







环境简述:
31 master 。 32 node1 。 33 node2 。 34 harbor/docker。
问题现象:
一、master/node节点,去curl pod IP,一直卡着,没反应。timeout。
二、挂起恢复后,harbor服务无法正常访问503 ,需要重启harbor服务。

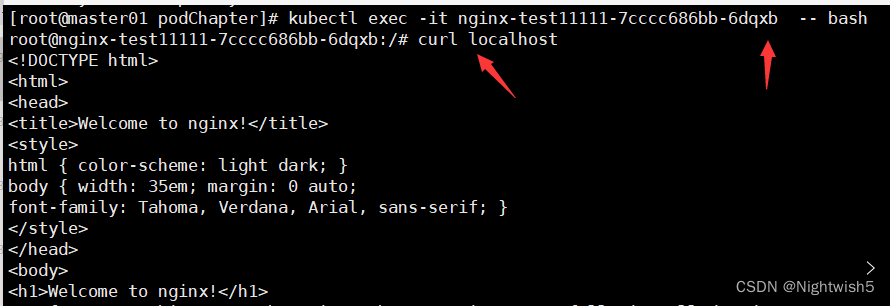
进容器curl localhost,是正常的。
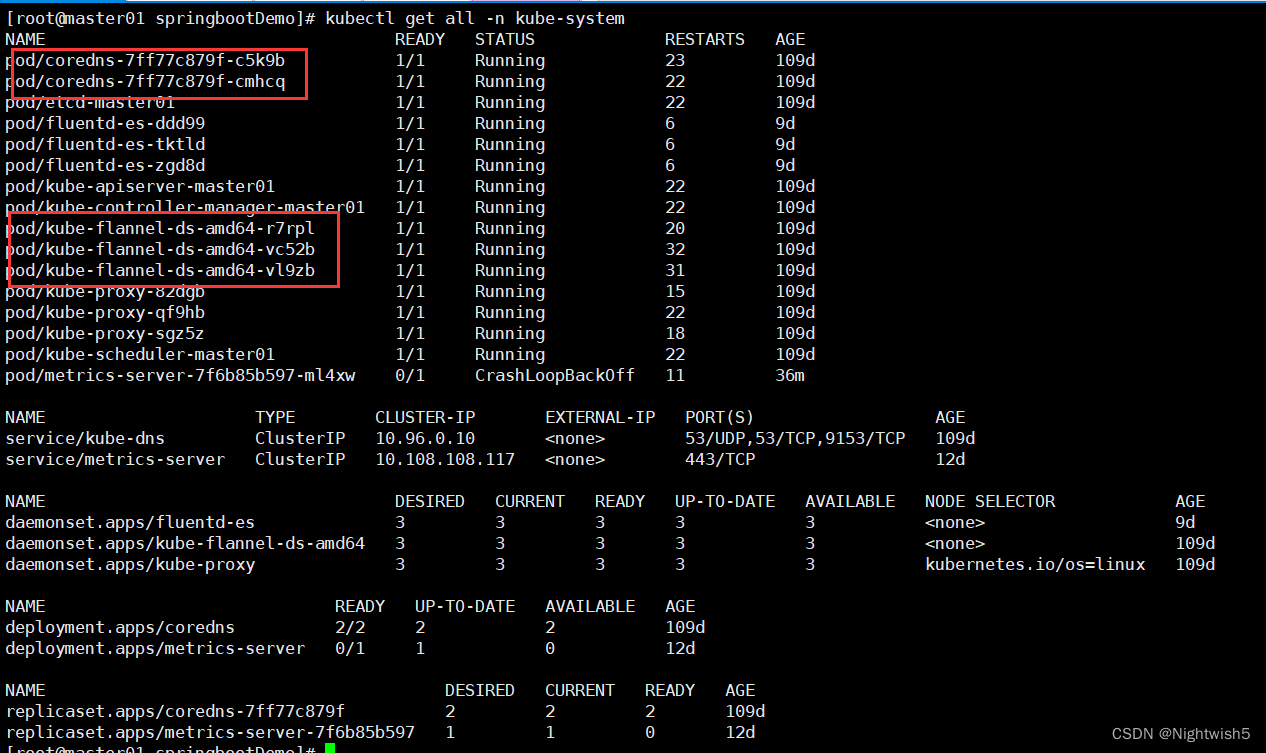
而网络CNI 、flannel 、 coreDNS等都是running状态。 (发现restarts的次数有点多) .这里的metrics-server一直失败的。
排查:
#下面两个能显示出对应的报错信息
vim /var/log/message
systemctl status kubelet -f
#此时coreDNS、、flannel、kube-proxy 的 describe/logs 日志是正常的
kubectl describe pod (coredns/flannel/kube-proxy) -n kube-system
kubectl logs (coredns/flannel/kube-proxy) -n kube-system
最终处理
#通过搜索/问人。有老哥说,这是VMware挂起导致的。 看messages信息,也吻合挂起时间。 (这个问题也没会想到是挂起vm的锅,报错日志也没明确的信息提示是“挂起后”导致的)
systemctl restart docker && systemctl restart kubelet
重启coreDNS、、flannel、kube-proxy。 都没用。
最终reboot重启 k8s集群的机器。
小结:所以挂起vm再唤醒机器,K8s/docker-compose起的服务,网络都可能会有故障。 优先从/var/log/message和systemctl status kubelet -f找出报错信息,提高处理问题效率。
可参考:
https://blog.csdn.net/weixin_43293361/article/details/114731838 《解决 虚拟机挂起后再恢复导致的k8s集群网络问题》
其他-报错日志信息(待写)















 870
870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









