







一、欧拉bclinux 21.10安装zabbix-5.0.37.tar.gz (zbx-客户端)
#系统环境:
BigCloud Enterprise Linux For Euler 21.10 LTS
#软件信息:
zabbix-5.0.37.tar.gz , pcre-devel-8.44-2.oe1.x86_64.rpm , installZbxAgent5.sh
安装脚本: installZbxAgent5.sh
#!/bin/bash
#安装所需软件
sudo yum install -y gcc
sudo yum install -y pcre-devel
sudo rpm -Uvh /tmp/pcre-devel-8.44-2.oe1.x86_64.rpm
sudo yum install -y make
sudo useradd -s /sbin/nologin zabbix -M
sudo chmod 644 /var/log/messages
#编译安装
sudo sh -c "cd /tmp/zbx-agent5 && sudo tar xf zabbix-5.0.37.tar.gz"
sudo sh -c "cd /tmp/zbx-agent5/zabbix-5.0.37 && ./configure --enable-agent --disable-dependency-tracking && make install && echo 'install zbx-agent-ok' "
#修改配置文件
sudo mkdir -p /etc/zabbix
sudo cp /usr/local/etc/zabbix_agentd.conf /etc/zabbix/zabbix_agentd.conf
sudo sed -r -i "s#Server=127.0.0.1#Server=10.xx.xx.xx#g;s#ServerActive=127.0.0.1#ServerActive=10.xx.xx.xx#g" /usr/local/etc/zabbix_agentd.conf /etc/zabbix/zabbix_agentd.conf
sudo cat << 'EOF' > /lib/systemd/system/zabbix-agent.service
[Unit]
Description=Zabbix Agent
After=syslog.target
After=network.target
[Service]
Environment="CONFFILE=/etc/zabbix/zabbix_agentd.conf"
EnvironmentFile=-/etc/sysconfig/zabbix-agent
Type=forking
KillMode=control-group
ExecStart=/usr/local/sbin/zabbix_agentd -c $CONFFILE
ExecStop=/bin/kill -SIGTERM $MAINPID
[Install]
WantedBy=multi-user.target
EOF
sudo systemctl daemon-reload
sudo systemctl enable zabbix-agent --now
ss -naltp | grep 10050
1.1 小结
1、expect脚本调用 bash run.sh "sudo bash /tmp/installZbxAgent5.sh" 不懂为啥编译完后 不继续跑了。
2、cat EOF 要加单引号, 否则内容含有$号的内容,会“消失” (会被转义)
3、绝对路径 sh -c 用法 。如果之前写法是 cd /tmp/zbx/xx ; ./configure xxx 会报错 no such filexxxx
4、注意zabbix-agent.service文件的user和group。 (zabbix_agentd.conf里 默认禁止root启动zbx服务。)
5、使用远程调用也要注意执行的路径,所以写成了rpm -Uvh /tmp/pcre-devel-8.44-2.oe1.x86_64.rpm 。可ssh过去后,pwd查看当前所在路径。 反正写绝对路径,绝没错。
( ssh test@192.168.1.100 "bash /tmp/zbx5/installZbxAgent5.sh" )
6、yum -y install --downloadonly --downloaddir=/tmp pcre-devel #下载pcre-devel的rpm包,环境是内网的。有的没配yum源
7、dos2unix installZbxAgent5.sh
二、替换软连接和普通文件的名称
#使用方法 。 log4j*.jar slfj-log4j*.jar这个是要查找的文件,后面是把log4j换成test
sh changeTest.sh log4j*.jar slfj-log4j*.jar log4j test
#注意事项!
注意find查找的东西,如果你只想替换部分,则只写“部分”的内容,精准替换。 不然他会把findlog.txt的内容全部替换/全部删掉
changeTest.sh 脚本代码: (make by liang)
#! /bin/sh
. /etc/profile
dateStr=`date +"%Y%m%d%H%M%S"`
echo `date +"%Y-%m-%d %H:%M:%S"` > /root/excute_${dateStr}.log
echo "开始执行替换任务................................" >> /root/excute_${dateStr}.log
#备份历史查找记录
if [ -e /root/findlog.txt ];then
cat /root/findlog.txt >> /root/findlog_his.txt
fi
#查找对应文件
#find / -name $1 -o -name $2 > /root/findlog.txt
#先备份文件
cat findlog.txt| while read line
do
#文件路径
filepath=`echo $line |awk -F '/' '{for(i=1;i<=NF-1;i++){printf "%s/", $i}; printf "\n"}'`
bakpath=`echo $line |awk -F '/' '{for(i=1;i<=NF-2;i++){printf "%s/", $i}; printf "\n"}'`
bakname=`echo $line |awk -F '/' '{print $(NF-1)}'`
#备份相关文件
cd ${bakpath}
echo "备份文件............." >> /root/excute_${dateStr}.log
echo "tar -czf ${bakname}.tar.gz ${bakname}" >> /root/excute_${dateStr}.log
tar -czf ${bakname}.tar.gz ${bakname}
done
#执行替换操作
cat findlog.txt| while read line
do
#文件路径
filepath=`echo $line |awk -F '/' '{for(i=1;i<=NF-1;i++){printf "%s/", $i}; printf "\n"}'`
if [ -L $line ];then
echo $line"是软连接" >> /root/excute_${dateStr}.log
#软连接目录件
lnpath=`ls -l $line |awk -F ' -> ' '{print $2}'`
#进到对应目录
cd $filepath
newlnfile=`echo $lnpath|sed "s/$3/$4/g"`
newfile=`echo $line|sed "s/$3/$4/g"`
echo "重命名软连接原始文件.............." >> /root/excute_${dateStr}.log
echo "mv $filepath$lnpath $filepath$newlnfile" >> /root/excute_${dateStr}.log
mv $filepath$lnpath $filepath$newlnfile
echo "重新设置软连接..........." >> /root/excute_${dateStr}.log
echo "ln -s $filepath$newlnfile $newfile" >> /root/excute_${dateStr}.log
ln -s $filepath$newlnfile $newfile
echo "删除之前软连接..........." >> /root/excute_${dateStr}.log
echo "rm -rf $line" >> /root/excute_${dateStr}.log
rm -rf $line
else
echo $line" 不是软连接" >> /root/excute_${dateStr}.log
newfile=`echo $line|sed "s/$3/$4/g"`
echo "重命名文件名称..........." >> /root/excute_${dateStr}.log
echo "mv $line $newfile" >> /root/excute_${dateStr}.log
mv $line $newfile
fi
done
三、定制rpm学习笔记
#博主:
https://zhuanlan.zhihu.com/p/652906168 《如何编译打包OpenSSH 9.4并实现批量升级》 centos7/centos6
https://www.jianshu.com/p/f1ae6f58a089 《虚拟机制作 openssh rpm升级包》 centos7
https://blog.csdn.net/forestqq/article/details/132685885 《编译CentOS6.10系统的OpenSSHV9.4rpm安装包》
https://blog.csdn.net/alwaysbefine/article/details/131217650 《Linux|编译最新版的openssh-server-9.3的rpm包(一)》centos7
#视频:
BV1KZ4y1s7Ve --> ob
BV1ai4y1N7gp --> mage (推荐)
四、监控ngx并切换配置文件
#make by junmajinlong
#!/bin/bash
# 后端节点地址列表
backends=(
addr1
addr2
addr3
addr4
addr5
)
# 检查指定的后端节点是否健康,健康则返回状态码0,否则返回状态码1
# 可以考虑多进程并发检查
function health_checker() {
backend_addr=$1
...CHECK...
return 0 or 1
}
# 检查给定后端节点列表(数组)中健康的节点,并将健康的节点地址保存到数组中,
# 第一个参数是待检查的后端节点地址列表的数组名,
# 第二个参数是空数组的数组名,将保存健康的后端地址列表
# 两个参数必须是数组的变量名,而不是 ${数组名} 格式
function health_backends() {
[ $# -lt 2 ] || {
echo "error: should give me two arguments"
return
}
[[ $(declare -p $1 2>/devnull) =~ "declare -a" ]] || {
echo "error: first argument invalid, should give me an array name"
return
}
[[ $(declare -p $2 2>/devnull) =~ "declare -a" ]] || {
echo "error: second argument invalid, should give me an array name"
return
}
declare -n backends=$1
declare -n ok_backends=$2
for addr in ${backends[@]};do
if health_checker(addr);then
ok_backends+=(addr)
fi
done
declare +n backends
declare +n ok_backends
}
# 修改配置文件(该配置文件和原始配置文件相同,但已经设置好限流),
# 因此,每次切换该配置文件时,只需移除其中的不健康节点,以及添加健康的节点
function change_ngx_conf() {}
# reload nginx,
# 如果不给参数,表示健康节点数量多,应加载不做限流的原始配置文件
# 如果给参数,表示健康节点不多,应加载修改后的配置文件
function reload_ngx() {
if [ $1 ];then
systemctl reload nginx@$1
else
systemctl reload nginx
fi
}
function main() {
while true;do
# 该数组保存健康的后端节点地址
ok_backends=()
health_backends backends ok_backends
if [ ${#ok_backends[@]} -le 2 ];then
change_ngx_conf ok_backends
reload_ngx "limit_ngx"
elif [ ${#ok_backends[@]} -ge 5 ];then
reload_ngx
fi
sleep 60
done
}
main
五、Linux编码显示中文问题,能正常显示中文,但是缺少部分中文内容。
#问题描述:
最初ls -l查看 , 然后head , ll , file 都报 no such file .
然后 sz * 下载到Windows,才发现它文件名不同的现象 (xlsx文件是 带 “中的错误” 文字的)
文件来源: ftp登录 , mget下来他显示有“中的” 。 但本地 ls -l 后,又没了。
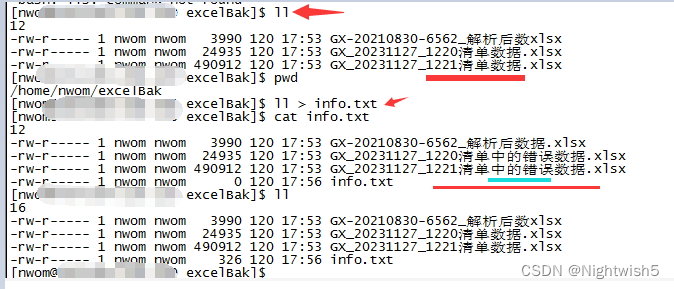
处理:
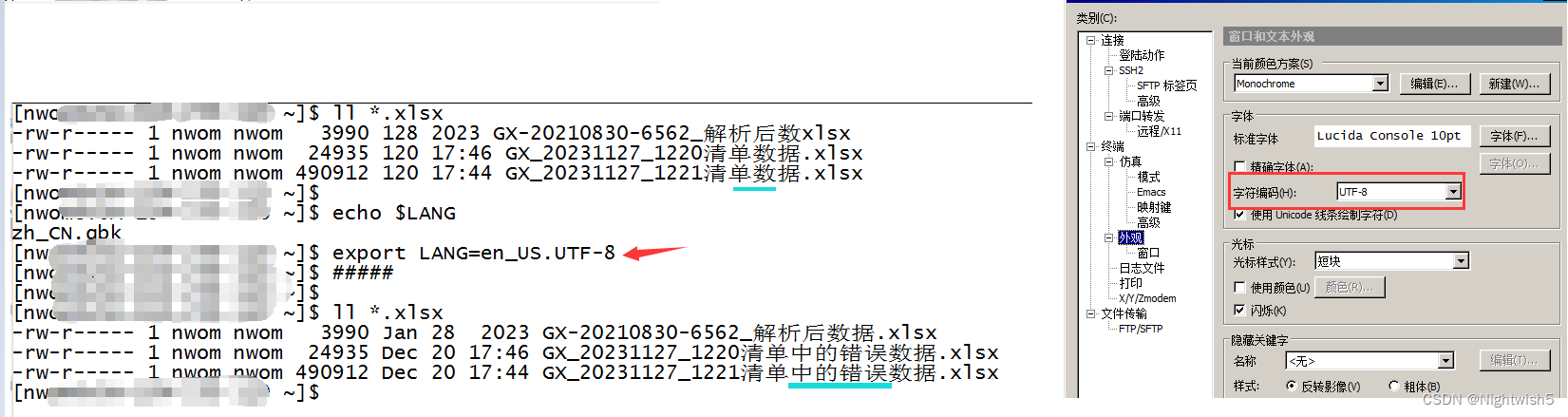
#机器的最初编码是临时设置为 zh_CN.gbk 。
临时设置编码export LANG=en_US.UTF-8 。 secureCRT字符编码设置为 UTF-8
但奇怪/疑惑的是。最初是GBK编码。 ll > info.txt 他info.txt 是能显示对的
六、csv文件编码问题,导致脚本里面的sed无法正常执行。
#环境信息:
CentOS 7.9 。 csv文件来自对方的ftp服务器。
#问题描述
目的:想删掉csv的表头信息。
代码语句为:
sed -i -r '1d' xxdata.csv && head -2 xxdata.csv
#尝试的操作
1、在CRT黑窗口 外面手动执行sed语句效果正常。
2、将csv文件拉到Windows系统,git bash 里面执行shell 也是正常。
3、sh -c "sed -i -r '1d' xxdata.csv && head -2 xxdata.csv" 也没用。
但是将 sed 写在该服务器的shell脚本里。 竟然没成功删表头。
处理方法:
#转换csv文件的编码为utf8 ,然后sed操作。 file -i xxdata.csv 查看文件编码
cat xxdata_7*_${day}.csv > xxdata_${day}.csv
iconv -f gbk -t utf-8 xxdata_${day}.csv > xxdata_${day}_d.csv
sed -i '/订单编号/d' xxdata_${day}_d.csv
七、记录处理“inode节点使用率满了”
#df 部分信息
[root@w ~]# df -i
文件系统 Inodes 已用(I) 可用(I) 已用(I)% 挂载点
devtmpfs 16499053 502 16498551 1% /dev
/dev/vdb 67108864 65139428 1969436 98% /data
/dev/loop0 0 0 0 - /mnt/bclinux
[root@w ~]# df -mh
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/rootvg-lv_root 9.8G 83M 9.2G 1% /
/dev/vdb 1008G 495G 463G 52% /data
/dev/loop0 4.5G 4.5G 0 100% /mnt/bclinux
问题描述: 使用 find / "log4j*.jar" 很慢。 然后df -i 查看,发现inode差不多满了。
#找出大量文件所在的文件夹方法:(看下哪个目录文件数多),找到后rm删掉。
# find . -type f -mtime +100 -name "*.cache-7" -exec rm -f {} \;
#find . -type f -name "*.mp4" -print0 | xargs -0 rm -f
# nohup find ./ -type f -mtime +30|xargs -i rm {} &
#1
nohup du -h --max-depth=1 /data/ > duInfo.txt &
ls -f 或 ls -f | wc -l (这样能秒速 统计出有多少个数量。 推荐使用 ) 。
]$ time ls -f | wc -l
183217
real 0m0.129s
ls -Rf | wc -l #这样会慢一些,毕竟递归查询了。
find PATH -max-depth 1 -type d
#2
for i in /data; do echo $i; find $i |wc -l|sort -nr; done
du --inodes --max-depth=1 /data
#3
tree -J | jq .'[1]'
tree -J | jq .'[1]'.files
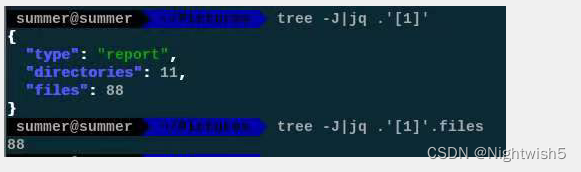
# 最快的思路是,find找好最顶层有多少个目录,这里可以加修改时间的条件来过滤最近没有修改过的目录。
#然后多进程去找每个目录里有多少文件,找超大数量的目录里有多少文件用tree会很慢,ls -f,或者find会很快.
# 如果只是统计文件数量的话,find还可以再加快一点,不要输出全文件名,随便输出一个字符就好了
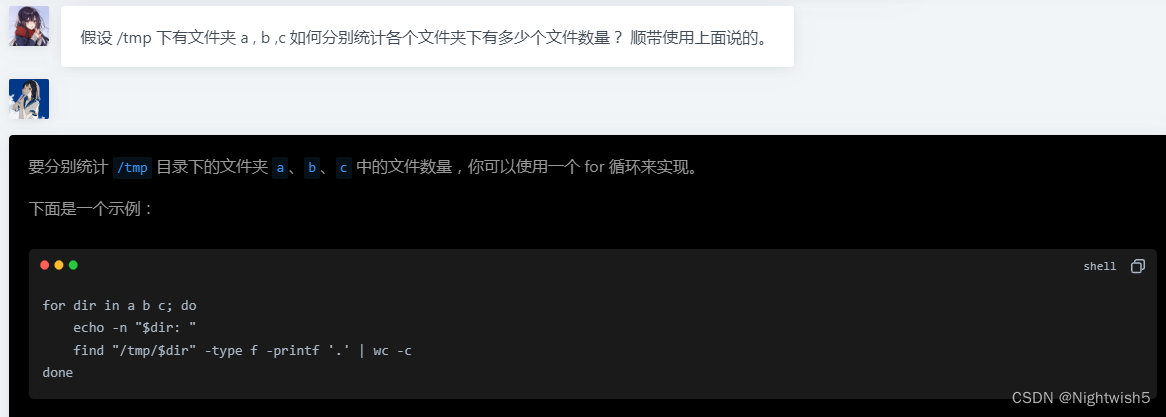
#make by Steven & malongshuai.
for dir in a b c; do
echo -n "$dir: "
find "/tmp/$dir" -type f -printf '.' | wc -c
done
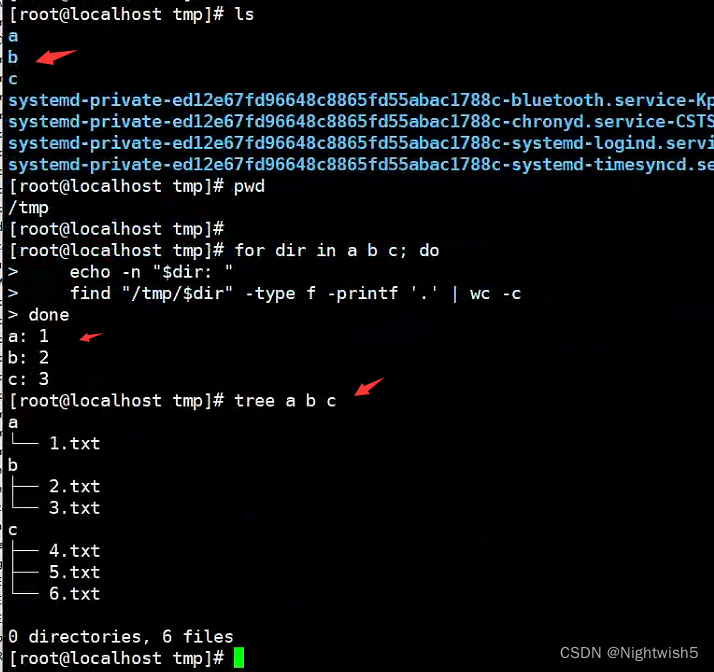
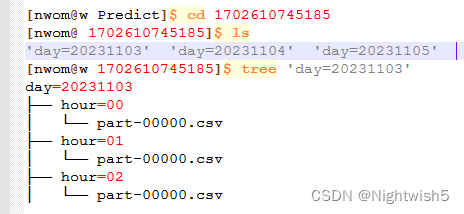
小结: 处理了18万个文件夹,或许有6400万个文件。 部分文件内容是:
7.1 find + xargs 加速删除文件操作
#加速找+删 (按实际情况修改mtime 和 name的值 ) make by mrqiao
find ./ -mtime +181 -type f -name "*.*" -print0 | xargs -0 -P4 -n20000 rm -rf
#(按实际情况配置) 加上 maxdepth 6 查找的速度会提升很多。 加了 --max-procs 10 后会多个进程进行rm操作 (ps -ef | grep rm 可看出)
cd /data1
find ./ -maxdepth 6 -type d -regex '.*/2024011[0-5]*' | xargs --max-procs 10 -i rm -rf {};
find ./ -maxdepth 5 -type d -name "2023*" | xargs --max-procs 10 -i rm -rf {};
八、使用du+awk 统计文件夹的总容量
cd /data3/
du -s */*/20240122 | awk '{sum=sum+$1} END{print sum/1024/1024 "GB"}'
#二层目录 精确搜索
du -s */{IMM-M3-MDT,IMM-MM-MDT,LOG-MDT,RLFRCEF}/20240122 | awk '{sum=sum+$1} END{print sum/1024/1024 "GB"}'
九、find 文件很慢,排查思路
free -mh 查看free的内存 容量还剩多少。
##root 释放内存
free && sync && echo 3 > /proc/sys/vm/drop_caches && echo "" && free -mh
top 查看id和wa的值
iotop 查看IO的占比
df -mh 查看磁盘情况
df -i 查看IUsed的值,有的服务器达到了3亿多,搜索慢是正常的。
十、在redhat6.9 使用 rpm -qa telnet-server卡住,ctrl+c也无法取消。
普通用户正常使用rpm -q ,但是root用户使用rpm -q就卡住不动。
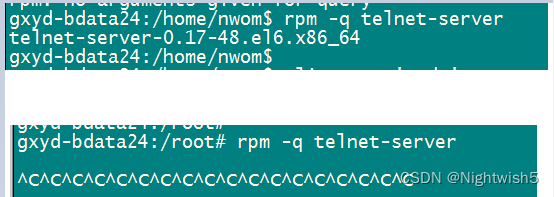
#处理方法:
rm -f /var/lib/rpm/__db*
rpm -vv --rebuilddb
参考:http://blog.chinaunix.net/uid-16362696-id-2746873.html















 1745
1745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









