







前言:
本文对工业界和学术界(截止2023-09)相关进展进行深入调研,并结合自身过往工作经验,对推荐系统中排序过程涉及知识进行总结。内容总结PPT请看:
 https://github.com/BinFuPKU/CTRRecommenderModels
https://github.com/BinFuPKU/CTRRecommenderModels意义:
- 用较为复杂的排序模型对召回回来的物品集合进行兴趣偏好打分,采用一定规则对物品进行(重)排序和过滤,产生最终曝光列表。

排序策略
交叉模型
- 三塔模型:在双塔基础上增加一个交叉塔,实现特征交叉。
- 交叉模型:
- 用户侧和物品侧进行特征交叉。
- 浅层交叉:FM、FFM等。
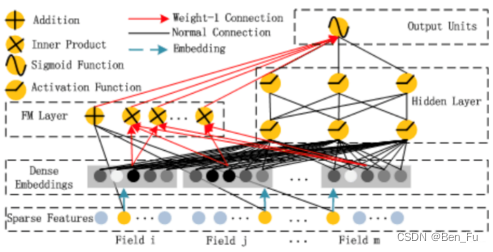
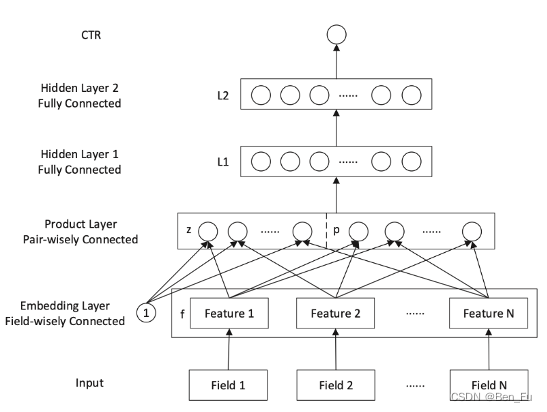
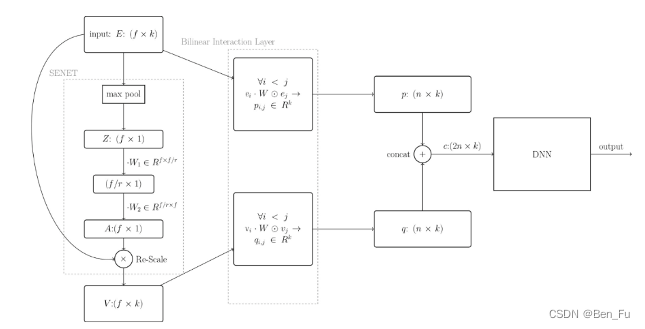
- 深层交叉: DeepFM(上)、DeepCrossing、Wide & Deep、PNN(中)、NFM、AFM、FiBiNET、DCN V2、SENET(下)等。
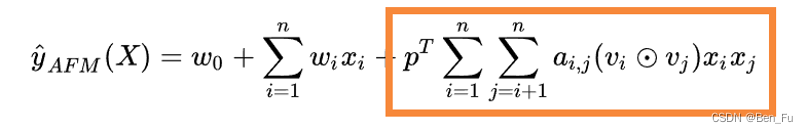
用户行为序列
- 挖掘用户行为序列信息[1~7]
-
- 原理:从行为序列中挖掘多样性偏好,发觉同目标物品相似兴趣偏好(交叉实现)。
- DIEN [3]:改进DIN,利用改造GRU捕捉同当前目标物品相似的历史偏好。
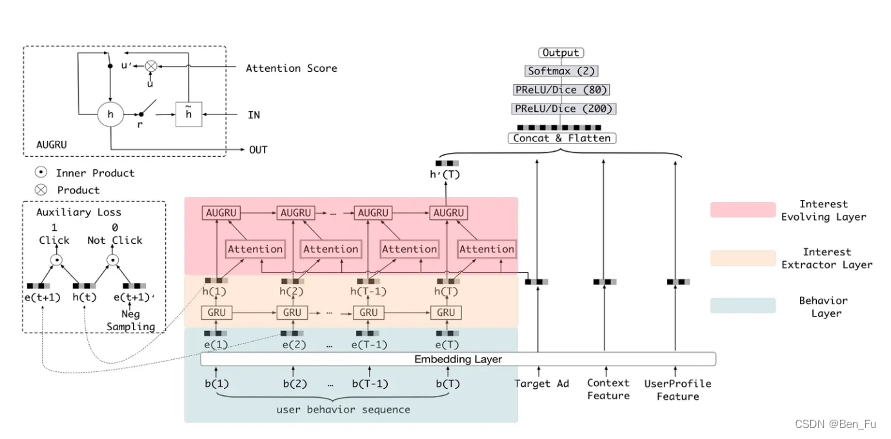
-
- SASRec [4]和BSTransformer [5] : 利用transformer来建模用户历史序列。
- DSIN [6]:用户行为序列切分成不同session,抽取session兴趣。
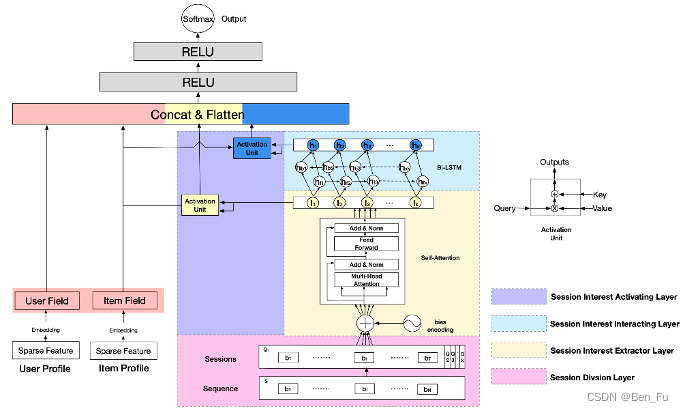
-
- PPNet [8]:借鉴LHUC思想(语义叠加个性化),gating 机制增加网络参数的个性化学习。
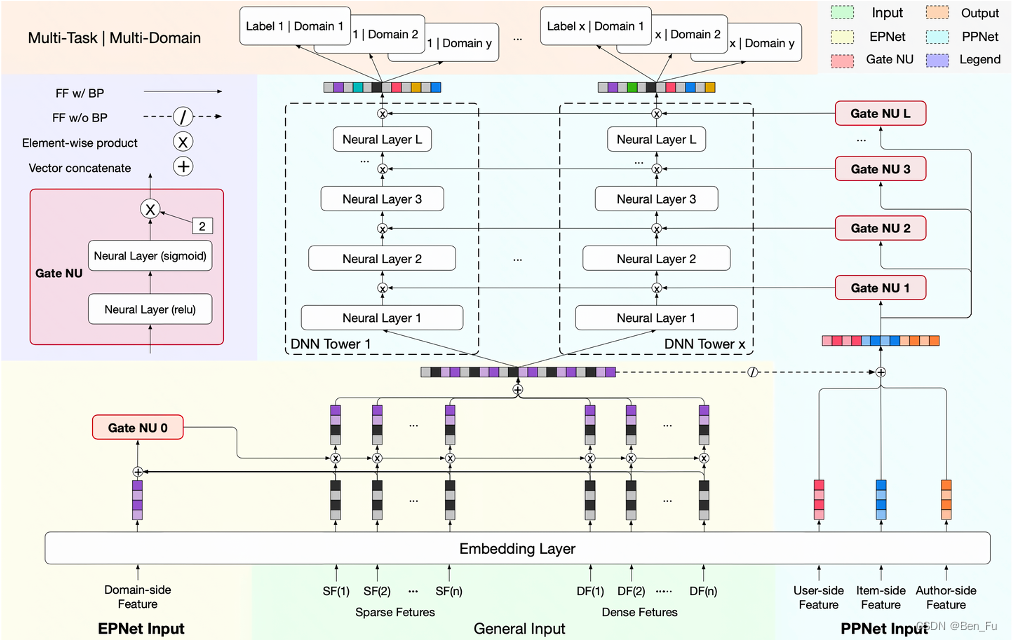
-
- 行为数据超长、有噪音、用户多兴趣变化、时延要求 [9~11]。增加外部记忆模块: 如MIMN [9]和HPMN [11] 模型。但较为复杂,部署较难。
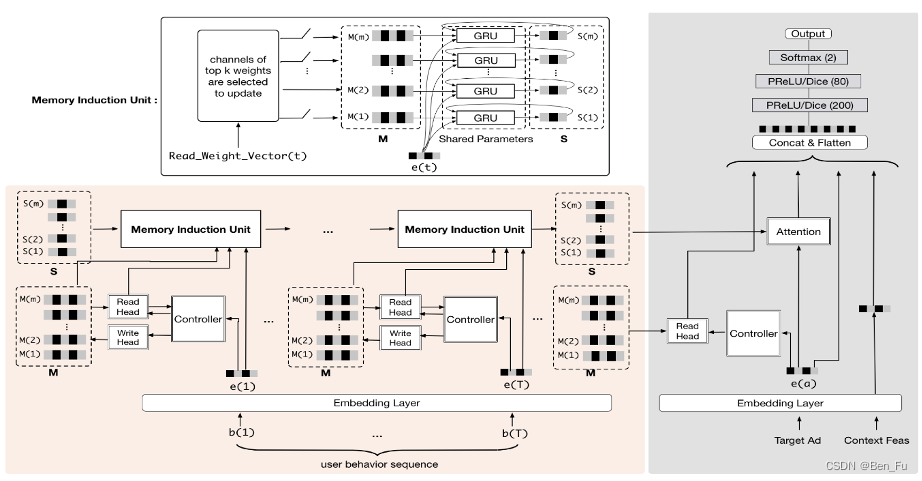
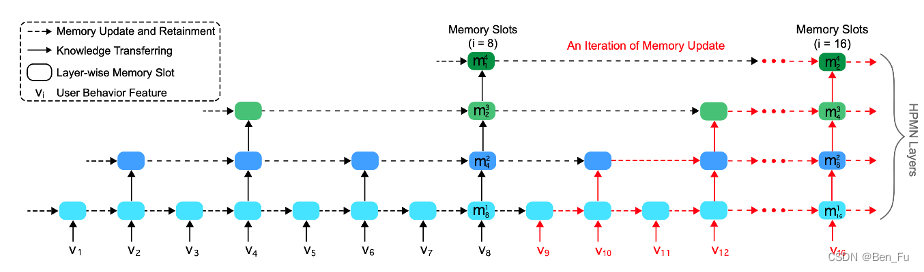
-
- 检索、采样和过滤模型 [12~17]
- SIM模型 [12] :Hard search(如类别关键词和tag等;简单)和Soft search(embedding检索)。
- 其他模型: 改进版本ETA(simhash) [13]、SDIM采样(hash attention)[14]、ADFM对抗过滤 [15]、TWIN两阶段粗搜和细搜 [16]。
- 检索、采样和过滤模型 [12~17]
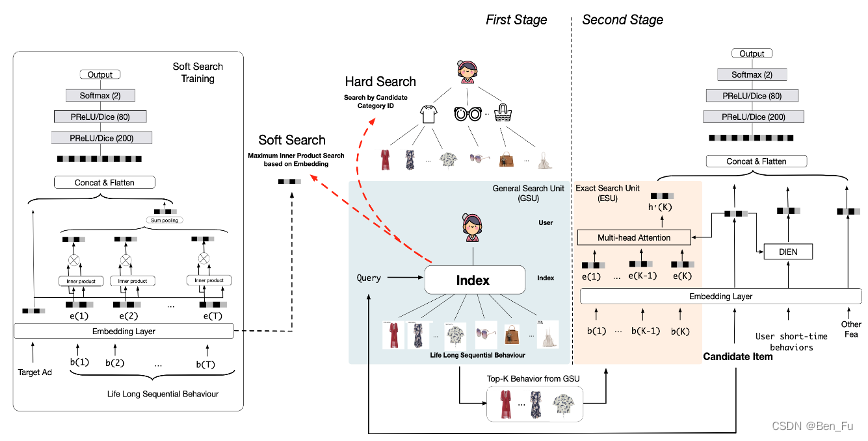
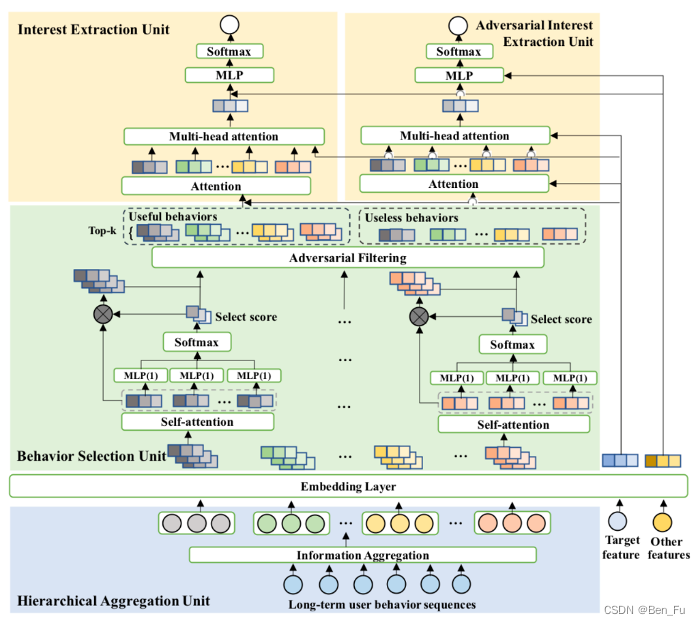
-
- Rec-Denoisers [18]:对注意力进行
正则化,并对正则化进行重参数化。
- Rec-Denoisers [18]:对注意力进行
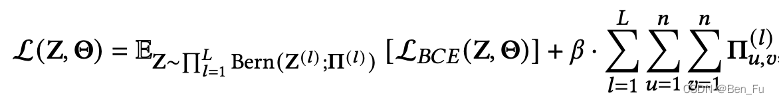
-
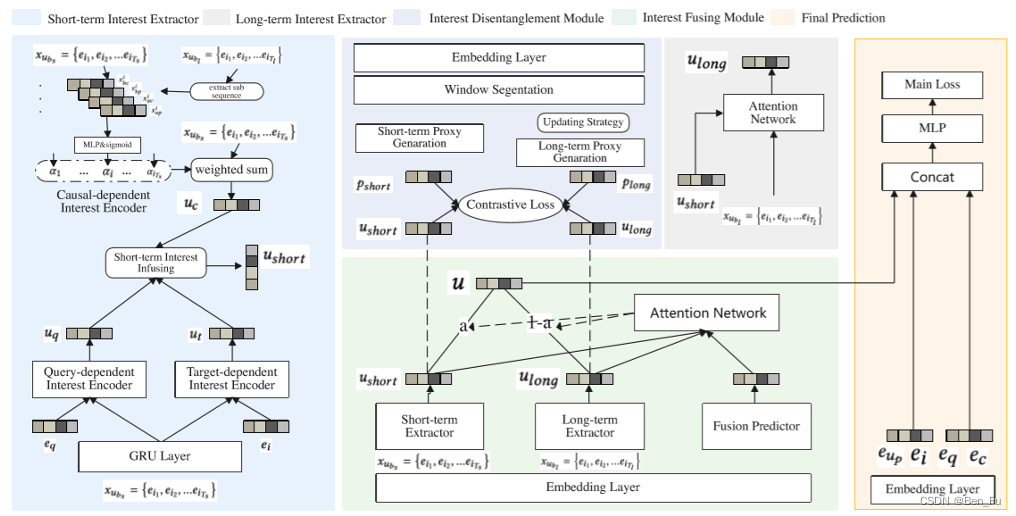
- 长短期偏好建模 [19~21]:
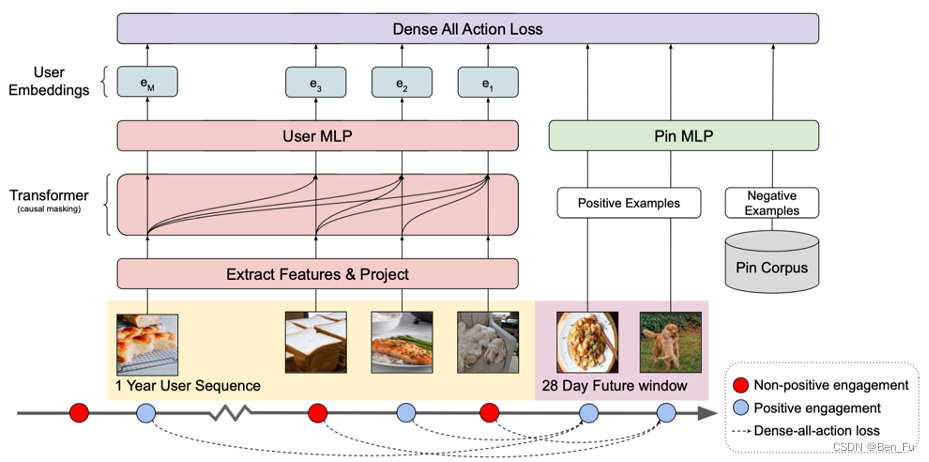
- HIFN [19]和PinnerFormer [20] :长短期偏好抽取分离。
- 长短期偏好建模 [19~21]:
-
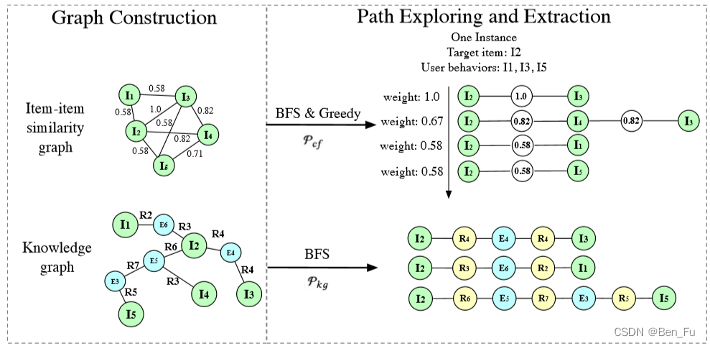
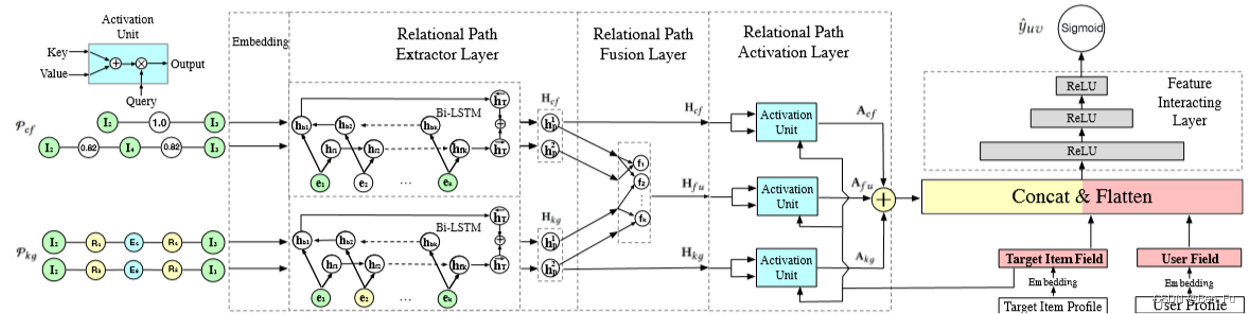
- 序列中物品关系建模:
- MTBRN [22] :融合物品相似度和知识图谱到达路径。
- HEROES [23]:利用Hawkes过程考虑用户的兴趣参与度。
- 序列中物品关系建模:
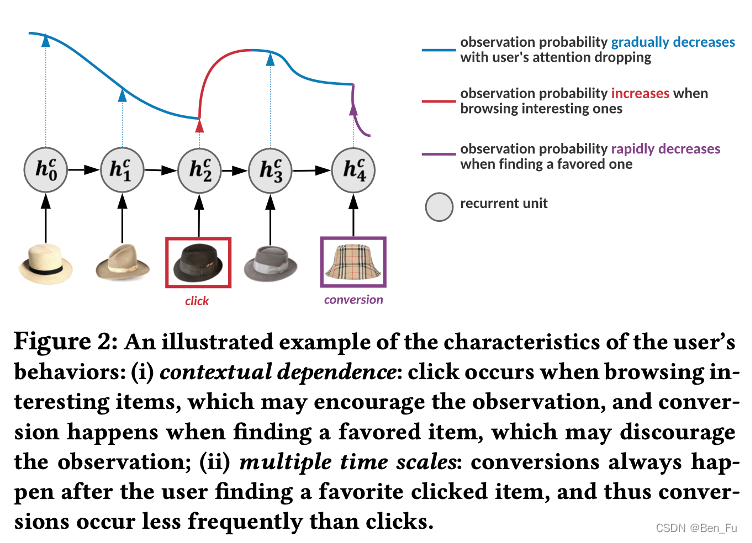
-
- 异质行为序列:
- 分开处理:
- DyMuS [24]:多个行为序列抽取融合到多兴趣路由。
- HPMR [25]:相邻级联行为类型向量之间进行投影分解共享向量和独有向量。
- 混合处理:
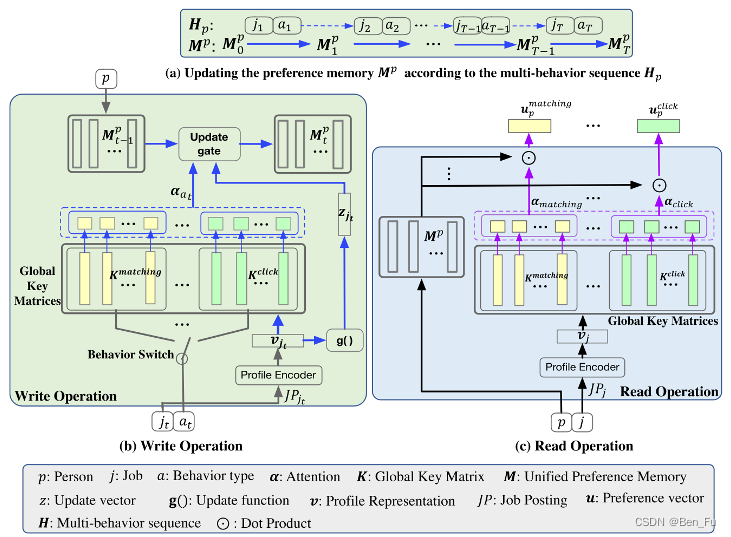
- DPJF-DBS [26]:构建多键值记忆网络来处理异质行为序列。
- 分开处理:
- 异质行为序列:
去偏
-
- 去偏排序学习 [27~33]
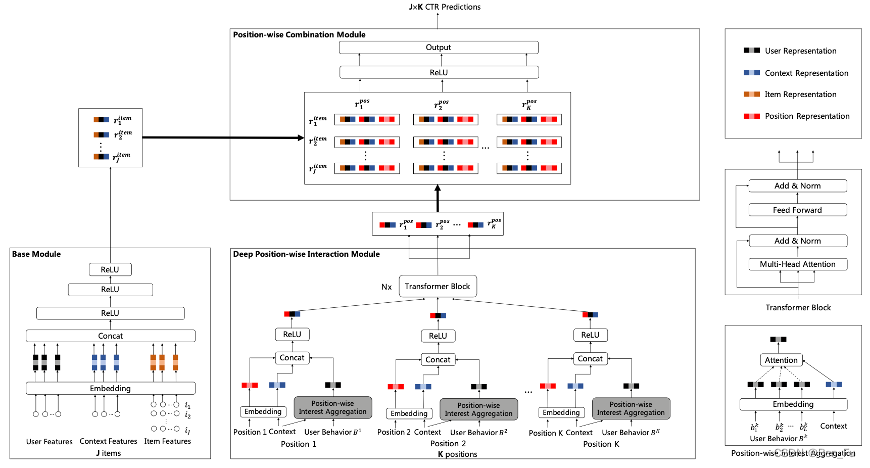
- 原理:物品点击概率同物品相关性和列表排序位置相关。
- DPIN [27]:同时考虑用户对物品和列表位置的兴趣。
- AutoDebias [28]:采用一小部分无偏数据和有偏数据(位置或从众)来学习偏执参数。
- 此外,排序学习要求不依赖于敏感属性,保证公平。利用一些手段如IPW/DW等去偏。
- 去偏排序学习 [27~33]
-
-
- PACC [34]:将位置信息作为输入特征。类似工作 [35]。
-
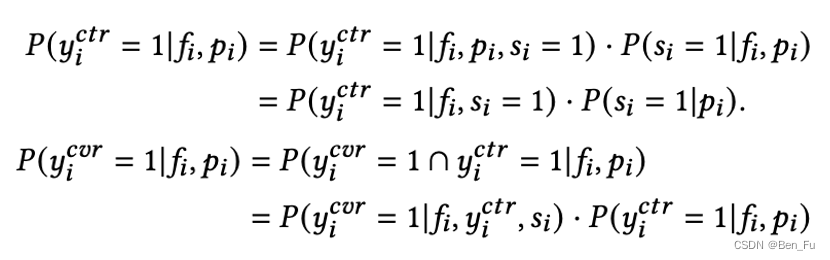
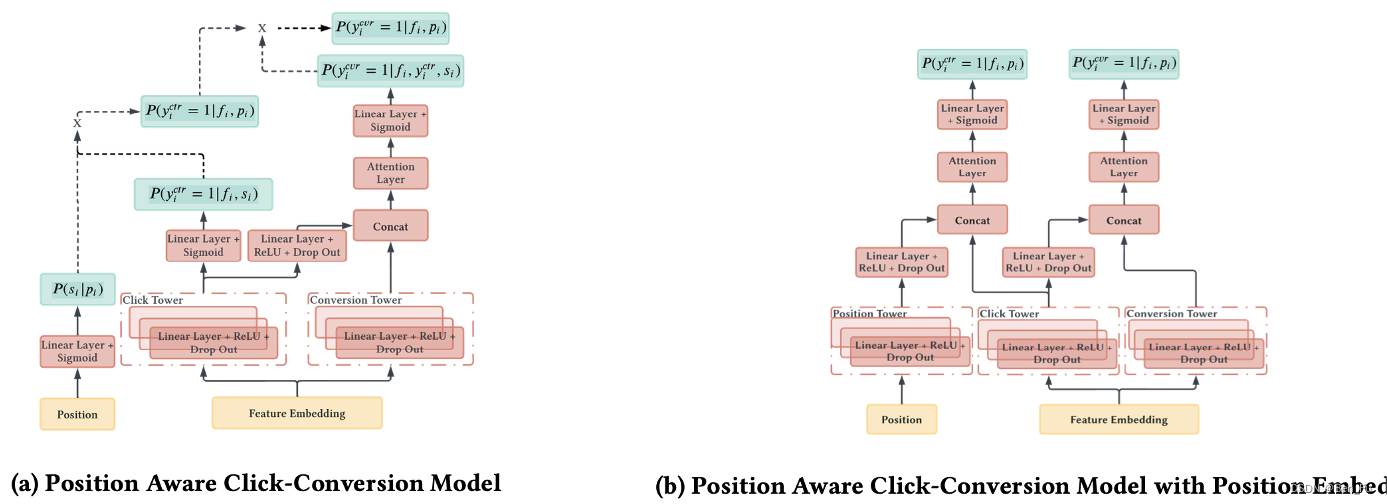
多场景多任务
-
- 多场景排序模型
- 原理:多场景,如上下游场景下不同任务。
- SATrans [36]:场景特征和通用特征,场景自适应注意力,不同场景下特征交叉重要性不同。
- 多场景排序模型
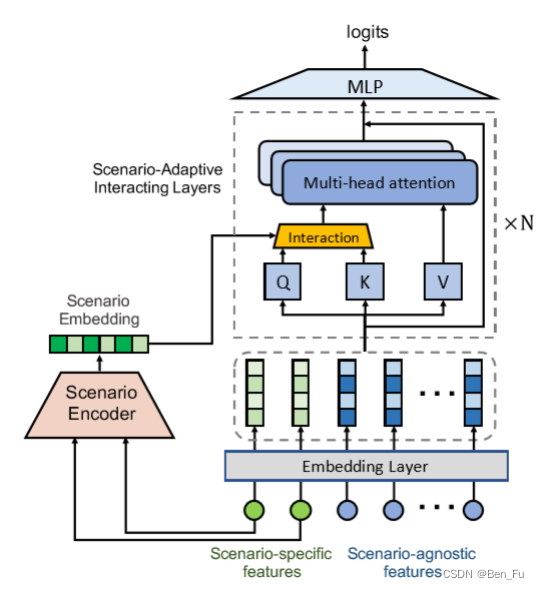
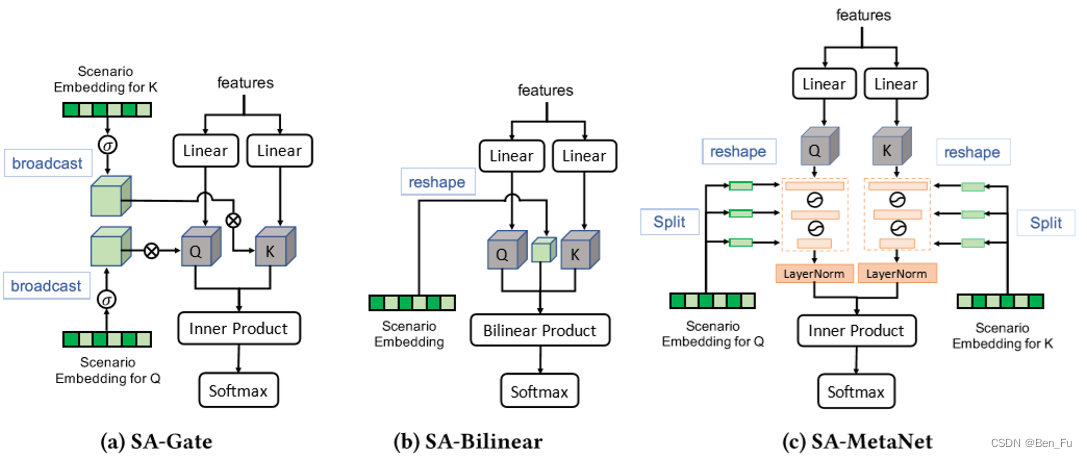
-
-
- OptMSM [37]:通过场景向量正交化约束实现场景特有和共享信息解耦。
-
-
-
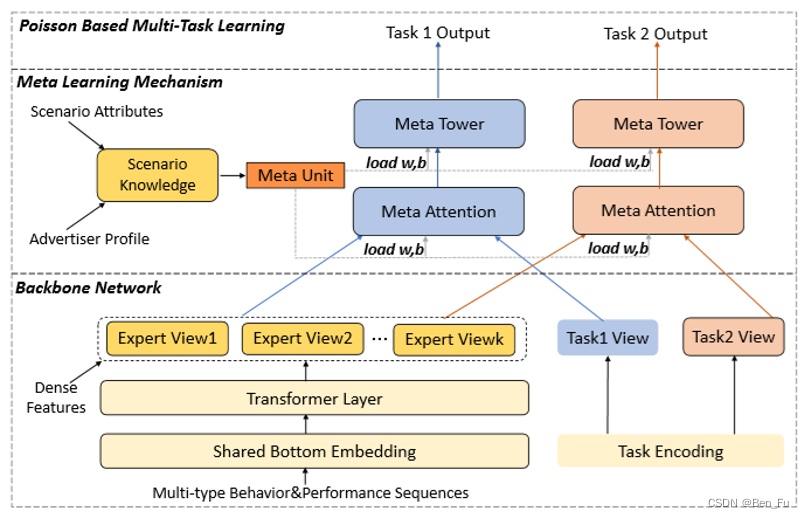
- M2M [38]:利用元学习来迁移场景内多任务信息。
-
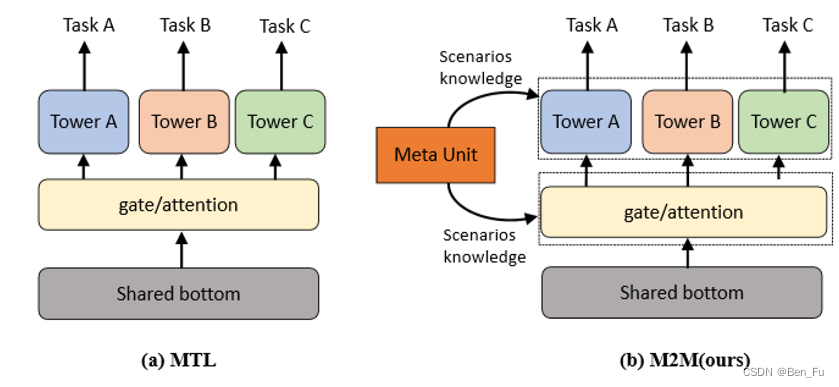
-
-
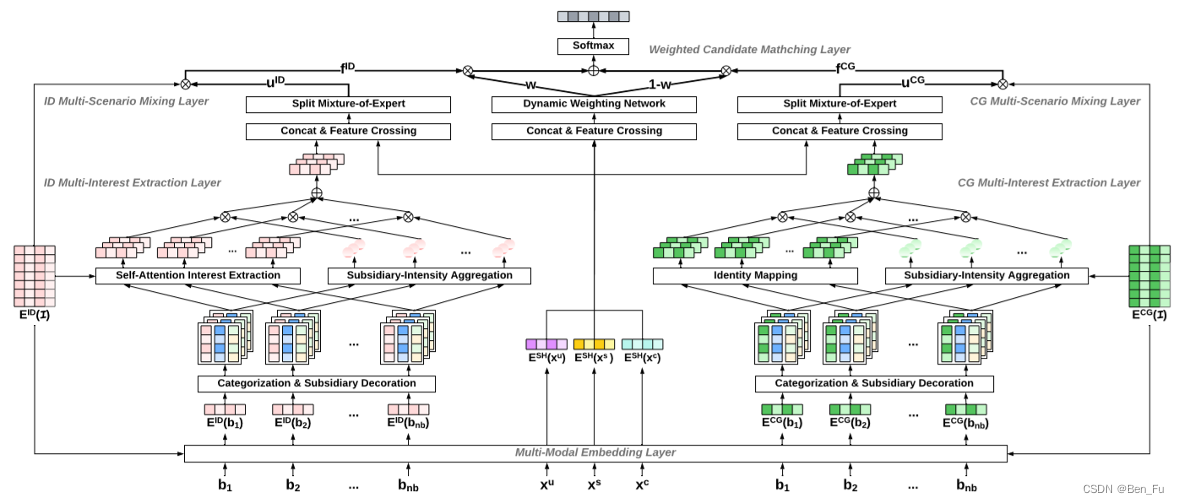
- M5 [39]:对多场景多模态多兴趣进行建模。
-
-
-
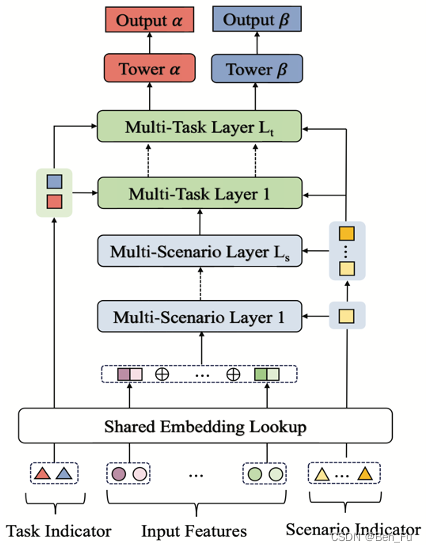
- AESM [40]:多任务多场景的层次结构建模。
-
-
-
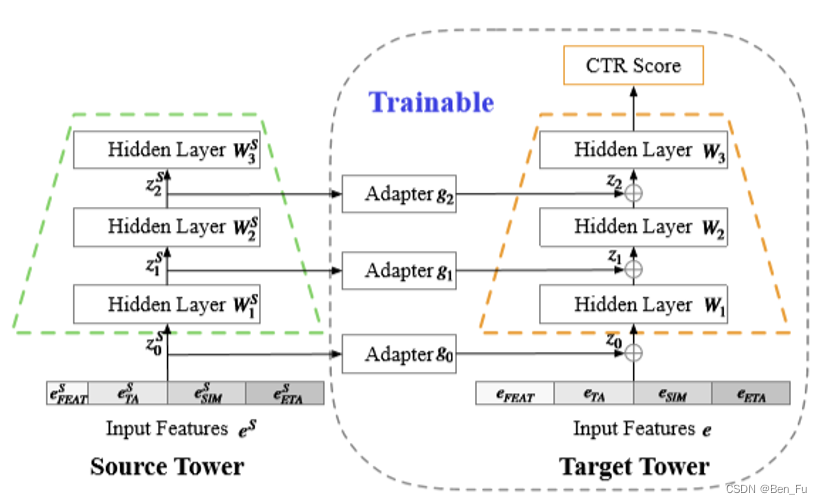
- 多任务塔之间构建更加高效的迁移通道 [41,42]。
-
-
-
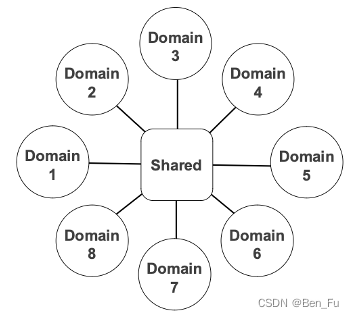
- STAR [43]:一个模型服务多个场景,充分利用用户在不同场景数据。
-
-
-
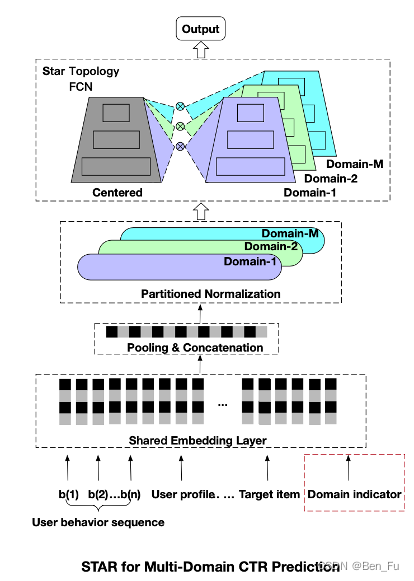
- HiNET [44]:层次(粗到细)抽取特征并在不同任务之间进行信息迁移。类似工作 [45].
-
模型结构
-
-
- 如何建模好任务之间的关系实现多个相关任务的知识迁移?
- 极化现象,可以采用dropout策略缓解。也存在跷跷板问题。
- 设计不同的网络结构 [46~53]:MMOE [46]、PLE [47]、AdaTT [48]、ESMM [49]、AITM [50]。
- 如何建模好任务之间的关系实现多个相关任务的知识迁移?
-
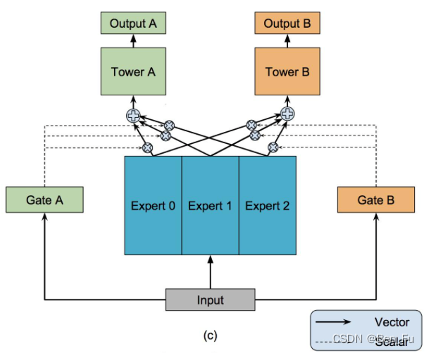
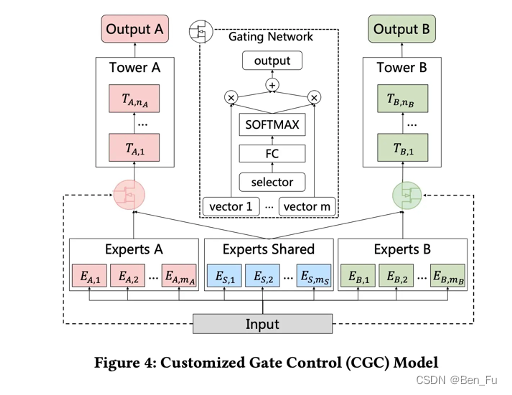
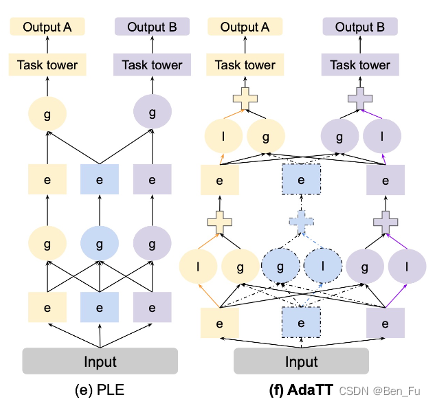
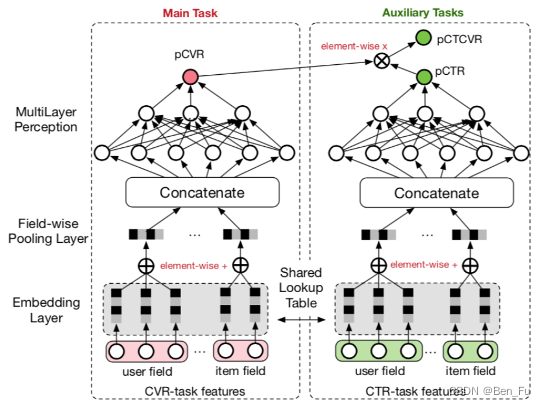
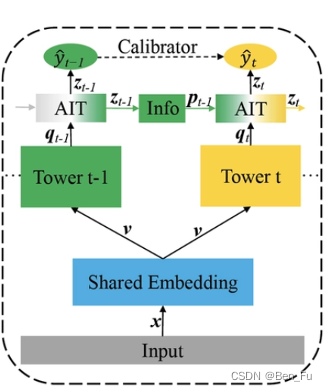
-
-
-
- 跷跷板问题:参数冲突问题,负迁移问题 [54~57]。
- CSRec [54]:不同任务对同参数存在竞争关系,根据其对参数影响程度来决定,每个任务有自己的mask(正)与其补码(负)的对比损失。
-
-
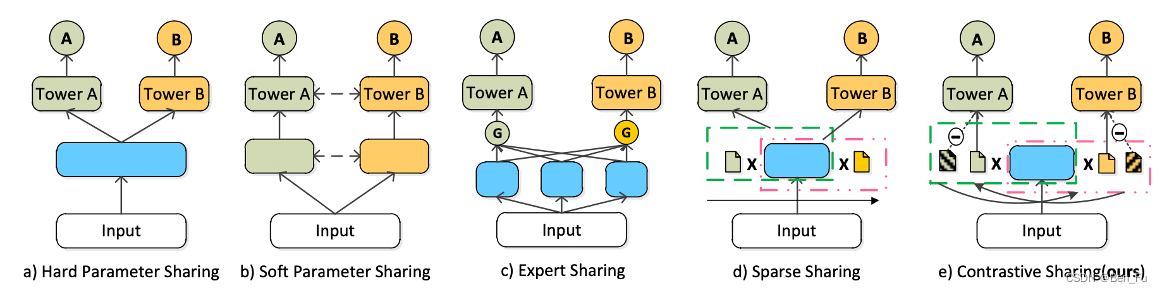
-
-
-
- MSSM [56]:每层内部进行改造,任务独有和任务共享。
- STEM [57]:任务共享模块和独享模块,门控部分阻止其他任务独享模块梯度后传。
-
-
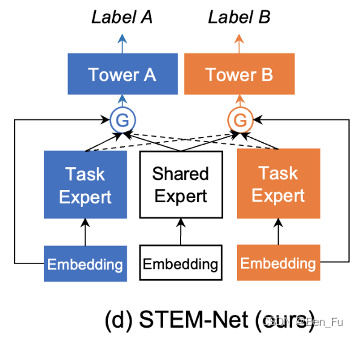
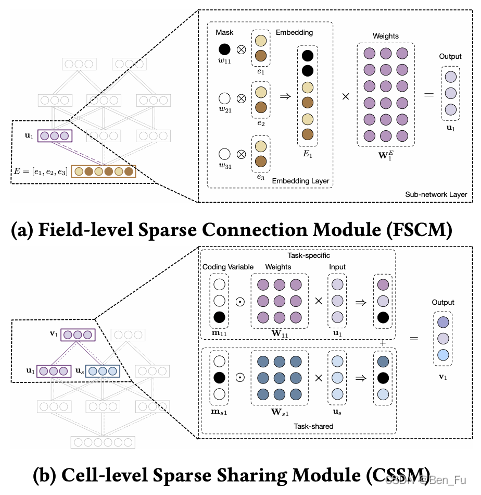
-
-
-
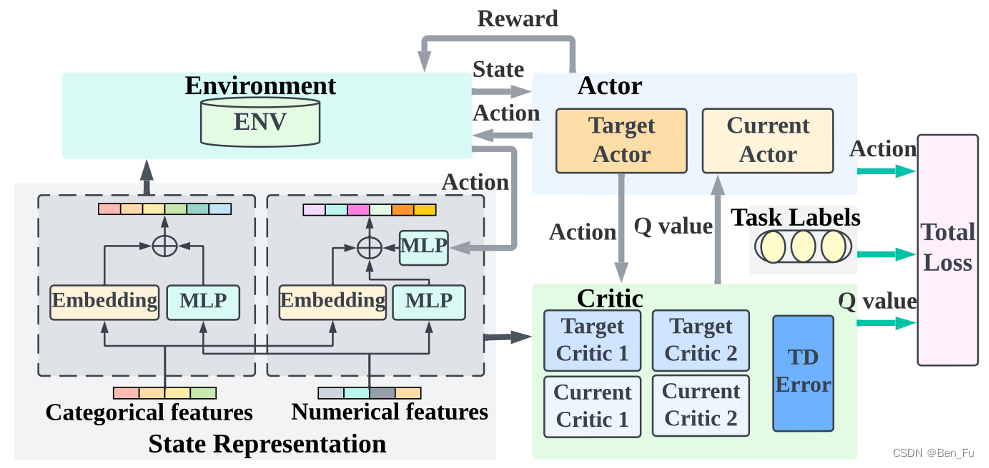
- RMTL [58]:多任务强化学习,一个actor多个critic。
-
-
-
-
-
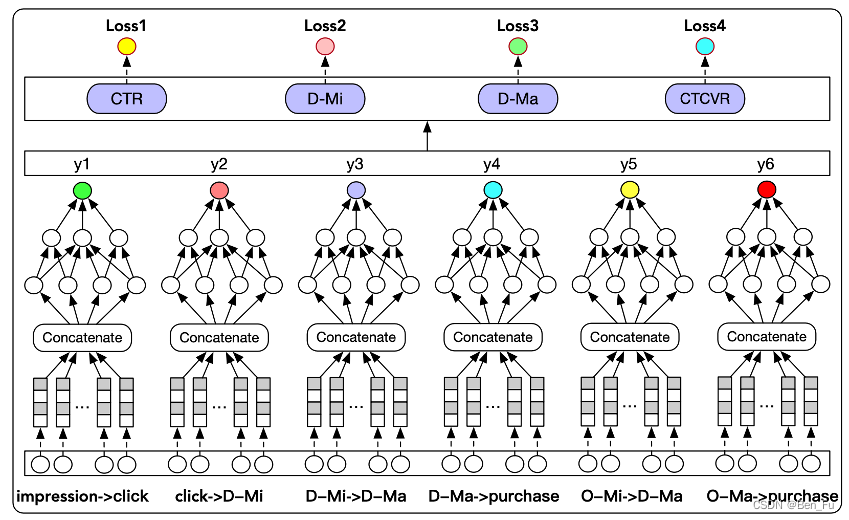
- HM^3 [59]:层次化建模宏观行为和微观行为的多任务学习(Mi表示停留时间-分钟)。
-
-
-
-
-
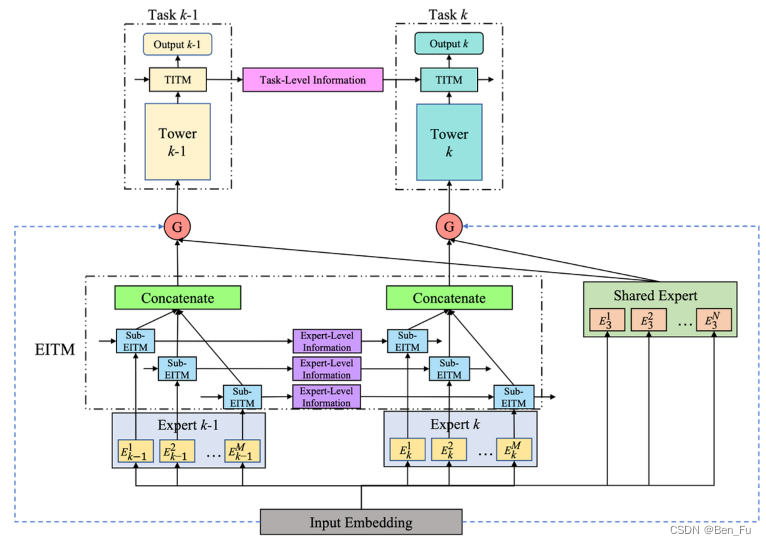
- MNCM [60]:级联任务建模。类似工作 [24]。
-
-
-
-
-
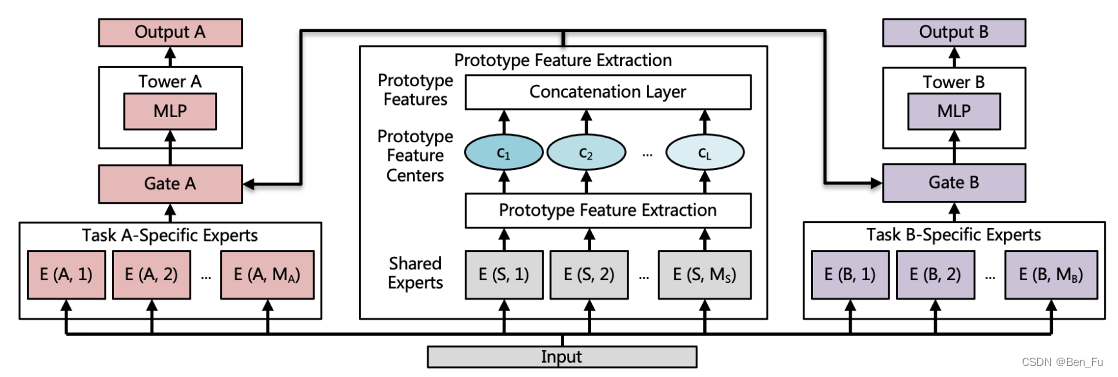
- PFE [61]:共享模块进行特征原型聚类。
-
-
多目标分数融合
-
- 多目标分数融合:尽管有多个任务,通常只有初次曝光一个列表,如何融合多个目标评分并给出曝光概率。比如BOSS直聘存在点击、查看、开聊和达成这四个任务 [24],需要一个函数对这四个任务的评分进行融合,基于此给出最终排序列表。采用计算方式如下:
- 加权求和(如电商):
- 级联相乘:
- 相乘:
或
- 排序融合:
- 参数调优:手工、贝叶斯搜索、分人群搜参、进化算法等来对上述公式中超参数进行调优,在线采用并行多个A/B测试寻找最优参数。
- 加权求和(如电商):
- 多目标分数融合:尽管有多个任务,通常只有初次曝光一个列表,如何融合多个目标评分并给出曝光概率。比如BOSS直聘存在点击、查看、开聊和达成这四个任务 [24],需要一个函数对这四个任务的评分进行融合,基于此给出最终排序列表。采用计算方式如下:
重排
-
- 多样性重排:
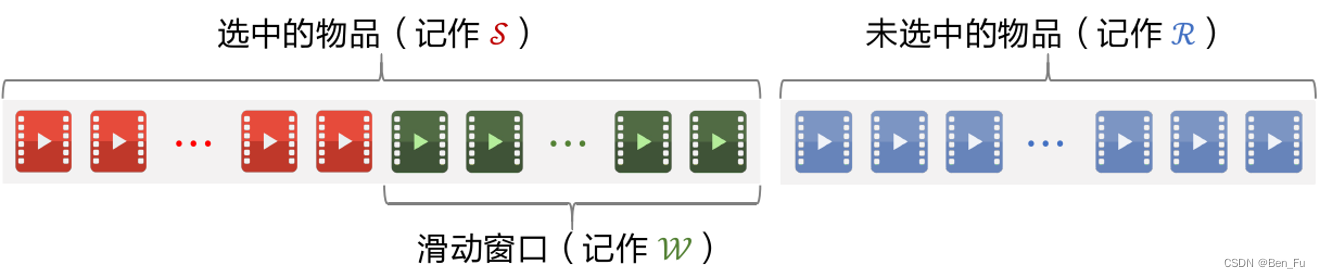
- Maximize Marginal Relevance滑动窗口算法:(精度和多样性)
- 原理:
, 𝑊表示最近选中的物品窗口。
- 已选中的物品初始化为空集,未选中的物品初始化为全集;
- 选择排序分数最高的一个物品,从未选中集合移到已选中集合。
- 重复k轮循环:
- 计算集合中所有物品的分数𝑀𝑅_𝑖;
- 选择分数最高的物品从未选中集合移到已选中集合;
- 原理:
- Maximize Marginal Relevance滑动窗口算法:(精度和多样性)
- 多样性重排:
-
-
-
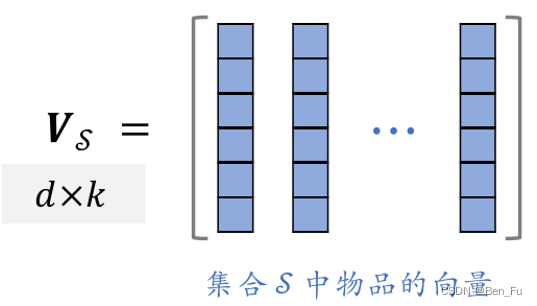
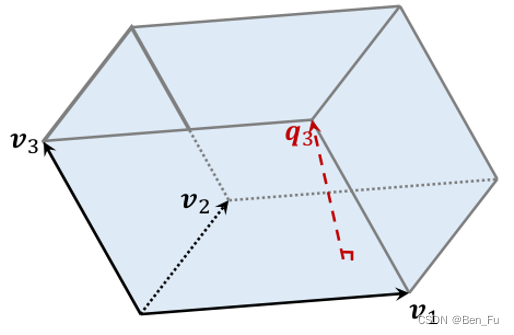
- 点行列式(DPP)算法 [62]
- 原理:行列式等于多维向量围成立体体积的平方
,问题等价于
,最终问题转化为
。也可采用滑动窗口方法。
- 原理:行列式等于多维向量围成立体体积的平方
- 点行列式(DPP)算法 [62]
-
-
- 规则重排
- 规则1:每10条曝光插入一条广告;
- 规则2:每五个位置换一个种物品推荐;
- 规则重排
……
-
- 学习模型重排 [63~67]
-
- 推荐列表级优化。
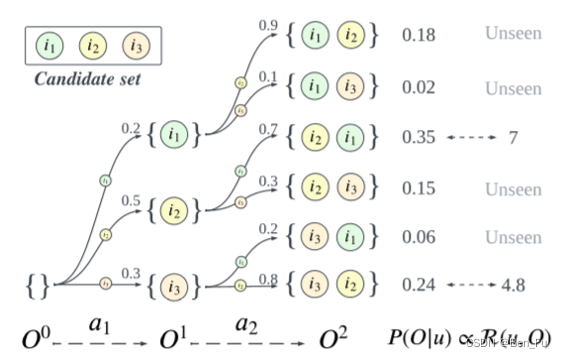
- GFN4Rec [64]:采用强化学习来进行列表排序(决策轨迹生成概率),同时考虑精度和多样性。
-
-
- CRUM [65]:类似LamdaLoss(NDCG)计算正负点击样本对交换后列表排序的效果增益(推荐场景还可考虑物品价格、广告场景还可考虑广告竞价)。
-
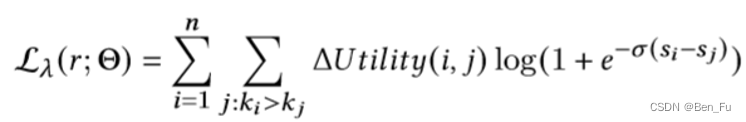
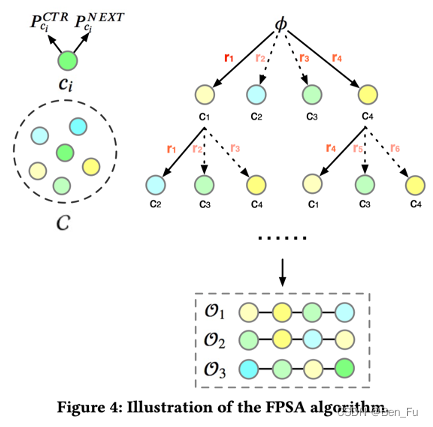
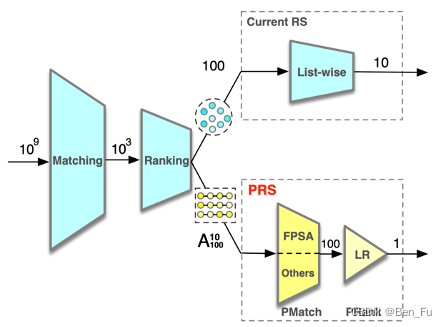
-
-
- GRN [68]:采用生成对抗来生成最终重排列表,先训练评估器预测点击概率,再利用生成器学习逐步生成最终列表的策略,两阶段联合优化训练。
-
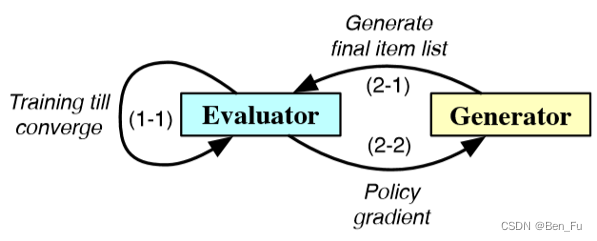
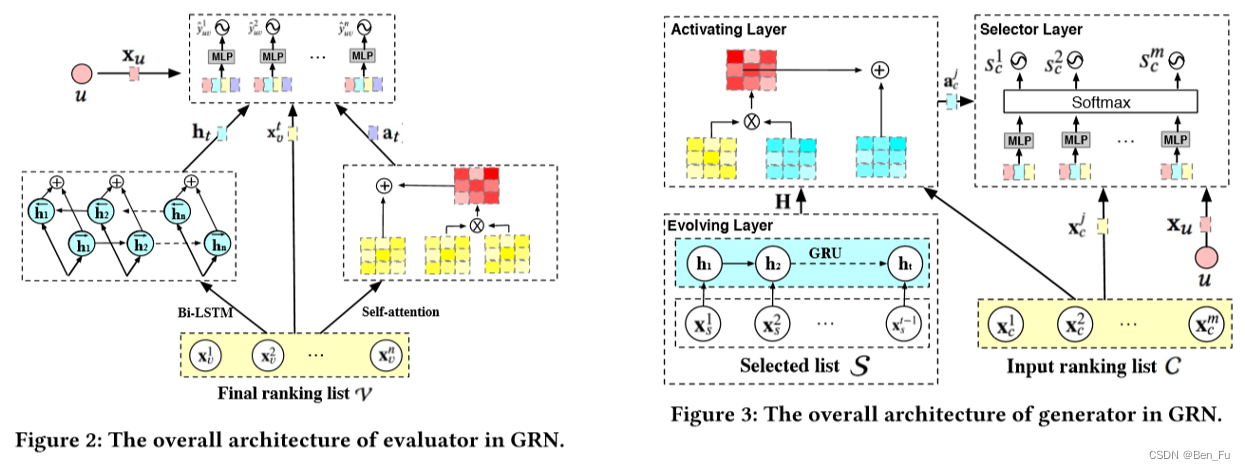
-
-
- PEAR [69]:充分考虑历史物品、推荐列表中物品之间的交叉关系。
-
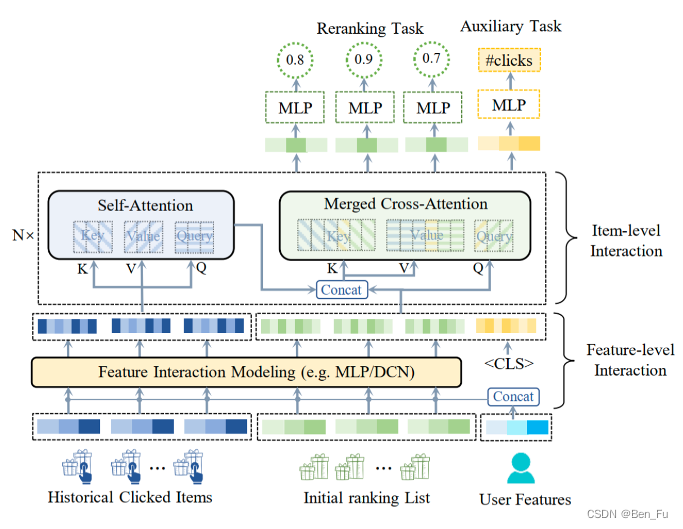
-
-
- RAPID [70]:考虑不同话题下的物品交叉。类似工作 [71,72]。
-
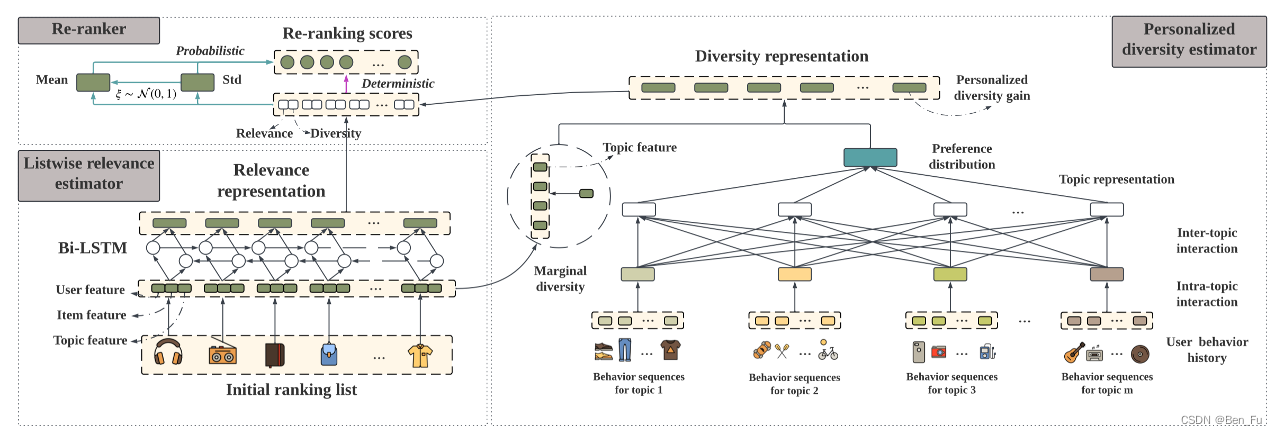
-
-
- RankFormer [73]:利用transformer建模列表物品关系及其整体质量。
-
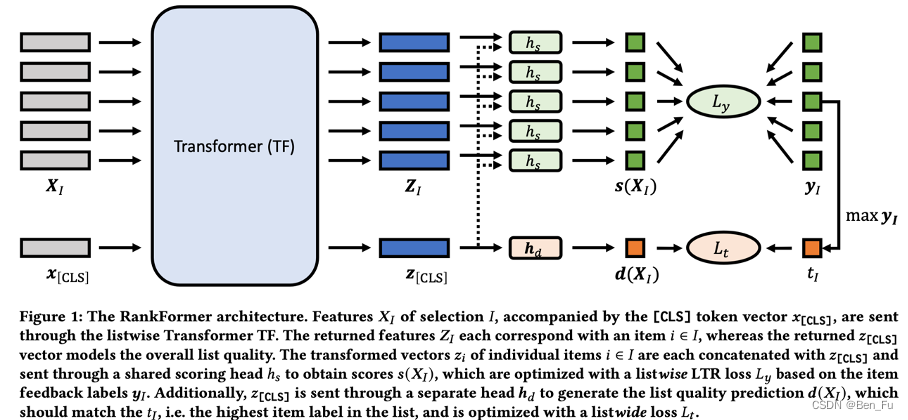
-
-
- PIER [74]:考虑历史行为和列表上下文信息。
-
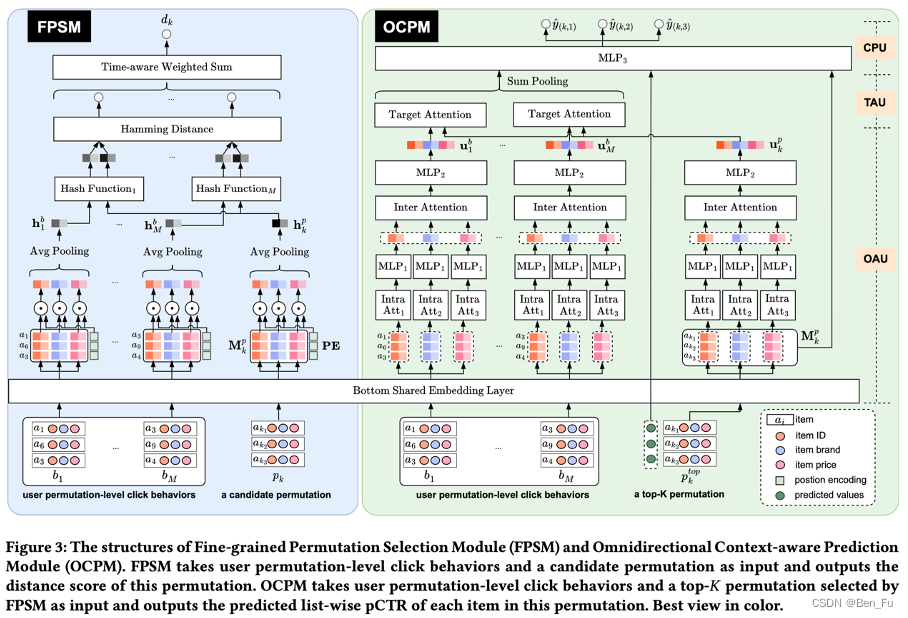
-
-
- MPAD [75]:采用DPP方法同时建模精度和多样性。
-
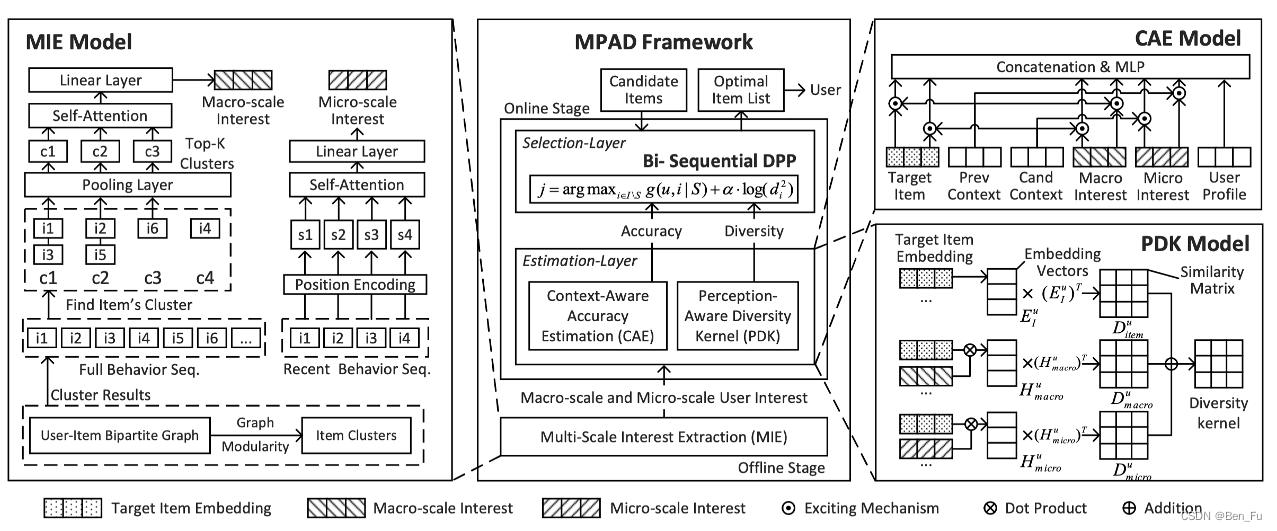
-
-
- APG [76]:不同用户的特征分布模式不同,可为不同的用户生成不同的模型参数。
- AutoFAS [77] 和NAS-CTR [78]:使用神经网络结构搜索( NAS )来寻找合适网络结构。
-
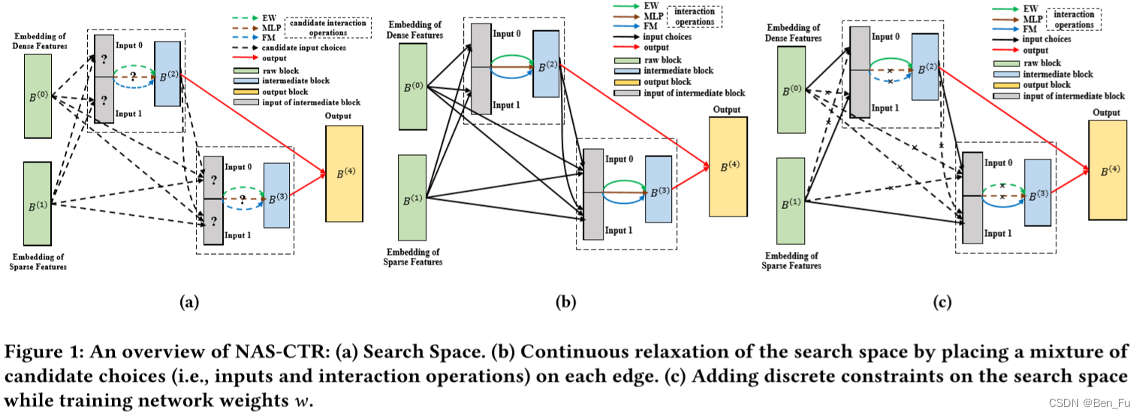
-
-
- CMR [79]:采用一个超网络来生成用户的线上的增量参数。
-
模型训练
-
- 模型训练
- 正负样本:
- 正样本为点击的物品。
- 负样本为未点击的物品,包括曝光和非曝光(比如某些场景下同类物品),负采样。
- 模型训练稳定性:
- 梯度裁剪 [80]。
- 正负样本:
- 集成模型
- XDBoost [81]:基于前一次模型预测结果作为新特征及boost训练。
- 模型训练
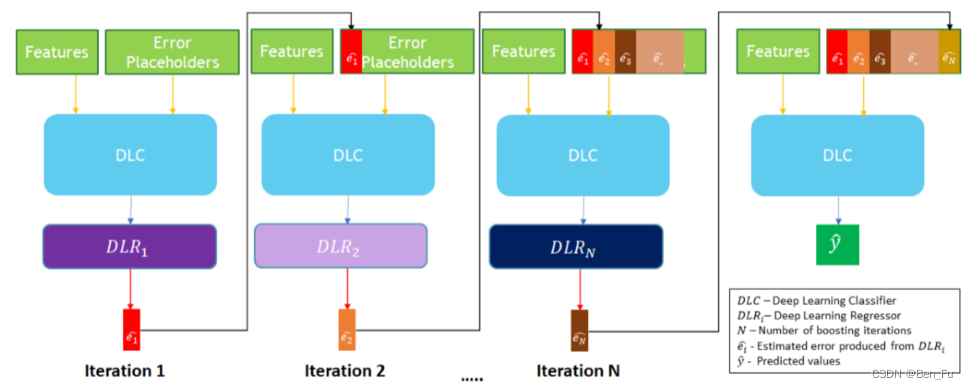
-
-
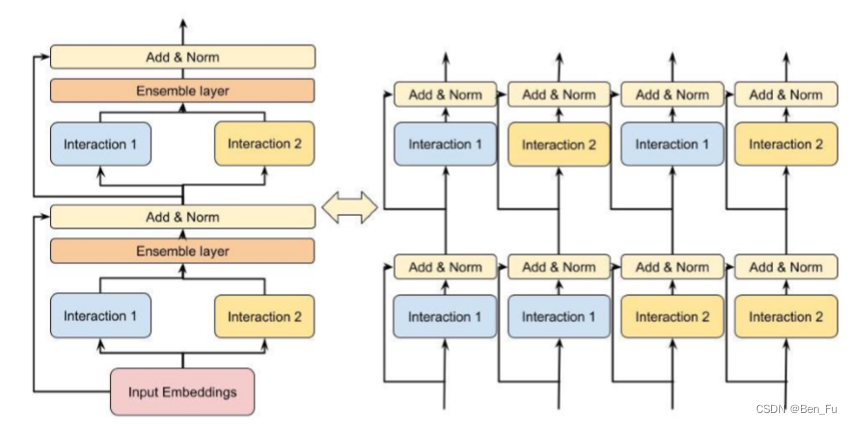
- DHEN [82]和AdaEnsemble [83]:迭代进行特征交叉。
-
未来研究探索方向
总结未来探索方向如下[84,85]:
- 多任务负迁移问题
- 多场景多任务
- 结合大语言模型
- 结构搜索问题(包括简化模型)
- 可解释性问题
- 公平和去偏
- 长尾物品和新用户问题
- 未来价值归因
[1] A Survey on User Behavior Modeling in Recommender Systems, 2023.
[2] Deep interest network for click-through rate prediction, KDD,2018.
[3] DIEN: Deep Interest Evolution Network for Click-Through Rate Prediction, AAAI 2018.
[4] SASRec: Self-attentive Sequential Recommendation, ICDM 2018.
[5] BSTransformer: Behavior Sequence Transformer for E-commerce Recommendation in Alibaba, 2019.
[6] Deep Session Interest Network for Click-Through Rate Prediction, IJCAI 2019.
[7] Learning to Retrieve User Behaviors for Click-through Rate Estimation, TIOS 2023.
[8] PEPNet: Parameter and Embedding Personalized Network for Infusing with Personalized Prior Information, KDD 2023.
[9] Practice on long sequential user behavior modeling for click-through rate prediction, KDD 2019.
[10] Lifelong sequential modeling with personalized memorization for user response prediction, SIGIR 2019.
[11] Sparse Attentive Memory Network for Click-through Rate Prediction with Long Sequences, CIKM 2022.
[12] Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction, 2020.
[13] End-to-End User Behavior Retrieval in Click-Through Rate Prediction Model, 2021.
[14] Sampling Is All You Need on Modeling Long-Term User Behaviors for CTR Prediction, CIKM 2022.
[15] Adversarial Filtering Modeling on Long-term User Behavior Sequences for Click-Through Rate Prediction, SIGIR 2022.
[16] TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou, KDD 2023.
[17] Divide and Conquer: Towards Better Embedding-based Retrieval for Recommender Systems from a Multi-task Perspective, WWW 2023.
[18] Denoising Self-Attentive Sequential Recommendation, RS 2022.
[19] Hierarchically Fusing Long and Short-Term User Interests for Click-Through Rate Prediction in Product Search, CIKM 2022.
[20] Rethinking Personalized Ranking at Pinterest: An End-to-End Approach, RS 2022.
[21] Page-Wise Personalized Recommendations in an Industrial e-Commerce Setting, RS 2022.
[22] MTBRN: Multiplex Target-Behavior Relation Enhanced Network for Click-Through Rate Prediction, CIKM 2020.
[23] Multi-Scale User Behavior Network for Entire Space Multi-Task Learning, CIKM 2022.
[24] Dynamic Multi-Behavior Sequence Modeling for Next Item Recommendation, AAAI 2023.
[25] Hierarchical Projection Enhanced Multi-behavior Recommendation, KDD 2023.
[26] Beyond Matching: Modeling Two-Sided Multi-Behavioral Sequences for Dynamic Person-Job Fit, DASFAA 2021.
[27] Deep Position-wise Interaction Network for CTR Prediction, SIGIR 2021.
[28] AutoDebias: Learning to Debias for Recommendation, SIGIR 2021.
[29] Unbiased Learning to Rank: Online or Offline?, TIOS 2020.
[30 ]Fair pairwise learning to rank, 2020.
[31] CAM2: Conformity-Aware Multi-Task Ranking Model for Large-Scale Recommender Systems, WWW 2023.
[32] Entire Space Cascade Delayed Feedback Modeling for Effective Conversion Rate Prediction, CIKM 2023.
[33] ESMC: Entire Space Multi-Task Model for Post-Click Conversion Rate via Parameter Constraint, 2023.
[34] Click-Conversion Multi-Task Model with Position Bias Mitigation for Sponsored Search in eCommerce, SIGIR 2023.
[35] DCMT: A Direct Entire-Space Causal Multi-Task Framework for Post-Click Conversion Estimation, ICDE 2023.
[36] Scenario-Adaptive Feature Interaction for Click-Through Rate Prediction, KDD 2023.
[37] OptMSM: Optimizing Multi-Scenario Modeling for Click-Through Rate Prediction, 2023.
[38] Leaving No One Behind: A Multi-Scenario Multi-Task Meta Learning Approach for Advertiser Modeling, WSDM 2022.
[39] M5: Multi-Modal Multi-Interest Multi-Scenario Matching for Over-the-Top Recommendation, KDD 2023.
[40] Automatic Expert Selection for Multi-Scenario and Multi-Task Search, SIGIR 2022.
[41] Continual Transfer Learning for Cross-Domain Click-Through Rate Prediction at Taobao, WWW 2023.
[42] Cross-domain Augmentation Networks for Click-Through Rate Prediction, 2023.
[43] One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction, CIKM 2021.
[44] HiNet: Novel Multi-Scenario & Multi-Task Learning with Hierarchical Information Extraction, ICDE 2023.
[45] Multi-Faceted Hierarchical Multi-Task Learning for Recommender Systems, CIKM 2022.
[46] Large Scale Product Graph Construction for Recommendation in E-commerce, 2020.
[47] Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations, RS 2020.
[48] AdaTT: Adaptive Task-to-Task Fusion Network for Multitask Learning in Recommendations, KDD 2023.
[49] Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate, SIGIR 2018.
[50] Modeling the Sequential Dependence among Audience Multi-step Conversions with Multi-task Learning in Targeted Display Advertising, KDD 2021.
[51] Advances and Challenges of Multi-task Learning Method in Recommender System: A Survey, 2023.
[52] Multi-Objective Recommender Systems: Survey and Challenges, RS 2022.
[53] Optimizing Airbnb Search Journey with Multi-task Learning, KDD 2023.
[54] A Contrastive Sharing Model for Multi-Task Recommendation, WWW 2022.
[55] Adaptive Pattern Extraction Multi-Task Learning for Multi-Step Conversion Estimations, 2023.
[56] MSSM: A Multiple-level Sparse Sharing Model for Efficient Multi-Task Learning, SIGIR 2021.
[57] STEM: Unleashing the Power of Embeddings for Multi-task Recommendation, 2024.
[58] Multi-Task Recommendations with Reinforcement Learning, WWW 2023.
[59] Hierarchically Modeling Micro and Macro Behaviors via Multi-Task Learning for Conversion Rate Prediction, SIGIR 2021.
[60] MNCM: Multi-level Network Cascades Model for Multi-Task Learning, CIKM 2022.
[61] Prototype Feature Extraction for Multi-task Learning, WWW 2022.
[62] Fast greedy map inference for determinantal point process to improve recommendation diversity, NIPS 2018.
[63] Neural Re-ranking in Multi-stage Recommender Systems: A Review, 2022.
[64] Generative Flow Network for Listwise Recommendation, KDD 2023.
[65] Context-aware Reranking with Utility Maximization for Recommendation, 2022.
[66] Revisit Recommender System in the Permutation Prospective, 2021.
[67] Entire Cost Enhanced Multi-Task Model for Online-to-Offline Conversion Rate Prediction, 2022.
[68] GRN: Generative Rerank Network for Context-wise Recommendation, 2021.
[69] PEAR: Personalized Re-ranking with Contextualized Transformer for Recommendation, WWW 2022.
[70] Personalized Diversification for Neural Re-ranking in Recommendation, ICDE 2023.
[71] Multi-Level Interaction Reranking with User Behavior History, SIGIR 2022.
[72] Slate-Aware Ranking for Recommendation, WSDM 2023.
[73] RankFormer: Listwise Learning-to-Rank Using Listwide Labels, kdd 2023.
[74] PIER: Permutation-Level Interest-Based End-to-End Re-ranking Framework in E-commerce, KDD 2023.
[75] Multi-factor Sequential Re-ranking with Perception-Aware Diversification, KDD 2023.
[76] APG: Adaptive Parameter Generation Network for Click-Through Rate Prediction, NIPS 2022.
[77] AutoFAS: Automatic Feature and Architecture Selection for Pre-Ranking System, 2022.
[78] NAS-CTR: Efficient Neural Architecture Search for Click-Through Rate Prediction, SIGIR 2022.
[79] Controllable Multi-Objective Re-ranking with Policy Hypernetworks, KDD 2023.
[80] Improving Training Stability for Multitask Ranking Models in Recommender Systems, KDD 2023.
[81] Iterative Boosting Deep Neural Networks for Predicting Click-Through Rate, 2020.
[82] DHEN: A Deep and Hierarchical Ensemble Network for Large-Scale Click-Through Rate Prediction, KDD 2022.
[83] AdaEnsemble: Learning Adaptively Sparse Structured Ensemble Network for Click-Through Rate Prediction, 2022.
[84] Multi-Task Deep Recommender Systems: A Survey, 2023.
[85] Expressive user embedding from churn and recommendation multi-task learning, WWW 2023.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









