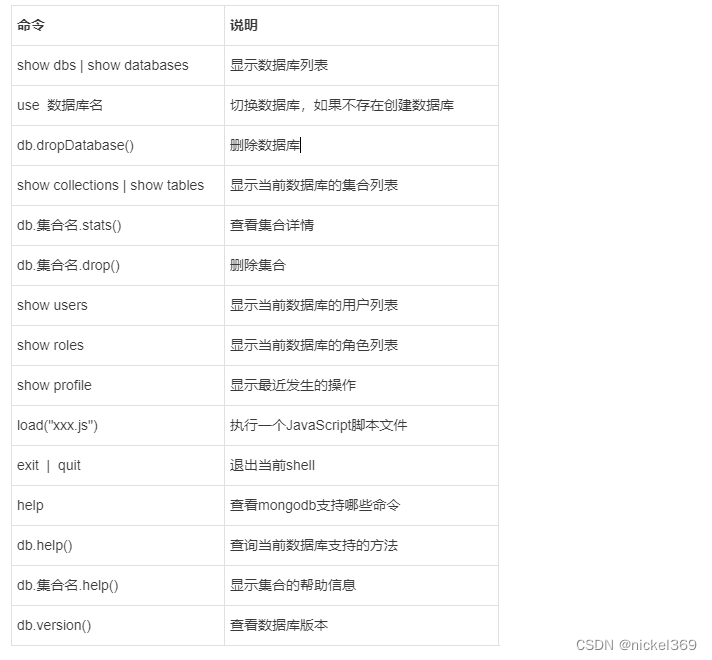
2.1 常见命令
1.数据集操作
#查看所有数据库
show dbs
#切换到指定数据库,不存在则创建
use users
#删除当前数据库
db.dropDatabase()

2.集合操作
# 查看集合
show collections
#创建集合
db.createCollection("emp")
#删除集合
db.emp.drop()

3.安全认证
1.创建管理员用户
#设置管理员用户名需要切换到admin
use admin
#创建管理员
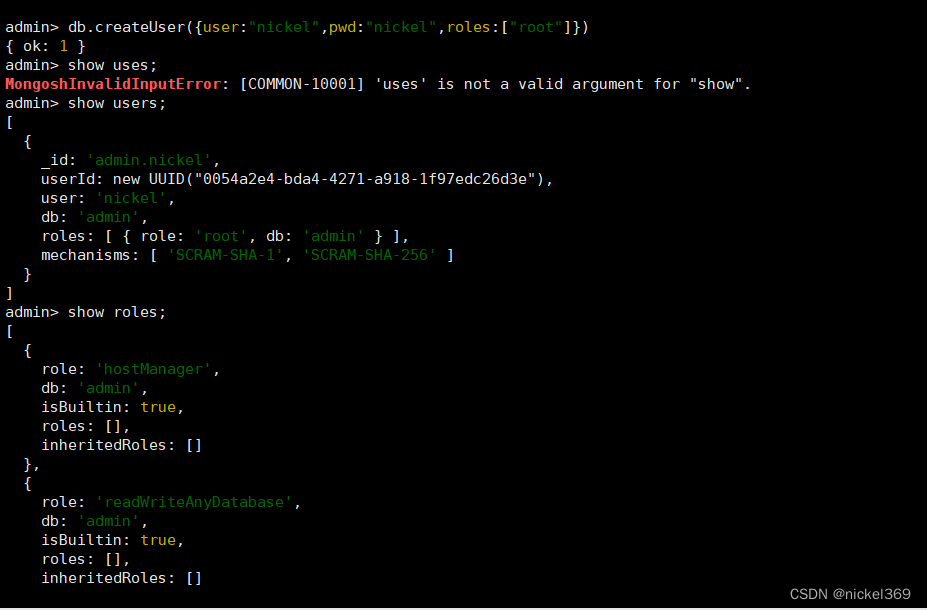
db.createUser({user:"fox",pwd:"fox",roles:["root"]})
#查看当前数据库所有用户信息
show users
#显示可设置权限
show roles
#显示所用用户
db.system.users.find()
2 重新赋予用户操作权限

#创建用户
db.createUser({user:"fox",pwd:"fox",roles:["root"]})
#重新赋予用户相关权限
db.grantRolesToUser("fox",[{role:"clusterAdmin",db:"admin"},{role:"userAdminAnyDatabase",db:"admin"},{role:"readWriteAnyDatabase",db:"admin"}])
3 删除某个用户
#进入权限库
use admin
#删除某个用户
db.dropUser("fox")
#删除当前所有用户
db.dropAllUser()


4 创建应用数据库用户
use appdb
db.createUser({user:"appdb",pwd:"nickel",roles:["dbOwner"]})
5 MongoDb启用鉴权
#启用鉴权
mongod -f /usr/local/mongo/mongodb-6.0.5/conf/mongo.conf --aut
#登录数据库
mongosh 192.168.2.66 -u nickel -p nickel --authenticationDatabase=admin
4.Docker安装Mongodb
#拉取mongo镜像
docker pull mongo:6.0.5
#运行mongo镜像
docker run --name mongo-server -p 29017:27017 \
-e MONGO_INITDB_ROOT_USERNAME=fox \
-e MONGO_INITDB_ROOT_PASSWORD=fox \
-d mongo:6.0.5 --wiredTigerCacheSizeGB 1
5.远程连接mongodb
mongosh ip:29017 -u nickel -p nickel
6.远程连接mongodb常见工具
一.MongoDB常用工具
1.GUI工具
官方GUI:COMPASS
MongoDB图形化管理工具(GUI),能够帮助您在不需要知道MongoDB查询语法的前提下,便利地分析和理解您的数据库模式,并且帮助您可视化地构建查询。
下载地址:https://www.mongodb.com/zh-cn/products/compass
2.Robo 3T(免费)*
下载地址:https://robomongo.org/
3.Studio 3T(收费,试用30天)
下载地址:https://studio3t.com/download/
*4.MongoDB Database Tools
下载地址:https://www.mongodb.com/try/download/database-tools
文件名称作用mongostat数据库性能监控工具mongotop热点表监控工具mongodump数据库逻辑备份工具mongorestore数据库逻辑恢复工具mongoexport数据导出工具mongoimport数据导入工具bsondumpBSON格式转换工具mongofilesGridFS文件工具
7.mongodb基本命令
1.单条插入命令
db.emps.insertOne({name:'fox',age:35})

2.多条插入命令
db.emps.insertMany([{name:'小明',age:5},{name:'小红',age:10}])
3.执行js脚本
- 直接执行下面脚本
var tags=["nosql","mongodb","document","developer","popular"];
var types=["technology","sociality","travel","novel","literature"];
var books=[];
for(var i=0;i<50;i++){
var typeIdx=Math.floor(Math.random()*types.length);
var tagIdx=Math.floor(Math.random()*tags.length);
var favCount=Math.floor(Math.random()*100);
var book={
title:"book-"+i,
type:types[typeIdx],
tag:tags[tagIdx],
favCount:favCount,
author:"xxx"+i
};
books.push(book)
}
db.books.insertMany(books);
- 创建books.js文件执行
1.创建一个file文件夹,在文件夹中创建books.js文件,在把上面语句访问js文件中
#创建文件夹
mkdir file
#进入文件夹
cd file
#创建books.js文件
vim books.js
#连接mongodb数据库
mongosh -u nickel -p nickel
#切换到相关的库
use books
#执行js文件
load("books.js")



4.查询方法



#单条查询
db.books.findOne()
#多条查询
db.books.find()
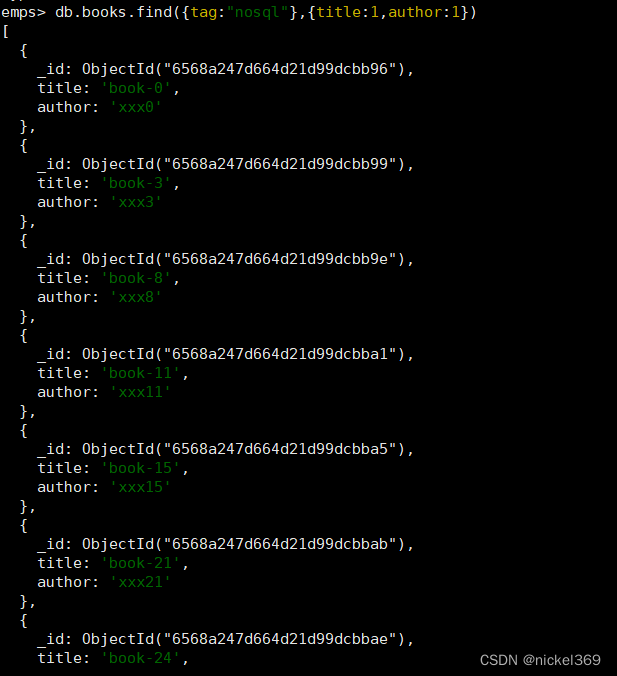
#条件查询(查询tag=nosql 只显现title和author两个字段,其余默认)
db.books.find({tag:"nosql"},{title:1,author:1})
#条件查询(tag=nosql 只显现title和author两个字段,其余不显示)
db.books.find({tag:"nosql"},{_id:0,title:1,author:1})
#条件查询(按照ID查询一条数据)
db.books.find({_id:ObjectId("6568a247d664d21d99dcbbbe")})
#条件查询(type=travel和favCount>60)
db.books.find({type:'travel',favCount:{$gt:60}})
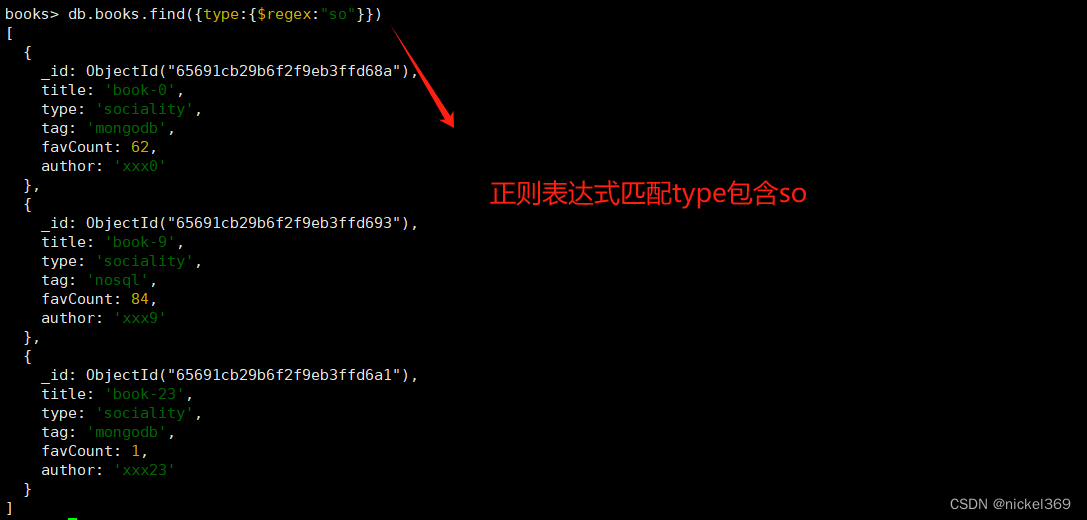
#查询条件中使用正则表达式(type中包含so的数据)
#方式1
db.books.find({type:{$regex:"so"}})
#方式2
db.books.find({type:/so/})




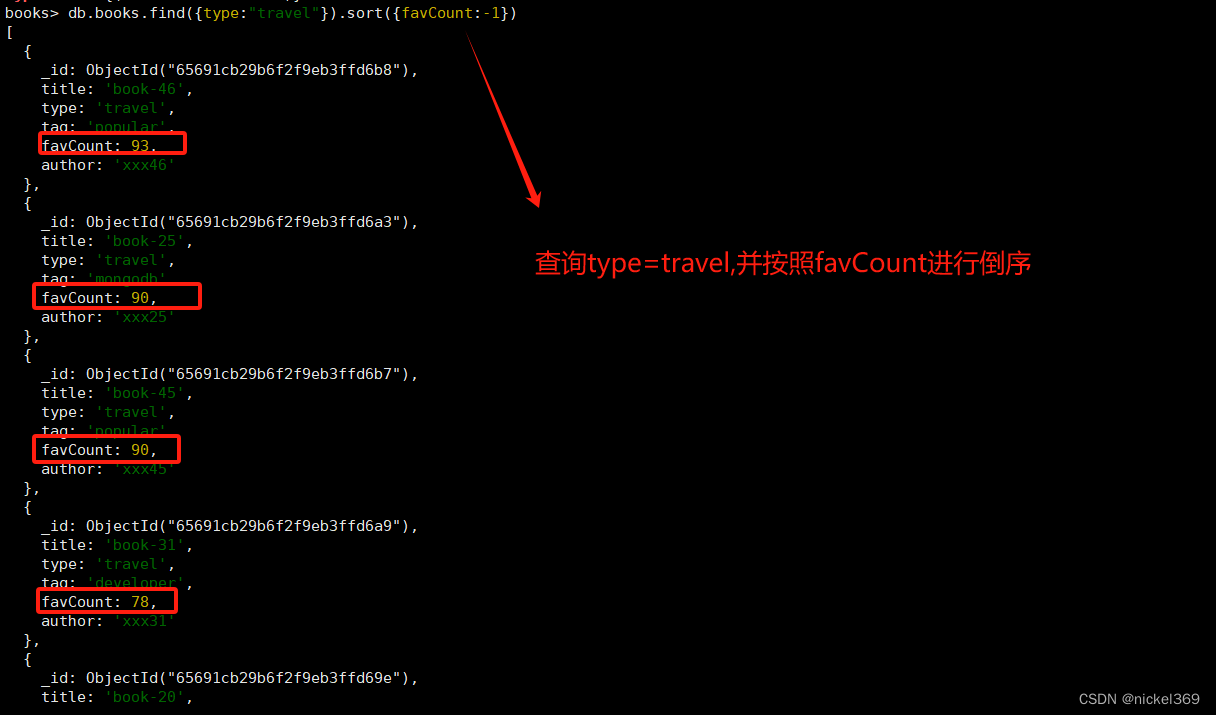
5.排序方法
#按照favCount进行倒序(type="travel")
db.books.find({type:"travel"}).sort({favCount:-1})
#按照favCount进行正序(type="travel")
db.books.find({type:"travel"}).sort({favCount:1})

6.分页
#查询16条记录后三条记录
db.books.find().skip(16).limit(3)
#查询第一页的数据
db.books.find({}).sort({_id:1}).limit(10)
#查询第二页的数据
#db.books.find({_id: {$gt: <第一页最后一个_id>}}).sort({_id: 1}).limit(10);
db.books.find({_id:{$gt:ObjectId("65691cb29b6f2f9eb3ffd693")}}).sort({_id:1}).limit(10)
#查询第三页的数据
#db.books.find({_id: {$gt: <第二页最后一个_id>}}).sort({_id: 1}).limit(10)
db.books.find({_id:{$gt:ObjectId("65691cb29b6f2f9eb3ffd69d")}}).sort({_id:1}).limit(10)



说明:处理分页问题 – 避免使用 count
db.coll.find({x: 100}).limit(50);
db.coll.count({x: 100});
- 前者只需要遍历前 n 条,直到找到 50 条 x=100 的文档即可结束;
- 后者需要遍历完 1000w 条找到所有符合要求的文档才能得到结果。 为了计算总页数而进行的 count() 往往是拖慢页面整体加载速度的原因
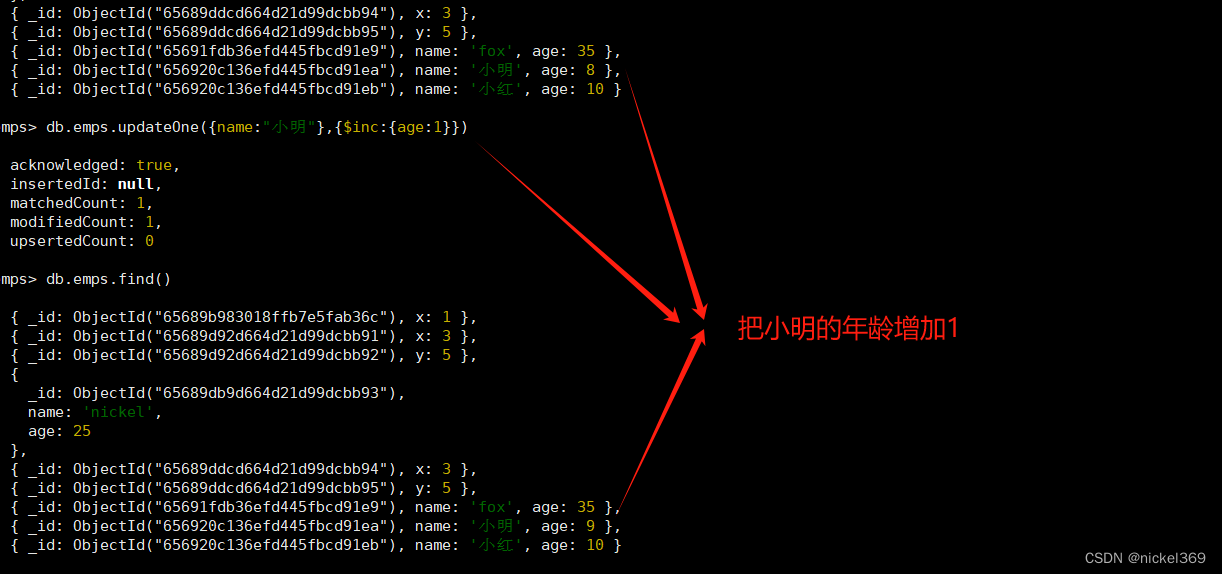
7.更新文档

#修改数据(name=小明 age从5修改为8)
db.emps.updateOne({name:"小明"},{$set:{age:8}})
#修改数据(name=小明 把age增加为1)
db.emps.updateOne({name:"小明"},{$inc:{age:1}})
#更改列名(name=小明 把name改为name1)
db.emps.updateOne({name:"小明"},{$rename:{"name":"name1"}})
#增加列名(增加sex列名,默认为1)
db.emps.updateMany({},{$unset:{"sex":1}})
#删除列名(删除sex列名)
db.emps.updateMany({},{$unset:{"sex":1}})
#不存在则插入(插入title=my book)
db.books.updateOne({title:"my book"},{$set:{tags:["nodql","mongodb"],type:"none",author:"fox"}},{upsert:true})
#更新多条数据(更新type="novel",增加publishedDate字段)
db.books.updateMany({type:"novel"},{$set:{publishedDate:new Date()}})
#查询数据并修改数据,显示的数据是修改之前的数据
db.books.findAndModify({
query:{_id:ObjectId("65691cb29b6f2f9eb3ffd6ac")},
update:{$inc:{favCount:1}}
})
#查询数据并修改数据,显示的数据是修改之后的数据
db.books.findAndModify({
query:{_id:ObjectId("65691cb29b6f2f9eb3ffd6ac")},
update:{$inc:{favCount:1}},
new:true
})








8.删除文档
#删除满足条件((type=novel))的id最小的数据
db.books.deleteOne({type:"novel"})
#删除集合下的全部文档
db.books.deleteMany({})
#删除满足条件((type=novel))所有数据
db.books.deleteMany({type:"novel"})
#删除满足条件((type=novel))一条数据,并显示该条删除的数据
db.books.findOneAndDelete({type:"novel"})
#按照favCount正序之后,然后删除第一条数据
db.books.findOneAndDelete({type:"novel"},{sort:{favCount:1}})


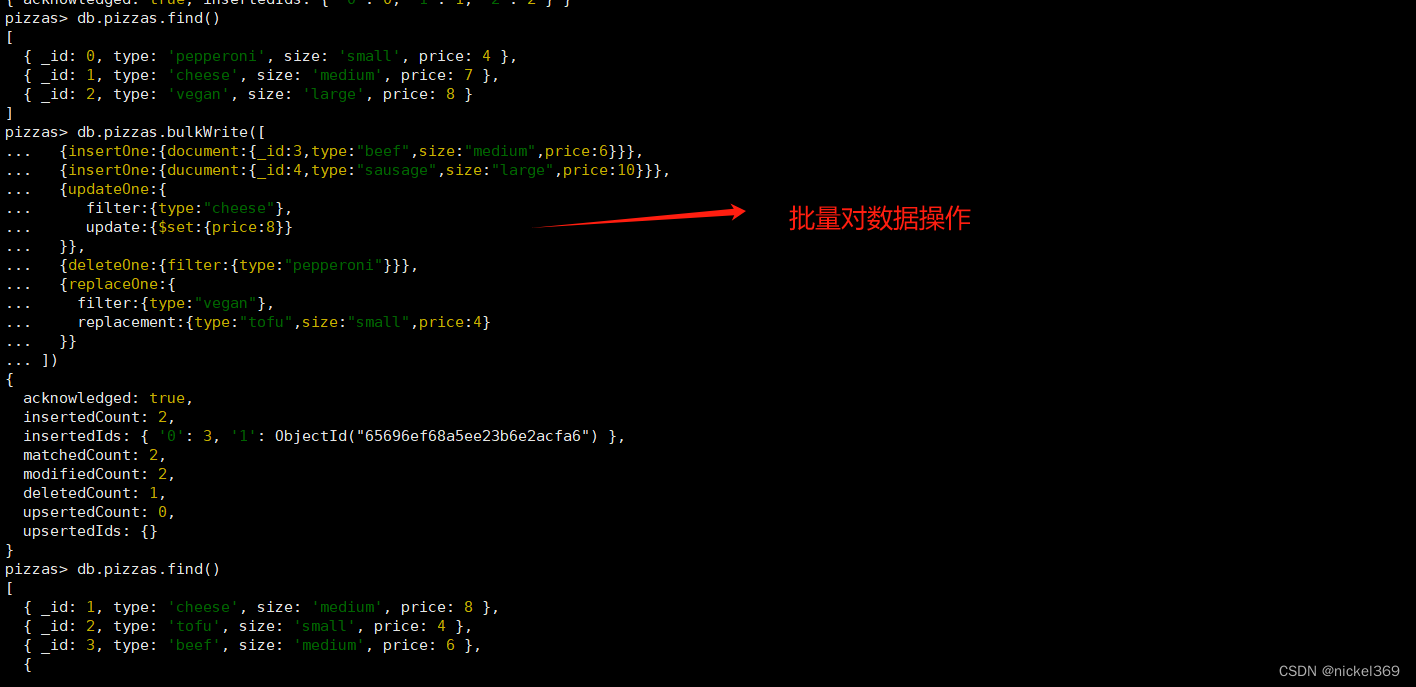
9.批量操作数据(bulkwrite())
#批量插入数据
db.pizzas.insertMany( [
{ _id: 0, type: "pepperoni", size: "small", price: 4 },
{ _id: 1, type: "cheese", size: "medium", price: 7 },
{ _id: 2, type: "vegan", size: "large", price: 8 }
] )
#批量操作数据
db.pizzas.bulkWrite([
{insertOne:{document:{_id:3,type:"beef",size:"medium",price:6}}},
{insertOne:{ducument:{_id:4,type:"sausage",size:"large",price:10}}},
{updateOne:{
filter:{type:"cheese"},
update:{$set:{price:8}}
}},
{deleteOne:{filter:{type:"pepperoni"}}},
{replaceOne:{
filter:{type:"vegan"},
replacement:{type:"tofu",size:"small",price:4}
}}
])

10.日期类型
#插入时间格式
db.dates.insertMany([
{data1:Date()},{data2:new Date()},{data3:ISODate()}
])

11.内嵌文档
#插入嵌套文档
db.books.insert({
title:"我们的爱情故事",
author:{
name:"Nickel",
gender:"男",
hometown:"重庆"
}
})
#按照嵌套文档的内容进行查找
db.books.find({"author.name":"Nickel"})
#修改嵌套文档中name=Nickel的hometownm名称
db.books.updateOne({"author.name":"Nickel"},{$set:{"author.hometown":"重庆/贵州"}})
#增加tags标签字段
db.books.updateOne({"author.name":"Nickel"},{$set:{"tags:["履行","随笔","散文","爱情","文学"]"}})
#在tags标签里面追加单个标签
db.books.updateOne({"author.name":"Nickel"},{$push:{tags:"猎奇"}})
#在tags标签里面追加多个标签
db.books.updateOne({"author.name":"Nickel"},{$push:{tags:{$each:["伤感","想象力"]}}})
#在tags标签里面追加多个标签,然后截取后面三个标签
db.books.updateOne({"author.name":"Nickel"},{$push:{tags:{$each:["伤感","想象力"],$slice:-3}}})





嵌套数组的运用
#嵌套数组的运用
db.goods.insertMany([
{
name:"羽绒服",
tags:[
{tagKey:"size",tagValue:["M","L","XL","XXL","XXXL"]},
{tagKey:"color",tagValue:["黑色","宝蓝"]},
{tagKey:"style",tagValue:"韩风"},
]
},
{
name:"羊毛衫",
tags:[
{tagKey:"size",tagValue:["L","XL","XXL"]},
{tagKey:"color",tagValue:["蓝色","否色"]},
{tagKey:"style",tagValue:"韩风"},
]
}
])


筛选出黑色的数据
#筛选出黑色的数据
db.goods.find({
tags:{$elemMatch:{tagKey:"color",tagValue:"黑色"}}
})

筛选出color=蓝色,并且size=XL的商品
#筛选出color=蓝色,并且size=XL的商品
db.goods.find({
tags:{
$all:[
{$elemMatch:{tagKey:"color",tagValue:"黑色"}},
{$elemMatch:{tagKey:"size",tagValue:"XL"}}
]
}
})

12.固定(封顶)集合
固定集合(capped collection)是一种限定大小的集合,其中capped是覆盖、限额的意思。跟普通的集合相比,数据在写入这种集合时遵循FIFO原则。可以将这种集合想象为一个环状的队列,新文档在写入时会被插入队列的末尾,如果队列已满,那么之前的文档就会被新写入的文档所覆盖。通过固定集合的大小,我们可以保证数据库只会存储“限额”的数据,超过该限额的旧数据都会被丢弃。
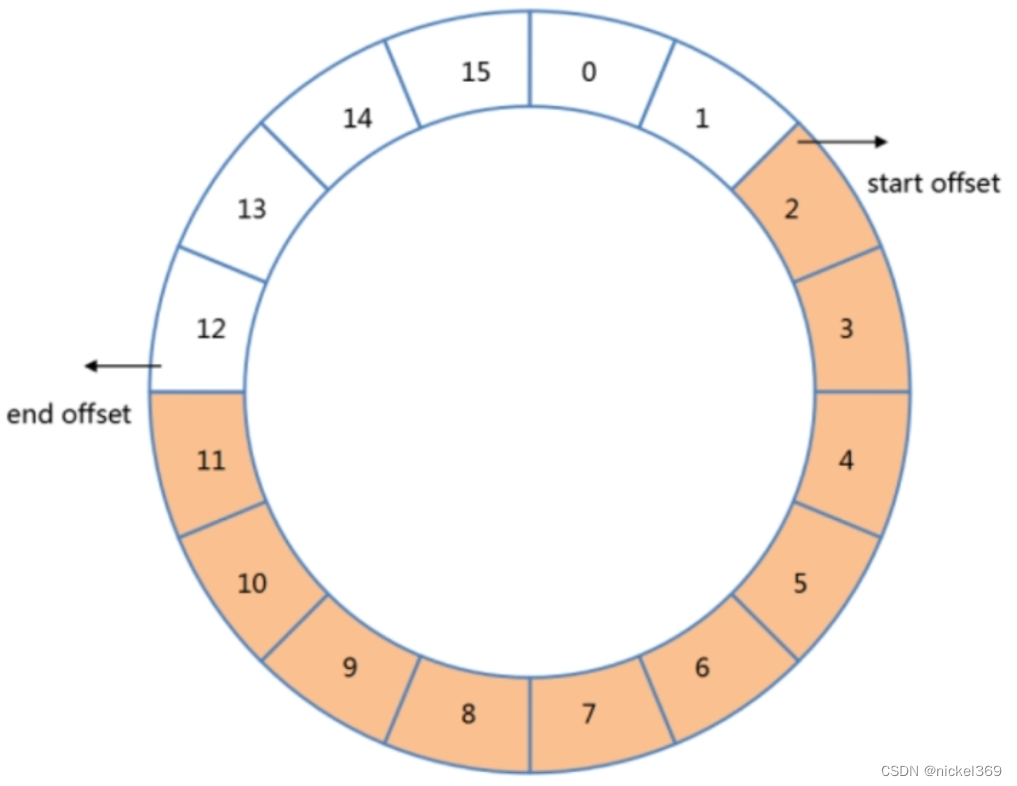
db.createCollection(“logs”,{capped:true,size:4096,max:10})
- capped:是否是固定集合
- max:指集合的文档数量最大值,这里是10条
- size:指集合的空间占用最大值,这里是4096字节(4KB)
这两个参数会同时对集合的上限产生影响。也就是说,只要任一条件达到阈值都会认为集合已经写满。其中size是必选的,而max则是可选的。
可以使用collection.stats命令查看文档的占用空间
#创建固定集合
db.createCollection("logs",{capped:true,size:4096,max:10})
#将普通集合转化为固定集合
db.runCommand({"convertToCapped": "mycoll", size: 100000})
#参事向集合中插入数据,查看是否覆盖
for(var i=5;i<15;i++){
db.logs.insert({t:"row"+i})
}

适用场景
&emsp固定集合很适合用来存储一些“临时态”的数据。“临时态”意味着数据在一定程度上可以被丢弃。同时,用户还应该更关注最新的数据,随着时间的推移,数据的重要性逐渐降低,直至被淘汰处理。
一些适用的场景如下:
- 系统日志,这非常符合固定集合的特征,而日志系统通常也只需要一个固定的空间来存放日志。在MongoDB内部,副本集的同步日志(oplog)就使用了固定集合。
- 存储少量文档,如最新发布的TopN条文章信息。得益于内部缓存的作用,对于这种少量文档的查询是非常高效的。
股票监听案例
- 创建stock_queue消息队列,其可以容纳10MB的数据
db.createCollection("gupiao_queue",{capped:true,size:10485760})
- 为了能支持按时间条件进行快速的检索,比如查询某个时间点之后的数据,可以为timestamp添加索引
db.gupiao_queue.createIndex({timestamped:1})
- 构建生产者,发布股票动态,并执行生产者
function pushEvent(){
while(true){
db.gupiao_queue.insert({
timestamped:new Date(),
stock: "MongoDB Inc",
price: 100*Math.random(1000)
});
print("publish stock changed");
sleep(1000);
}
}
pushEvent()
- 构建消费者,监听股票动态,并执行消费者
function listen(){
var cursor = db.gupiao_queue.find({timestamped:{$gte:new Date()}}).tailable();
while(true){
if(cursor.hasNext()){
print(JSON.stringify(cursor.next(),null,2));
}
sleep(1000);
}
}
listen()
效果展示


2.2 聚合操作
聚合操作: 允许用户处理多个文档并返回计算结果。聚合操作组值来自多个文档,可以对分组数据执行各种操作以返回单个结果。
聚合操作包含三类:单一作用聚合、聚合管道、MapReduce。
- 单一作用聚合:提供了对常见聚合过程的简单访问,操作都从单个集合聚合文档。MongoDB提供 db.collection.estimatedDocumentCount(), db.collection.countDocument(), db.collection.distinct() 这类单一作用的聚合函数。 所有这些操作都聚合来自单个集合的文档。虽然这些操作提供了对公共聚合过程的简单访问,但它们缺乏聚合管道和map-Reduce的灵活性和功能。
- 聚合管道是一个数据聚合的框架,模型基于数据处理流水线的概念。文档进入多级管道,将文档转换为聚合结果。
- MapReduce操作具有两个阶段:处理每个文档并向每个输入文档发射一个或多个对象的map阶段,以及reduce组合map操作的输出阶段。从MongoDB 5.0开始,map-reduce操作已被弃用。聚合管道比映射-reduce操作提供更好的性能和可用性。
MongoDB 6.0在原有聚合功能的基础上,推出了如下新特性以及优化项: - 分片集群实例支持 l o o k u p 和 lookup和 lookup和graphLookup。
- 改进$lookup对JOINS的支持。
- 改进$graphLookup对图遍历的支持。
- 提升$lookup性能,部分场景中性能提升可达百倍。
1.聚合管道
MongoDB 聚合框架(Aggregation Framework)是一个计算框架,它可以:
- 作用在一个或几个集合上;
- 对集合中的数据进行的一系列运算;
- 将这些数据转化为期望的形式;
管道(Pipeline)和阶段(Stage)
整个聚合运算过程称为管道(Pipeline),它是由多个阶段(Stage)组成的, 每个管道: - 接受一系列文档(原始数据);
- 每个阶段对这些文档进行一系列运算;
- 结果文档输出给下一个阶段;
常用的聚合阶段运算符

准备数据集,执行脚本
var tags = ["nosql","mongodb","document","developer","popular"];
var types = ["technology","sociality","travel","novel","literature"];
var books=[];
for(var i=0;i<50;i++){
var typeIdx = Math.floor(Math.random()*types.length);
var tagIdx = Math.floor(Math.random()*tags.length);
var tagIdx2 = Math.floor(Math.random()*tags.length);
var favCount = Math.floor(Math.random()*100);
var username = "xx00"+Math.floor(Math.random()*10);
var age = 20 + Math.floor(Math.random()*15);
var book = {
title: "book-"+i,
type: types[typeIdx],
tag: [tags[tagIdx],tags[tagIdx2]],
favCount: favCount,
author: {name:username,age:age}
};
books.push(book)
}
db.books.insertMany(books);
①$project 投影操作, 将原始字段投影成指定名称(相当与mysql里面的as)
#把title字段投影到name字段上面
db.books.aggregate([{$project:{name:"$title"}}])

说明:这里_id是默认显示的
#title投影显示,不显示_id,显示type、author字段
db.books.aggregate([{$project:{name:"$title",_id:0,type:1,author:1}}])
#title投影显示,不显示_id,显示type和author下面name
db.books.aggregate([{$project:{name:"$title",_id:0,type:1,"author.name":1}}])
#或者
db.books.aggregate([{$project:{name:"$title",_id:0,type:1,author:{name:1}}}])



②$match按照条件进行筛选数据(相当于mysql中where条件)
#匹配type=technology的数据
db.books.aggregate([{$match:{type:"technology"}}])
#匹配type=technology的数据,并且title投影显示,不显示_id,显示type和author下面name
db.books.aggregate([
{$match:{type:"technology"}},
{$project:{name:"$title",_id:0,type:1,author:{name:1}}}
])


③$count获取数据条数(相当于mysql中count(*))
匹配type=technology的数据,获取满足条件的数量
db.books.aggregate([
{$match:{type:"technology"}},
{$count:"type_count"}
])

④$group 按照条件进行分组(相当于mysql里面group by)
汇总数据条数,favCount的总和和平均值
db.books.aggregate([{$group:{_id:null,count:{$sum:1},pop:{$sum:"$favCount"},avg:{$avg:"$favCount"}}}])

获取每个作者收藏件数
db.books.aggregate([{$group:{_id:"$author.name",pop:{$sum:"$favCount"}}}])

获取每个作者每本book收藏件数
db.books.aggregate([{
$group:{
_id:{name:"$author.name",title:"$title"},
pop:{$sum:"$favCount"}
}
}])

每个作者的book的type合集
db.books.aggregate([{
$group:{
_id:"$author.name",
type:{$addToSet:"$type"}
}
}])

⑤$unwind 将数组拆分成单独的文档
**匹配name=xx006数据,然后把tag拆分为单个的数据 **
db.books.aggregate([
{$match:{"author.name":"xx006"}},
{$unwind:"$tag"}
])

每个作者的book的tag合集
db.books.aggregate([
{$unwind:"$tag"},
{$group:{_id:"$author.name",types:{$addToSet:"$tag"}}}
])

插入数据
db.books.insert([
{
"title" : "book-51",
"type" : "technology",
"favCount" : 11,
"tag":[],
"author" : {
"name" : "fox",
"age" : 28
}
},{
"title" : "book-52",
"type" : "technology",
"favCount" : 15,
"author" : {
"name" : "fox",
"age" : 28
}
},{
"title" : "book-53",
"type" : "technology",
"tag" : [
"nosql",
"document"
],
"favCount" : 20,
"author" : {
"name" : "fox",
"age" : 28
}
}])
** 使用includeArrayIndex选项来输出数组元素的数组索引**
db.books.aggregate([
{$match:{"author.name":"fox"}},
{$unwind:{path:"$tag",includeArrayIndex:"arrayIndex"}}
])

使用preserveNullAndEmptyArrays选项在输出中包含缺少size字段,null或空数组的文档
db.books.aggregate([
{$match:{"author.name":"fox"}},
{$unwind:{path:"$tag",preserveNullAndEmptyArrays:true}}
])
⑥$limit 限制传递到管道中下一阶段的文档数
限制传递到管道中的数量为3
db.books.aggregate([{$limit:3}])

⑦$skip 跳过进入stage的指定数量的文档,并将其余文档传递到管道中的下一个阶段
db.books.aggregate([{$skip:3}])
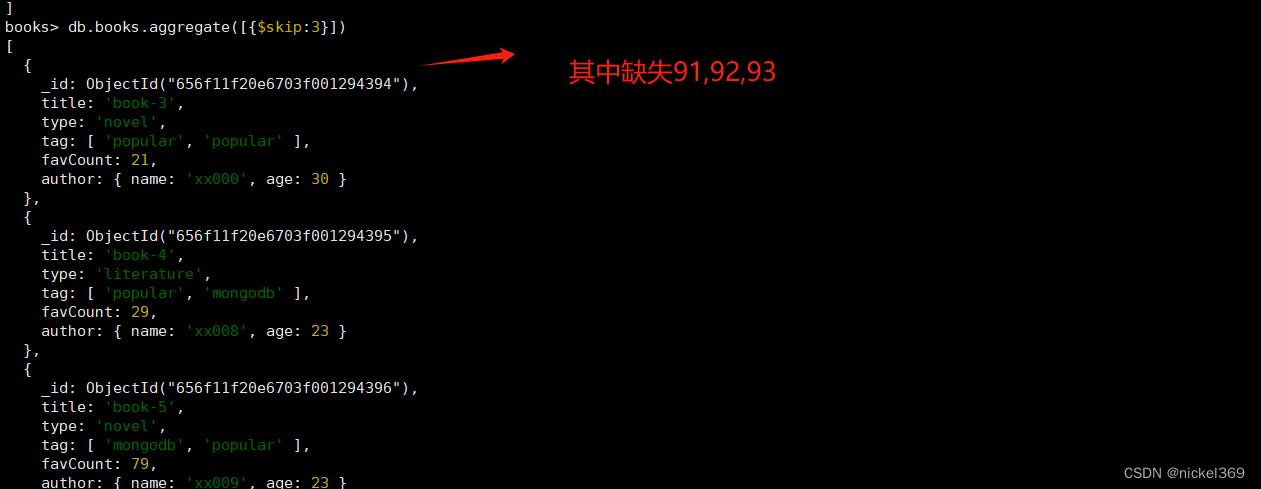
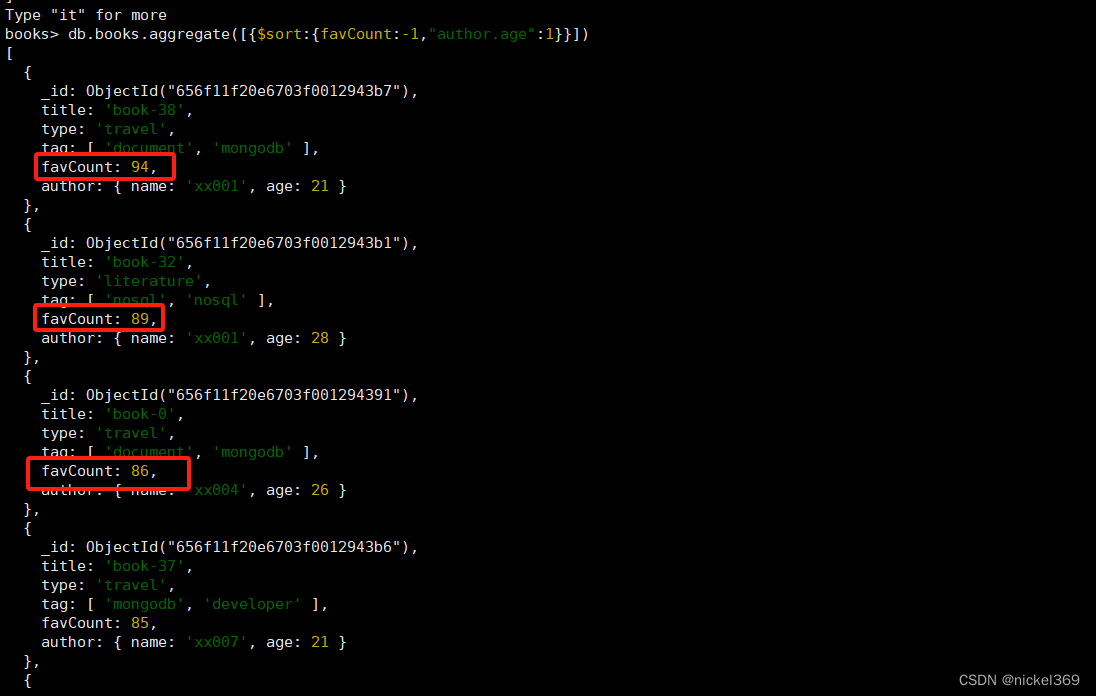
⑧$sort 对所有输入文档进行排序,并按排序顺序将它们返回到管道。
先按favCount进行升序,在按照作者年龄降序
db.books.aggregate([{$sort:{favCount:-1,"author.age":1}}])
⑨$lookup Mongodb 3.2版本新增,主要用来实现多表关联查询, 相当关系型数据库中多表关联查询
db.collection.aggregate([{
$lookup: {
from: "<collection to join>",
localField: "<field from the input documents>",
foreignField: "<field from the documents of the from collection>",
as: "<output array field>"
}
})

其语法功能类似于下面的伪SQL语句:
SELECT *, <output array field>
FROM collection
WHERE <output array field> IN (SELECT *
FROM <collection to join>
WHERE <foreignField>= <collection.localField>);
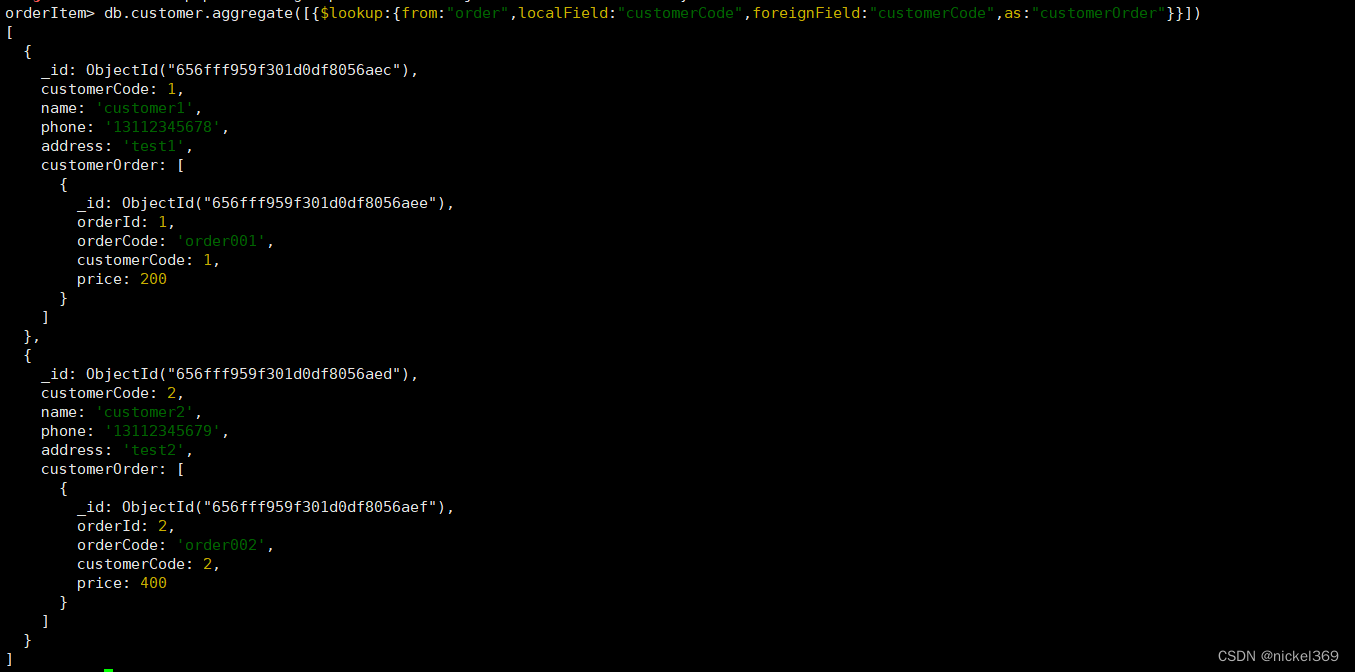
关联查询customer和order表
db.customer.aggregate([
{$lookup: {
from:"order",
localField:"customerCode",
foreignField:"customerCode",
as:"customerOrder"}
}
])
关联查询customer和order、orderItem表
db.order.aggregate([
{$lookup:{
from:"customer",
localField:"customerCode",
foreignField:"customerCode",
as:"customer"
}},
{$lookup:{
from:"orderItem",
localField:"orderId",
foreignField:"orderId",
as:"orderItem"
}}
])
 聚合操作案例1
聚合操作案例1
一、统计每个分类的book文档数量
db.books.aggregate([
{$group:{_id:"$type",total:{$sum:1}}},
{$sort:{total:-1}}
])

二、标签的热度排行,标签的热度则按其关联book文档的收藏数(favCount)来计算
db.books.aggregate([
{
$match: {
favCount: {
$gt: 0,
},
},
},
{
$unwind: "$tag",
},
{
$group: {
_id: "$tag",
total: {
$sum: "$favCount",
},
},
},
{$sort:{total:-1}}
])

- 1.$match阶段:用于过滤favCount=0的文档。
- 2.$unwind阶段:用于将标签数组进行展开,这样一个包含3个标签的文档会被拆解为3个条目。
- 3. g r o u p 阶段:对拆解后的文档进行分组计算, group阶段:对拆解后的文档进行分组计算, group阶段:对拆解后的文档进行分组计算,sum:"$favCount"表示按favCount字段进行累加。
- 4.$sort阶段:接收分组计算的输出,按total得分进行排序。
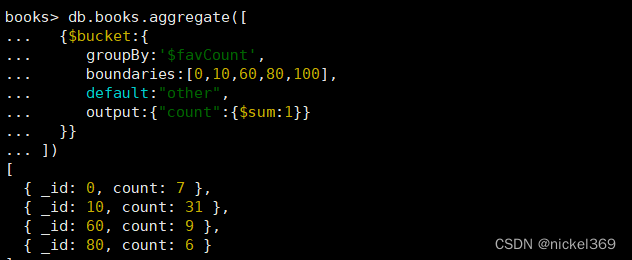
三、统计book文档收藏数[0,10),[10,60),[60,80),[80,100),[100,+∞0)
db.books.aggregate([
{$bucket:{
groupBy:'$favCount',
boundaries:[0,10,60,80,100],
default:"other",
output:{"count":{$sum:1}}
}}
])
聚合操作案例2:邮政编码数据集
导入邮政编码数据集:https://media.mongodb.org/zips.json
使用mongoimport工具导入数据:
mongoimport -h 192.168.1.66 -d test -u nickel-p nickel--authenticationDatabase=admin -c zips --file D:\software\mongodb\file\zips.json
- -h,–host :代表远程连接的数据库地址,默认连接本地Mongo数据库;
- –port:代表远程连接的数据库的端口,默认连接的远程端口27017;
- -u,–username:代表连接远程数据库的账号,如果设置数据库的认证,需要指定用户账号;
- -p,–password:代表连接数据库的账号对应的密码;
- -d,–db:代表连接的数据库;
- -c,–collection:代表连接数据库中的集合;
- -f, --fields:代表导入集合中的字段;
- –type:代表导入的文件类型,包括csv和json,tsv文件,默认json格式;
- –file:导入的文件名称
- –headerline:导入csv文件时,指明第一行是列名,不需要导入
四、返回人口超过1000万的州
db.zips.aggregate( [
{ $group: { _id: "$state", totalPop: { $sum: "$pop" } } },
{ $match: { totalPop: { $gte: 10*1000*1000 } } }
] )

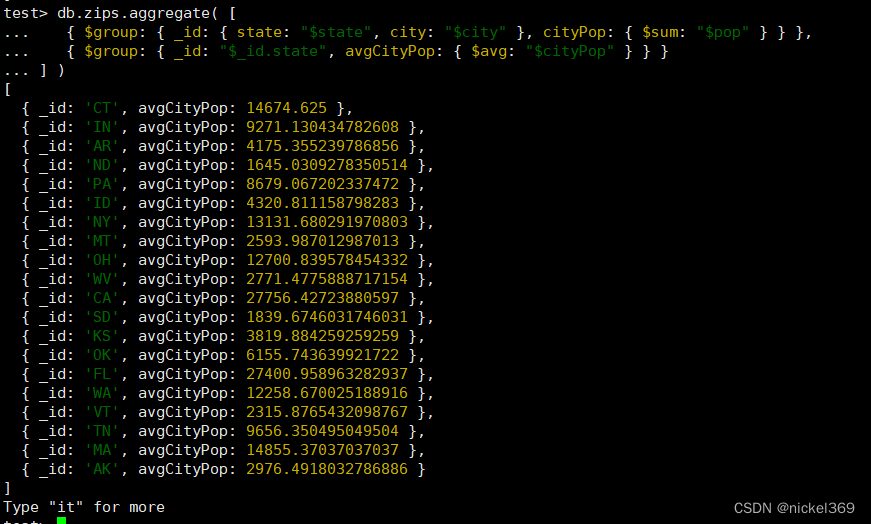
五、返回各州平均城市人口
db.zips.aggregate( [
{ $group: { _id: { state: "$state", city: "$city" }, cityPop: { $sum: "$pop" } } },
{ $group: { _id: "$_id.state", avgCityPop: { $avg: "$cityPop" } } }
] )
六、按州返回最大和最小的城市
db.zips.aggregate( [
{ $group:
{
_id: { state: "$state", city: "$city" },
pop: { $sum: "$pop" }
}
},
{ $sort: { pop: 1 } },
{ $group:
{
_id : "$_id.state",
biggestCity: { $last: "$_id.city" },
biggestPop: { $last: "$pop" },
smallestCity: { $first: "$_id.city" },
smallestPop: { $first: "$pop" }
}
},
{ $project:
{ _id: 0,
state: "$_id",
biggestCity: { name: "$biggestCity", pop: "$biggestPop" },
smallestCity: { name: "$smallestCity", pop: "$smallestPop" }
}
}
] )

2.聚合管道
一、Springboot进行聚合操作
①返回人口超过1000万的州
mongodb执行代码
db.zips.aggregate( [
{ $group: { _id: "$state", totalPop: { $sum: "$pop" } } },
{ $match: { totalPop: { $gt: 10*1000*1000 } } }
] )
java执行代码
/**
* 返回人口超过1000万的州
*/
@org.junit.jupiter.api.Test
public void testPiper(){
//$group
GroupOperation groupOperation = Aggregation.group("state").sum("pop").as("totalPop");
//$match
MatchOperation matchOperation=Aggregation.match(Criteria.where("totalPop").gte(10*1000*1000));
//按照聚合函数的顺序组合聚合函数
TypedAggregation<Zips> typedAggregation=Aggregation.newAggregation(Zips.class,groupOperation,matchOperation);
//执行聚合操作,如何不适用Map,也可以使用自定义的实体类
AggregationResults<Map> aggregationResults = mongoTemplate.aggregate(typedAggregation, Map.class);
//获取集合里面的实体
List<Map> mappedResults = aggregationResults.getMappedResults();
for (Map mappedResult : mappedResults) {
System.out.println(mappedResult);
}
}
②返回各州平均城市人口
mongodb执行代码
db.zips.aggregate( [
{ $group: { _id: { state: "$state", city: "$city" }, cityPop: { $sum: "$pop" } } },
{ $group: { _id: "$_id.state", avgCityPop: { $avg: "$cityPop" } } },
{ $sort:{avgCityPop:-1}}
] )
java执行代码
/**
*返回各州平均城市人口
*/
@org.junit.jupiter.api.Test
public void getEleStatePop(){
//获取每个州每个城市的汇总值
GroupOperation groupOperationSC=Aggregation.group("state","city").sum("pop").as("cityPop");
//获取每个城市的平均值
GroupOperation groupOperationAvg=Aggregation.group("_id.state").avg("cityPop").as("avgCityPop");
//排序
SortOperation sortOperation=Aggregation.sort(Sort.Direction.DESC,"avgCityPop");
TypedAggregation<Zips> typedAggregation = Aggregation.newAggregation(Zips.class, groupOperationSC, groupOperationAvg, sortOperation);
AggregationResults<Map> aggregate = mongoTemplate.aggregate(typedAggregation, Map.class);
for (Map map : aggregate) {
System.out.println(map);
}
}
③按州返回最大和最小的城市
mongodb执行代码
db.zips.aggregate( [
{ $group:
{
_id: { state: "$state", city: "$city" },
pop: { $sum: "$pop" }
}
},
{ $sort: { pop: 1 } },
{ $group:
{
_id : "$_id.state",
biggestCity: { $last: "$_id.city" },
biggestPop: { $last: "$pop" },
smallestCity: { $first: "$_id.city" },
smallestPop: { $first: "$pop" }
}
},
{ $project:
{ _id: 0,
state: "$_id",
biggestCity: { name: "$biggestCity", pop: "$biggestPop" },
smallestCity: { name: "$smallestCity", pop: "$smallestPop" }
}
},
{ $sort: { state: 1 } }
] )
java执行代码
/**
* 按州返回最大和最小的城市
*/
@org.junit.jupiter.api.Test
public void getMaxMinCity(){
GroupOperation groupOperationStateCity=Aggregation.group("state","city").sum("pop").as("pop");
SortOperation pop = Aggregation.sort(Sort.Direction.ASC, "pop");
GroupOperation groupLastFirst = Aggregation.group("_id.state")
.last("_id.city").as("biggestCity")
.last("pop").as("biggestPop")
.first("_id.city").as("smallestCity")
.first("pop").as("smallestPop");
ProjectionOperation projectionOperation = Aggregation
.project("state", "biggestCity", "smallestCity")
.and("_id").as("state")
.andExpression("{name:\"$biggestCity\",pop:\"$biggestPop\"}")
.as("biggestCity")
.andExpression("{name:\"smallestCity\",pop:\"smallestPop\"}")
.as("smallestCity")
.andExclude("_id");
SortOperation state = Aggregation.sort(Sort.Direction.ASC, "state");
TypedAggregation<Zips> typedAggregation = Aggregation.newAggregation(Zips.class, groupOperationStateCity, pop, groupLastFirst, projectionOperation, state);
AggregationResults<Map> aggregate = mongoTemplate.aggregate(typedAggregation, Map.class);
List<Map> mappedResults = aggregate.getMappedResults();
//System.out.println(mappedResults);
for (Map mappedResult : mappedResults) {
System.out.println(mappedResult);
}
}
3.MongodDB数据类型详解
3.1 BSON协议与数据类型
MongoDB为什么会使用BSON?
JSON是当今非常通用的一种跨语言Web数据交互格式,属于ECMAScript标准规范的一个子集。JSON(JavaScript Object Notation, JS对象简谱)即JavaScript对象表示法,它是JavaScript对象的一种文本表现形式。
作为一种轻量级的数据交换格式,JSON的可读性非常好,而且非常便于系统生成和解析,这些优势也让它逐渐取代了XML标准在Web领域的地位,当今许多流行的Web应用开发框架,如SpringBoot都选择了JSON作为默认的数据编/解码格式。
JSON只定义了6种数据类型:
- string: 字符串
- number : 数值
- object: JS的对象形式,用{key:value}表示,可嵌套
- array: 数组,JS的表示方式[value],可嵌套
- true/false: 布尔类型
- null: 空值
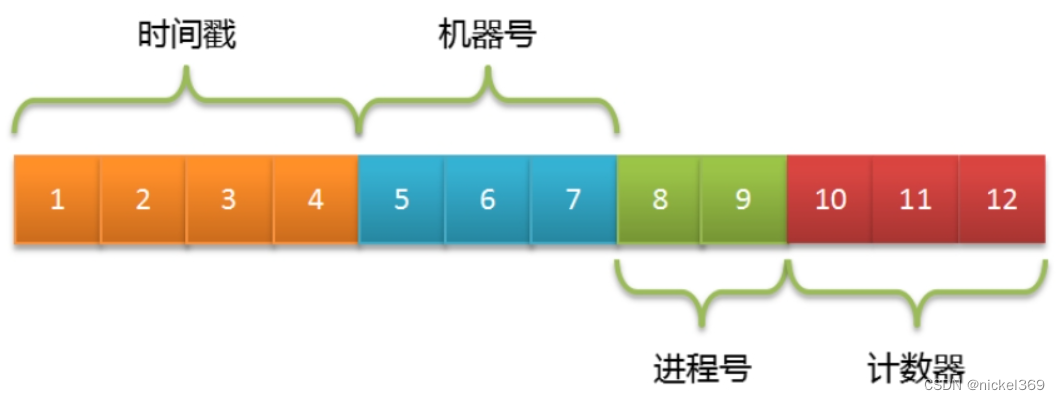
3.2 ObjectId生成器
MongoDB集合中所有的文档都有一个唯一的_id字段,作为集合的主键。在默认情况下,_id字段使用ObjectId类型,采用16进制编码形式,共12个字节。
为了避免文档的_id字段出现重复,ObjectId被定义为3个部分:
- 4字节表示Unix时间戳(秒)。
- 5字节表示随机数(机器号+进程号唯一)。
- 3字节表示计数器(初始化时随机)。

4.SpringBoot整合mongoDB
一.项目初始化
1.引入相关的jar包
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
2.在application.yml配置mongodb启动项
spring:
data:
mongodb:
uri: mongodb://nickel:nickel@192.168.2.66:27017/test?authSource=admin
3.创建emp表的实体类
package com.nq.springbootmongodb.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.mapping.Document;
import org.springframework.data.mongodb.core.mapping.Field;
import java.util.Date;
/**
* @Auther: Nickel
* DATE: 2023/12/2 14:56
* Description:
* @Version 1.0
*/
@Document("emp")
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Employee {
@Id
private Integer id;
@Field("username")
private String name;
@Field
private int age;
@Field
private Double salary;
@Field
private Date entryDay;
}
4.测试实体类是否存在,不存在则创建
/**
* @Auther: Nickel
* DATE: 2023/12/2 14:40
* Description:
* @Version 1.0
*/
@SpringBootTest
public class TestCollection {
@Autowired
MongoTemplate mongoTemplate;
@Test
public void test1(){
boolean exists = mongoTemplate.collectionExists("emp");
if(exists){
//删除集合
mongoTemplate.dropCollection("emp");
}
mongoTemplate.createCollection("emp");
}
}

二.java增删查改
1.新增
@Test
public void testInsert(){
Employee employee=new Employee(1,"Nickel",28,3000d,new Date());
mongoTemplate.insert(employee);
List<Employee> list = Arrays.asList(
new Employee(2, "fox", 22, 280020d, new Date()),
new Employee(3, "zhuge", 33, 2263d, new Date()),
new Employee(4, "zhouyu", 35, 282320d, new Date())
);
mongoTemplate.insert(list,Employee.class);
}

2.查询
- 通过对象进行查询
@Test
public void testFind(){
//查询所有文档
System.out.println("========查询所有文档======");
List<Employee> list = mongoTemplate.findAll(Employee.class);
list.forEach(System.out::println);
//根据ID进行查询
System.out.println("======根据ID进行查询========");
Employee employee = mongoTemplate.findById(1, Employee.class);
System.out.println(employee);
//返回第一个文档的数据
System.out.println("=======返回第一个文档的数据=======");
Employee one = mongoTemplate.findOne(new Query(), Employee.class);
System.out.println(one);
//条件查询
System.out.println("=======查询薪资大于等于8000的员工=======");
//查询薪资大于等于8000的员工
Query query8000=new Query(Criteria.where("salary").gte(8000));
List<Employee> list2 = mongoTemplate.find(query8000, Employee.class);
list2.forEach(System.out::println);
System.out.println("=======查询薪资大于等于4000小于等于10000=======");
//查询薪资大于等于4000小于等于10000
Query query8_10=new Query(Criteria.where("salary").gte(4000).lte(10000));
List<Employee> list3 = mongoTemplate.find(query8_10, Employee.class);
list3.forEach(System.out::println);
System.out.println("=======模糊查询name中包含zh的=======");
//正则模糊查询 java正则不需要有//
Query query_zh=new Query(Criteria.where("name").regex("zh"));
List<Employee> list4 = mongoTemplate.find(query_zh, Employee.class);
list4.forEach(System.out::println);
//and or 多条件查询
System.out.println("=======查询年龄大于25薪资大于8000的员工=======");
Criteria criteria_25_8000=new Criteria();
//查询年龄大于25薪资大于8000的员工
criteria_25_8000.andOperator(Criteria.where("age").gte(25),Criteria.where("salary").gte(8000));
Query query=new Query(criteria_25_8000);
List<Employee> list5 = mongoTemplate.find(query, Employee.class);
list5.forEach(System.out::println);
System.out.println("=======查询年龄大于25薪资大于8000的员工=======");
Criteria criteria_zhuge_8000=new Criteria();
//查询姓名是zhuge或者薪资大于8000的员工
criteria_zhuge_8000.orOperator(Criteria.where("name").is("zhuge"),Criteria.where("salary").gte(8000));
Query query1=new Query(criteria_zhuge_8000);
List<Employee> list6 = mongoTemplate.find(query1, Employee.class);
list6.forEach(System.out::println);
//排序
System.out.println("=======排序=======");
Query query2=new Query(criteria_zhuge_8000).with(Sort.by(Sort.Order.desc("salary")));
List<Employee> list7 = mongoTemplate.find(query2, Employee.class);
list7.forEach(System.out::println);
//分页
System.out.println("=======分页=======");
query=new Query().skip(2) //跳过前面两条
.limit(1); //显示一条数据
List<Employee> list8 = mongoTemplate.find(query, Employee.class);
list8.forEach(System.out::println);
}
- 通过json格式进行查询
@Test
public void testFindByJson(){
System.out.println("=======分页=======");
//查询年龄大于25或者薪资大于等于8000
String json="{$or:[" +
"{age:{$gt:25}}" +
",{salary:{$gte:8000}}" +
"]}";
Query query=new BasicQuery(json);
List<Employee> list = mongoTemplate.find(query,Employee.class);
list.forEach(System.out::println);
}
3.更新
@Test
public void testUpdate(){
Query query=new Query(Criteria.where("salary").lte(5000));
System.out.println("=======更新前=======");
List<Employee> list = mongoTemplate.find(query, Employee.class);
list.forEach(System.out::println);
System.out.println("=======把id为1的薪资调为5000=======");
//把id为1的薪资调为5000
Update update=new Update();
update.set("salary",5000);
System.out.println("=======更新满足条件的一条======");
UpdateResult updateResult = mongoTemplate.updateFirst(query, update, Employee.class);
System.out.println("=======更新满足条件的所有记录=====");
UpdateResult updateResult2 = mongoTemplate.updateMulti(query, update, Employee.class);
List<Employee> list2 = mongoTemplate.find(query, Employee.class);
list2.forEach(System.out::println);
}


4.删除
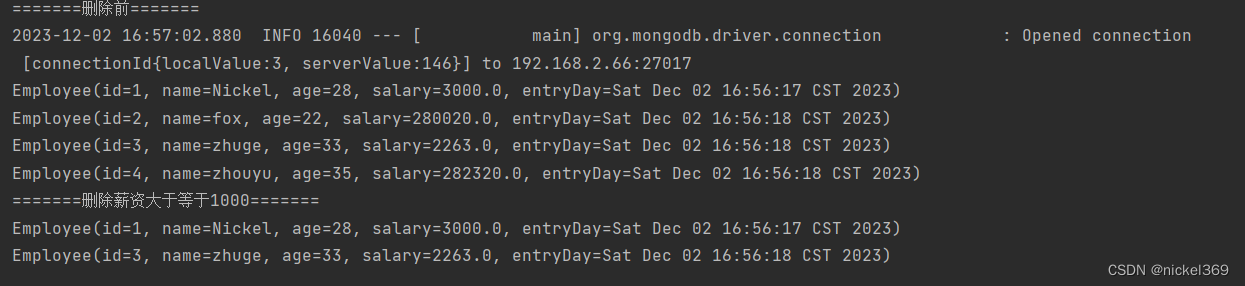
@Test
public void testDelete(){
//删除所有文档
// mongoTemplate.remove(new Query(),Employee.class);
System.out.println("=======删除前=======");
List<Employee> list = mongoTemplate.find(new Query(), Employee.class);
list.forEach(System.out::println);
System.out.println("=======删除薪资大于等于1000=======");
//删除薪资大于等于1000
Query query2=new Query(Criteria.where("salary").gte(10000));
mongoTemplate.remove(query2,Employee.class);
List<Employee> list2 = mongoTemplate.find(new Query(), Employee.class);
list2.forEach(System.out::println);
}
5.SpringBoot整合mongoDB
1.MongoDB索引详解
索引是一种用来快速查询数据的数据结构。B+Tree就是一种常用的数据库索引数据结构,MongoDB采用B+Tree 做索引,索引创建colletions上。MongoDB不使用索引的查询,先扫描所有的文档,再匹配符合条件的文档。 使用索引的查询,通过索引找到文档,使用索引能够极大的提升查询效率。
思考:MongoDB索引数据结构是B-Tree还是B+Tree?
mongodb用的数据结构是B-Tree,具体来说是B+Tree
a B-Tree ( B+ Tree to be specific)

2. 索引操作
①创建索引
db.collection.createIndex(keys, options)
②查看索引
#查看索引信息
db.books.getIndexes()
#查看索引键
db.books.getIndexKeys()

③删除索引
#删除集合指定索引
db.col.dropIndex("索引名称")
#删除集合所有索引 不能删除主键索引
db.col.dropIndexes()

3. 索引类型
一、单键索引
在某一个特定的字段上建立索引 mongoDB在ID上建立了唯一的单键索引,所以经常会使用id来进行查询; 在索引字段上进行精确匹配、排序以及范围查找都会使用此索引

#对title字段建立索引
db.books.createIndex({title:1})
# 对内嵌文档字段创建索引:
db.books.createIndex({"author.name":1})


二、复合索引
db.books.createIndex({title:1,favCount:1})
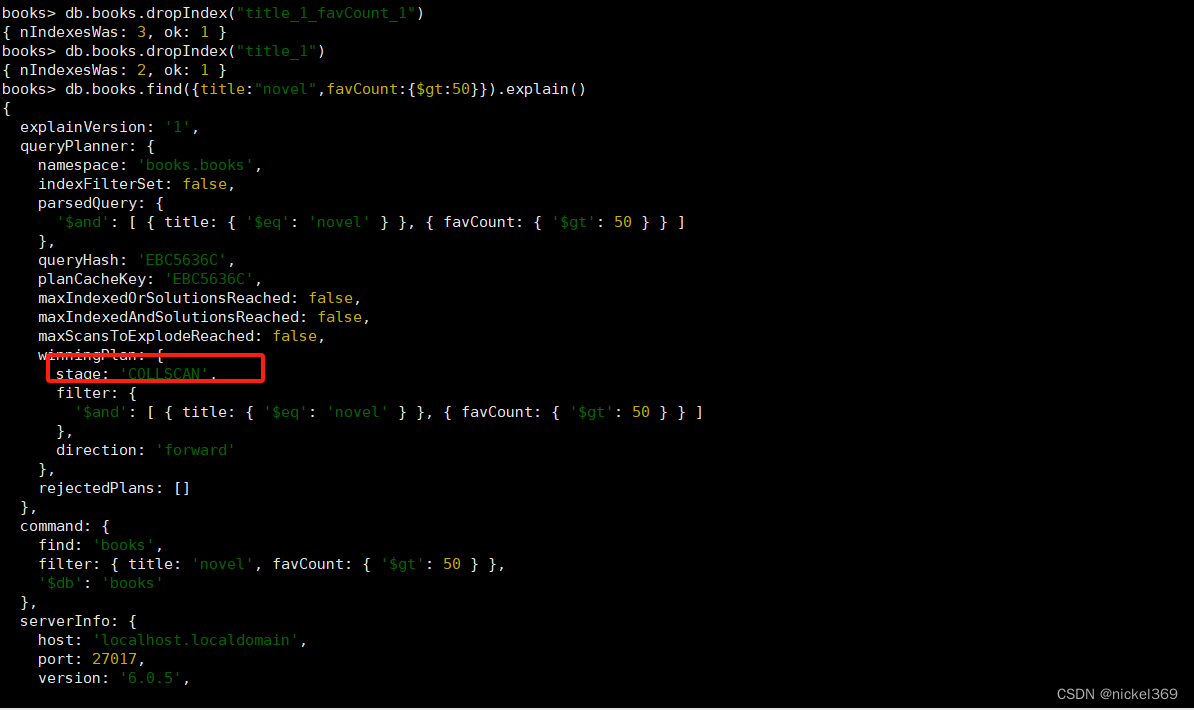

三、多键(数组)索引
在数组的属性上建立索引。针对这个数组的任意值的查询都会定位到这个文档,既多个索引入口或者键值引用同一个文档。
db.inventory.insertMany([
{
_id: 1,
item: "abc",
stock: [
{ size: "S", color: "red", quantity: 25 },
{ size: "S", color: "blue", quantity: 10 },
{ size: "M", color: "blue", quantity: 50 }
]
},
{
_id: 2,
item: "def",
stock: [
{ size: "S", color: "blue", quantity: 20 },
{ size: "M", color: "blue", quantity: 5 },
{ size: "M", color: "black", quantity: 10 },
{ size: "L", color: "red", quantity: 2 }
]
},
{
_id: 3,
item: "ijk",
stock: [
{ size: "M", color: "blue", quantity: 15 },
{ size: "L", color: "blue", quantity: 100 },
{ size: "L", color: "red", quantity: 25 }
]
}
])
创建索引
db.inventory.createIndex({"stock.size":1,"stock.quantity":1})
db.inventory.find({"stock.size":"S","stock.quantity":{$gt:20}}).explain()

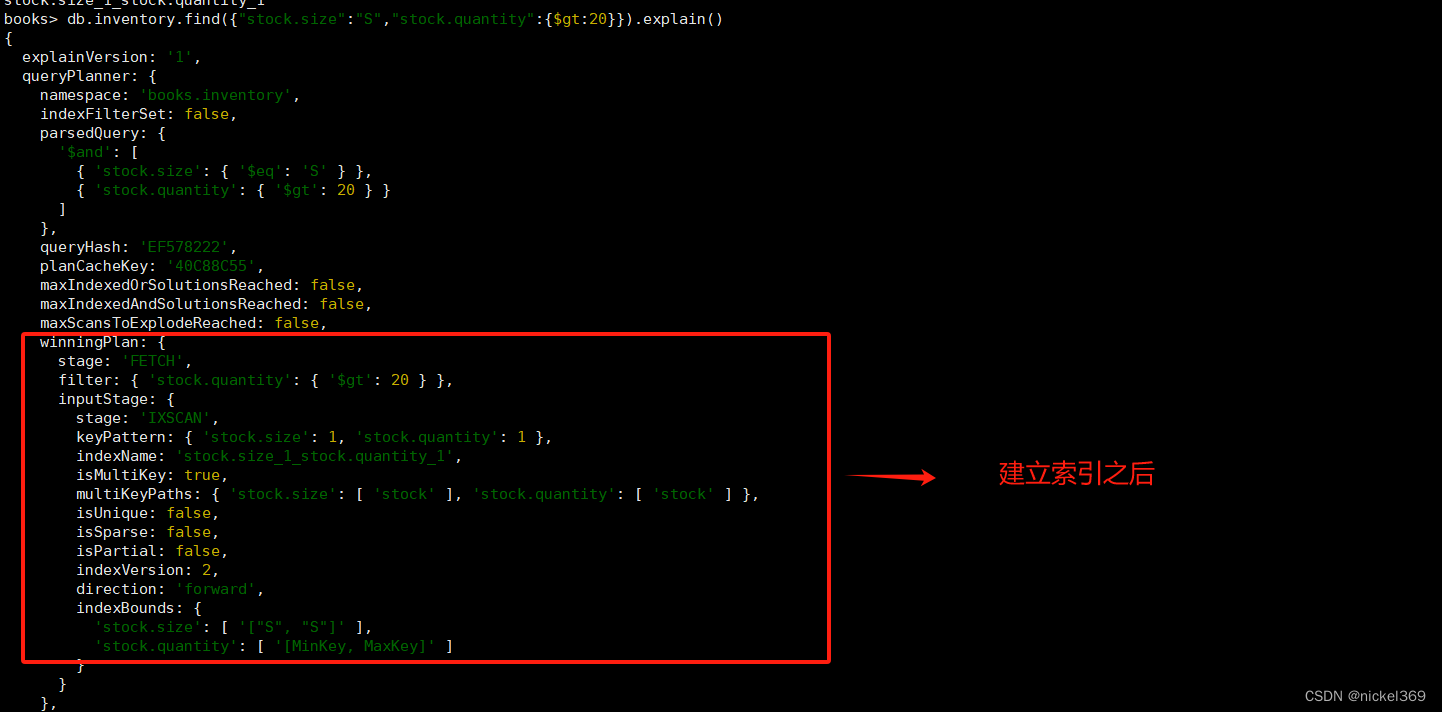
四、Hash索引
不同于传统的B-Tree索引,哈希索引使用hash函数来创建索引。在索引字段上进行精确匹配,但不支持范围查询,不支持多键hash; Hash索引上的入口是均匀分布的,在分片集合中非常有用;

五、地理空间索引
在移动互联网时代,基于地理位置的检索(LBS)功能几乎是所有应用系统的标配。MongoDB为地理空间检索提供了非常方便的功能。地理空间索引(2dsphereindex)就是专门用于实现位置检索的一种特殊索引。
假设商家的数据模型如下:
db.restaurant.insert({
restaurantId: 0,
restaurantName:"兰州牛肉面",
location : {
type: "Point",
coordinates: [ -73.97, 40.77 ]
}
})
创建索引
db.restaurant.createIndex({location : "2dsphere"})
查询附近10000米商家信息
db.restaurant.find({
location:{
$near:{
$geometry:{
type:"Point",
coordinates:[-73.88,40.78]
}
}
}
}).explain()

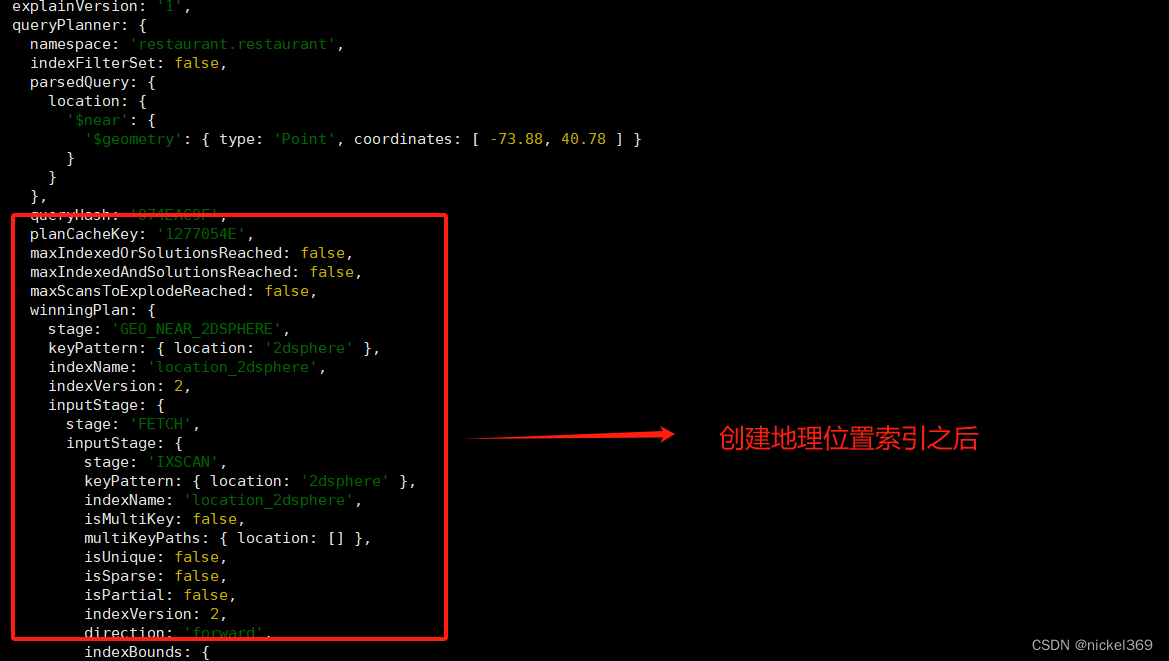
六、全文索引
t e x t 操作符可以在有 t e x t i n d e x 的集合上执行文本检索。 text操作符可以在有text index的集合上执行文本检索。 text操作符可以在有textindex的集合上执行文本检索。text将会使用空格和标点符号作为分隔符对检索字符串进行分词, 并且对检索字符串中所有的分词结果进行一个逻辑上的 OR 操作。
数据
db.stores.insert(
[
{ _id: 1, name: "Java Hut", description: "Coffee and cakes" },
{ _id: 2, name: "Burger Buns", description: "Gourmet hamburgers" },
{ _id: 3, name: "Coffee Shop", description: "Just coffee" },
{ _id: 4, name: "Clothes Clothes Clothes", description: "Discount clothing" },
{ _id: 5, name: "Java Shopping", description: "Indonesian goods" }
]
)
创建name和description的全文索引
db.stores.createIndex({name:"text",description:"text"})
测试,通过$text操作符来查寻数据中所有包含“coffee”,”shop”,“java”列表中任何词语的商店
db.stores.find({$text:{$search:"java coffee shop"}})

七、通配符索引
数据准备
db.products.insert([
{
"product_name" : "Spy Coat",
"product_attributes" : {
"material" : [ "Tweed", "Wool", "Leather" ],
"size" : {
"length" : 72,
"units" : "inches"
}
}
},
{
"product_name" : "Spy Pen",
"product_attributes" : {
"colors" : [ "Blue", "Black" ],
"secret_feature" : {
"name" : "laser",
"power" : "1000",
"units" : "watts",
}
}
},
{
"product_name" : "Spy Book"
}
])
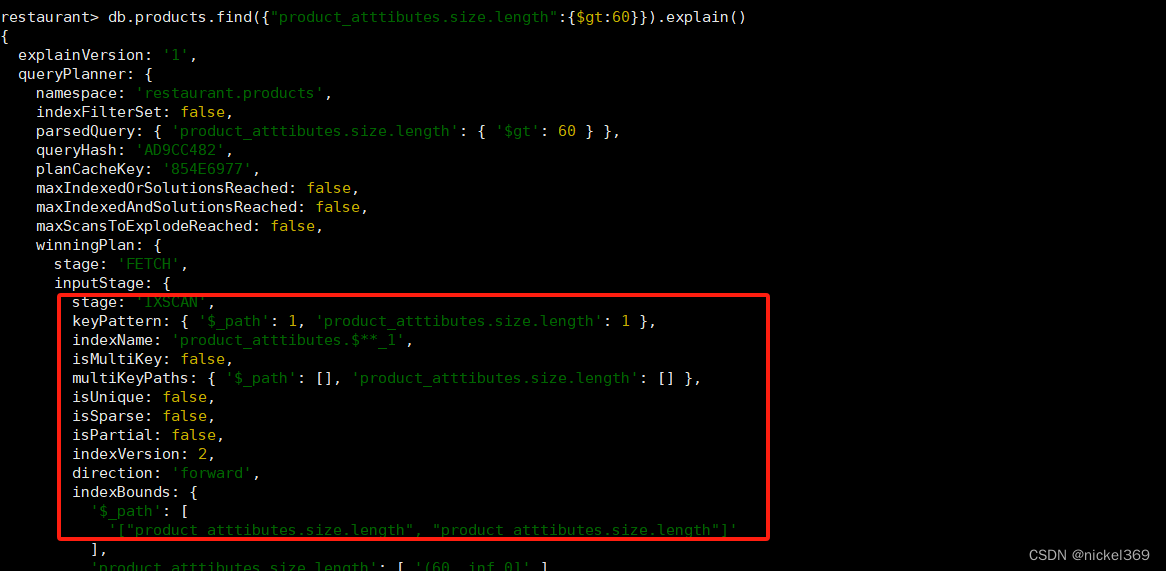
创建通配符索引
db.products.createIndex({"product_atttibutes.$**":1})
查询数据
db.products.find({"product_atttibutes.size.length":{$gt:60}}).explain()
四. 索引属性
1.唯一索引
在现实场景中,唯一性是很常见的一种索引约束需求,重复的数据记录会带来许多处理上的麻烦,比如订单的编号、用户的登录名等。通过建立唯一性索引,可以保证集合中文档的指定字段拥有唯一值。
db.books.createIndex({title:1},{unique:true})

- 唯一性索引对于文档中缺失的字段,会使用null值代替,因此不允许存在多个文档缺失索引字段的情况。
- 对于分片的集合,唯一性约束必须匹配分片规则。换句话说,为了保证全局的唯一性,分片键必须作为唯一性索引的前缀字段。
2.部分索引
部分索引仅对满足指定过滤器表达式的文档进行索引。通过在一个集合中为文档的一个子集建立索引,部分索引具有更低的存储需求和更低的索引创建和维护的性能成本。3.2新版功能。
创建索引
db.books.createIndex(
{type:1},
{partialFilterExpression:{favCount:{$gt:70}}}
)
显示结果

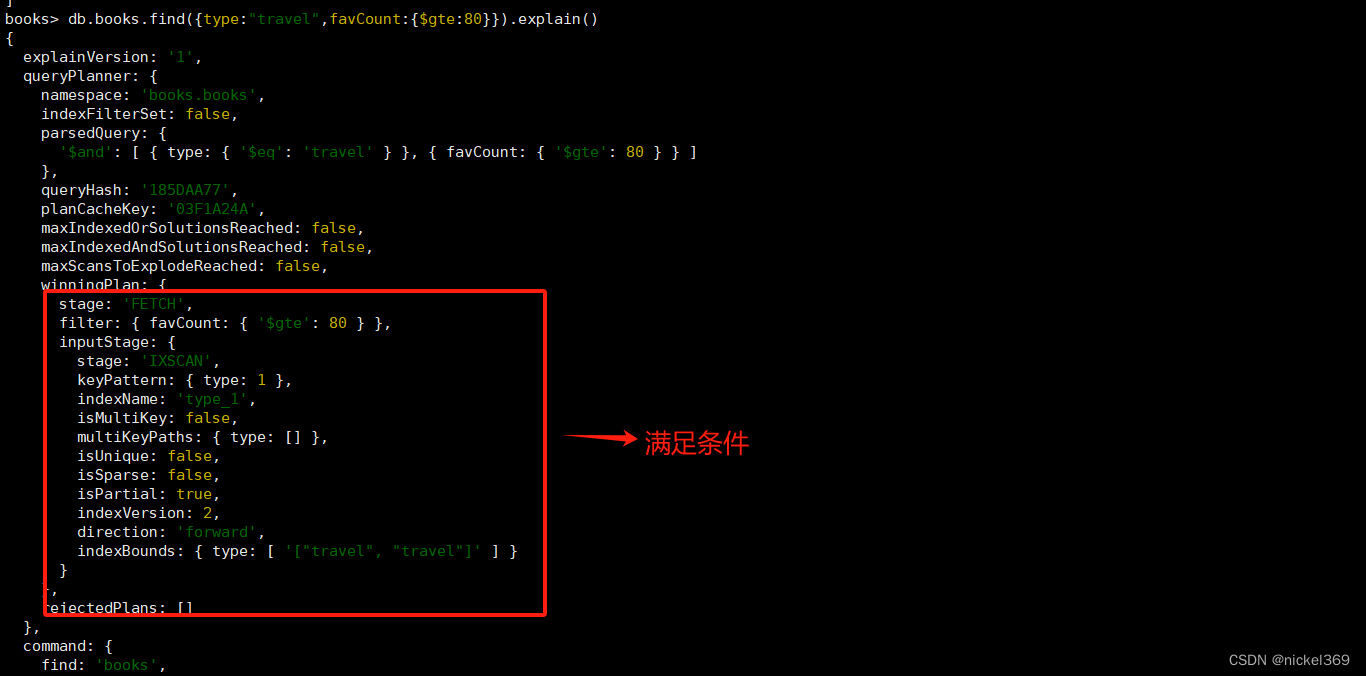
3.稀疏索引
索引的稀疏属性确保索引只包含具有索引字段的文档的条目,索引将跳过没有索引字段的文档。
案例
db.scores.insertMany([
{"userid" : "newbie"},
{"userid" : "abby", "score" : 82},
{"userid" : "nina", "score" : 90}
])
创建稀疏索引
db.scores.createIndex( { score: 1 } , { sparse: true } )
测试
db.scores.find( { score: { $lt: 90 } } )
db.scores.find().sort( { score: -1 } )


查询使用稀疏索引,排序分组不使用稀疏索
4.TTL索引
在一般的应用系统中,并非所有的数据都需要永久存储。例如一些系统事件、用户消息等,这些数据随着时间的推移,其重要程度逐渐降低。更重要的是,存储这些大量的历史数据需要花费较高的成本,因此项目中通常会对过期且不再使用的数据进行老化处理。
- 方案一:为每个数据记录一个时间戳,应用侧开启一个定时器,按时间戳定期删除过期的数据。
- 方案二:数据按日期进行分表,同一天的数据归档到同一张表,同样使用定时器删除过期的表。
数据
db.log_events.insertOne( {
"createdAt": new Date(),
"logEvent": 2,
"logMessage": "Success!"
} )
创建TTL索引
db.log_events.createIndex( { "createdAt": 1 }, { expireAfterSeconds: 20 } )
修改TTL时间
db.runCommand({collMod:"log_events",index:{keyPattern:{createdAt:1},expireAfterSeconds:600}})

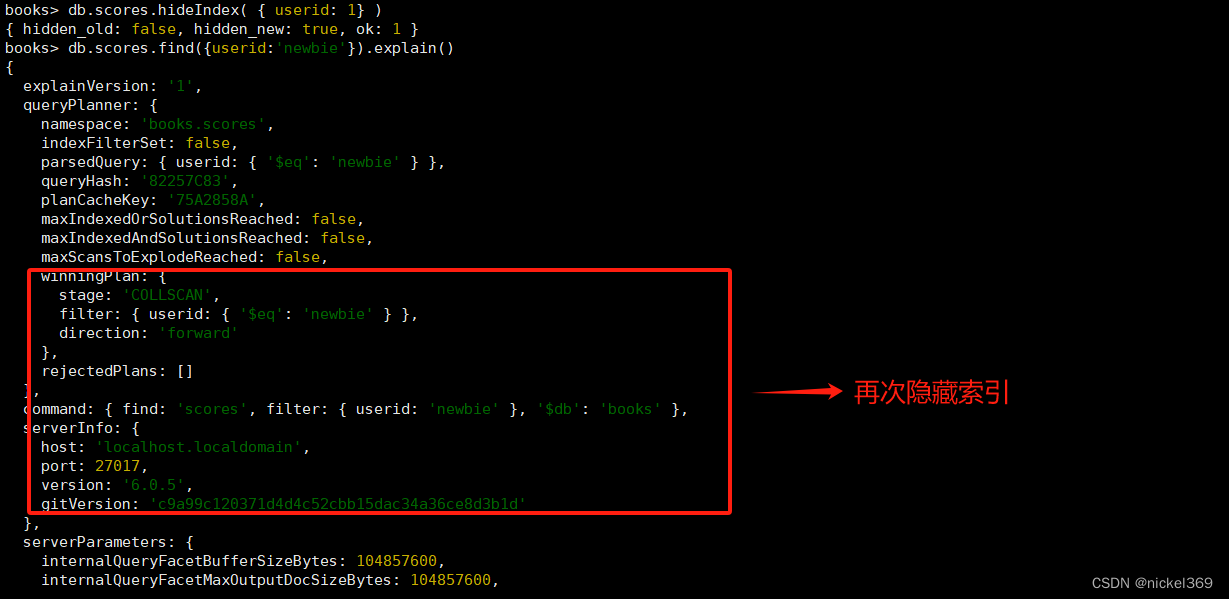
4.隐藏索引
隐藏索引对查询规划器不可见,不能用于支持查询。通过对规划器隐藏索引,用户可以在不实际删除索引的情况下评估删除索引的潜在影响。如果影响是负面的,用户可以取消隐藏索引,而不必重新创建已删除的索引。4.4新版功能。
数据
db.scores.insertMany([
{"userid" : "newbie"},
{"userid" : "abby", "score" : 82},
{"userid" : "nina", "score" : 90}
])
创建隐藏索引
db.scores.createIndex(
{ userid: 1 },
{ hidden: true }
)

打开隐藏索引
#索引功能显示
db.scores.unhideIndex( { userid: 1} )
#索引功能隐藏
db.scores.hideIndex( { userid: 1} )

















 3778
3778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









