







不同的字形,相同的编码
今天碰巧看了下unicode编码问题,计算机的世界真是太神奇了。
因为中日韩等多个地区都有自己汉字的写法,统计起来汉字个数就非常多了,如果文字采用16位全球文字编码(UCS-2标准),六万多个位置估计放汉字都不够。所以把一些同字异形的汉字统一成相同的编码,从而节省空间,这是十分有必要的。
其中汉字编码有个重要的国际标准ISO10646
原則上ISO 10646只对字(Character),而非字形(Glyph)编码。
也就是说同一个汉字在不同地区会被解析成不同的字形,简单理解是汉字写法的差异。
下图是win10+IE11的截图,原表格在维基百科上,不同浏览器会导致不同结果(所以怎样才能显示正常呢?)
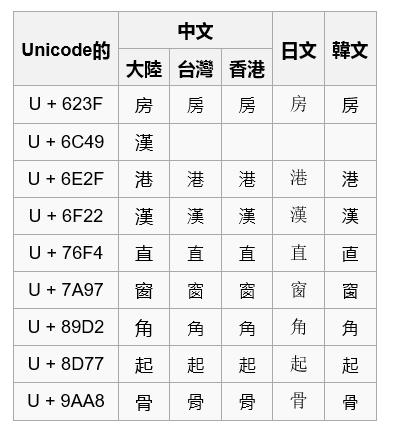
参考文二比较详细的编码知识介绍















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









