







今天又重新学习了java基础类中的集合,那么就总结了一些常用的集合类那么为什么需要集合类呢?原因其实很简单,因为java中不能动态的创建大小自动扩大的数组,那么我们的集合类就很好的解决了这样的问题。
首先总结了一个思维导图有助于自己理解。
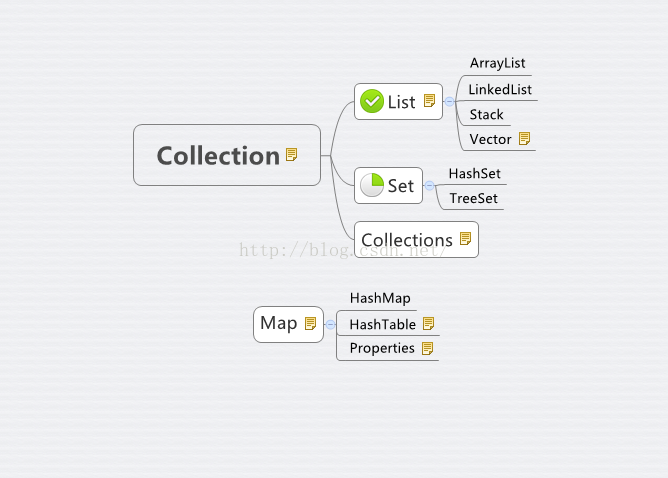
java中定义了Collection接口,List和Set接口继承了Collection接口。然后ArrayList、LinkedList、Vector、Stack实现了List接口。并且HashSet、TreeSet实现了Set接口。同样java基础类中还包含图Map。Map主要是以键值对的形式存在的。它的实现类主要包括HashMap和HashTable。
List和Set最大的区别则是List中可以重复存储某一个元素,而Set则不允许存储重复的元素。
1.接下来我就先总结一下List接口的实现类:
ArrayList我喜欢称他为数组链表,因为其在内存中存储的地址和数组一样是连续的。
LinkList我喜欢称他为链式链表,因为其在内存中存储的地址是不连续的,是靠引用指向来寻找元素的。
Vector我喜欢称他为向量量表,他和ArrayList的用法几乎一致。他们的区别主要用两种:
1)Vector是线程安全的,而ArrayList是线程不安全的,LinkList同样也是线程不安全的。
2)ArrayList扩大链表长度时是扩大原来的50%,而Vector扩大原来链表长度的一倍,所以如果我们存储较大数据量的时候选择Vector来存储是最佳的。
那么我们如何才能正确的使用我们的集合类来使我们的程序更安全更节省空间和内存呢?
1)如果我们存储对象更多的是用来查找很少进行增删改,并且不要求线程安全,那么ArrayList是你最好的选择。
2)如果我们存储对象需要经常进行增删改很少需要查,并且不要线程安全,那么LinkList是你最好的选择。
3)如果我们的存储对象数量很多,而且要求线程安全,那么Vector是你最好的选择。
接下来是java的一些实例代码有助于理解:
首先这是存储的对象:
package com.yd.bean;
/**
* 基础类:用于存储
* */
//这是一个员工类
public class Employee implements Comparable{
private String name;
private int age;
private String num;
//构造函数
public Employee(){
}
public Employee(String name,int age,String num){
this.name=name;
this.age=age;
this.num=num;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getNum() {
return num;
}
public void setNum(String num) {
this.num = num;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
result = prime * result + ((num == null) ? 0 : num.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Employee other = (Employee) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
if (num == null) {
if (other.num != null)
return false;
} else if (!num.equals(other.num))
return false;
return true;
}
@Override
public String toString() {
return "Employee [name=" + name + ", age=" + age + ", num=" + num + "]";
}
@Override
public int compareTo(Object o) {
//首先将o强制转换成Employee
Employee employee=(Employee) o;
if (this.getAge()>employee.getAge()) {
return 1;
}else if(this.getAge()==employee.getAge()){
return 0;
}else{
return -1;
}
}
}
package com.yd.collection;
import java.util.ArrayList;
import java.util.List;
import com.yd.bean.Employee;
//该类用于测试各种集合类
public class Test_Collection_ArrayList {
//程序的入口
public static void main(String[] args) {
//创建一个数组链表 数组链表是实现了List接口 List接口继承了Collection接口
List list=new ArrayList();
//循环创建四个员工类
for(int i=0;i<4;i++){
//创建一个员工类
Employee employee=new Employee("张"+(i+1),i+10,"20130"+i);
//将员工类添加到数组链表中
list.add(employee);
//添加两次 检测数组链表中是否允许存放相同对象
list.add(employee);
}
//往数组链表中添加一个员工 检测数组链表中是否允许存放相同对象
/*list.add(new Employee("张2",11,"201301"));*/
//循环显示数组链表中的员工实例
for(int j=0;j<list.size();j++){
Employee employee=(Employee) list.get(j); //get方法获得是object类型的对象 需要强制转换一下
System.out.println(employee);
}
//输出结果如下 :
/*Employee [name=张1, age=10, num=201300]
Employee [name=张1, age=10, num=201300]
Employee [name=张2, age=11, num=201301]
Employee [name=张2, age=11, num=201301]
Employee [name=张3, age=12, num=201302]
Employee [name=张3, age=12, num=201302]
Employee [name=张4, age=13, num=201303]
Employee [name=张4, age=13, num=201303]*/
list.remove(7);
System.out.println(list.size());
}
}package com.yd.collection;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import com.yd.bean.Employee;
//链式链表类
public class Test_Collection_LinkedList {
//程序入口
public static void main(String[] args) {
//创建一个数组链表 数组链表是实现了List接口 List接口继承了Collection接口
List list=new LinkedList();
//循环创建四个员工类
for(int i=0;i<4;i++){
//创建一个员工类
Employee employee=new Employee("张"+(i+1),i+10,"20130"+i);
//将员工类添加到数组链表中
list.add(employee);
//添加两次 检测数组链表中是否允许存放相同对象
list.add(employee);
}
//往数组链表中添加一个员工 检测数组链表中是否允许存放相同对象
/*list.add(new Employee("张2",11,"201301"));*/
//循环显示数组链表中的员工实例
for(int j=0;j<list.size();j++){
Employee employee=(Employee) list.get(j); //get方法获得是object类型的对象 需要强制转换一下
System.out.println(employee);
}
//输出结果如下 :
/*Employee [name=张1, age=10, num=201300]
Employee [name=张1, age=10, num=201300]
Employee [name=张2, age=11, num=201301]
Employee [name=张2, age=11, num=201301]
Employee [name=张3, age=12, num=201302]
Employee [name=张3, age=12, num=201302]
Employee [name=张4, age=13, num=201303]
Employee [name=张4, age=13, num=201303]*/
list.remove(7);
System.out.println(list.size());
}
}package com.yd.collection;
import java.util.Enumeration;
import java.util.List;
import java.util.Vector;
import com.yd.bean.Employee;
//向量链表
public class Test_Collection_Vector {
public static void main(String[] args) {
//创建一个项链链表
Vector list=new Vector();
//循环创建四个员工类
for(int i=0;i<4;i++){
//创建一个员工类
Employee employee=new Employee("张"+(i+1),i+10,"20130"+i);
//将员工类添加到数组链表中
list.add(employee);
//添加两次 检测数组链表中是否允许存放相同对象
list.add(employee);
}
//接下来 写一下Vector比其他的链表多的方法 主要多的是其枚举的方式
Enumeration enumeration= list.elements();
while(enumeration.hasMoreElements()){
Employee employee=(Employee) enumeration.nextElement();
System.out.println(employee);
}
}
}HashSet和TreeSet都是Set的实现类,共同点是他们存储对象不想链表那样按照存储的循序进行存放,而是没有循序的存放的。 但是他们的区别主要有两个:
1)HashSet中存储的对象是无序的,而TreeSet中的元素是有序的,但是前提是TreeSet中存储的对象都必须实现Comparable接口实现compareTo方法,这样才能保证TreeSet中的元素是按照某个规则存放的。
2)HashSet中可以存储一个null值,而TreeSet中是不可以存储null值的。
HashSet的Demo:
package com.yd.collection;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
import com.yd.bean.Employee;
//哈希集合类
public class Test_Collection_HashSet {
public static void main(String[] args) {
Set set=new HashSet();
//创建三个Employee
Employee employee1=new Employee("张1",22,"201301");
Employee employee2=new Employee("张2",22,"201302");
set.add(employee1);
//添加两次employee1
set.add(employee1);
set.add(employee2);
System.out.println(set.size()); //结果为2 也就是在set集合中不能存储重复的元素
set.add(null); //集合中可以添加一个null值
System.out.println(set.size());
//集合的迭代
Iterator iterator=set.iterator();
while(iterator.hasNext()){
Employee employee=(Employee) iterator.next();
System.out.println(employee);
}
//输出结果如下 可见set中元素的存放不是按照存储的循序进行存放的
/*null
Employee [name=张1, age=22, num=201301]
Employee [name=张2, age=22, num=201302]*/
}
}
package com.yd.collection;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeSet;
import com.yd.bean.Employee;
//树集类
public class Test_Collection_TreeSet {
public static void main(String[] args) {
//明确几点TreeSet和HashSet中都不能存在重复的元素
//区别主要有以下几点
//1.hashset中可以有null值而treeset中不循序存在null值
//2.hashset中的元素是无序的 treeset中的元素是有序的 前提条件是存入treeset中的元素必须要实现comparable接口
TreeSet treeSet=new TreeSet();
Employee employee1=new Employee("张1",22,"201301");
Employee employee2=new Employee("张2",26,"201302");
Employee employee3=new Employee("张3",28,"201303");
Employee employee4=new Employee("张4",20,"201304");
treeSet.add(employee1);
treeSet.add(employee2);
treeSet.add(employee3);
treeSet.add(employee4);
/*treeSet.add(null); //at com.yd.collection.Test_Collection_TreeSet.main(Test_Collection_TreeSet.java:25)*/
//迭代显示
Iterator iterator=treeSet.iterator();
while(iterator.hasNext()){
Employee employee=(Employee) iterator.next();
System.out.println(employee);
}
}
}
实现Map接口的主要有两个类,一个是HashMap一个则是我们的HashTable。
Map主要以键值对的形式存在,因为Map的键是存储在一个Set中的,显而易见键是不可以重复的。如果重复添加相同的键那么就会覆盖之前相同键所对应的值。
那么HashMap和HashSet有什么不同处呢?主要有两点:
1)HashMap是线程不安全的,HashTable是线程安全的
2)HashMap中是可以存储null值的,而HashTable是不可以存储null值的。
在Map中着重需要理解的除了以上几点之外还需要理解Map的迭代。我主要总结是通过Map.entrySet()方法获得的是一个Set<Map.Entry>类,需要理解Map.Entry相当于Map中的每一个键值对的包装类。每一个Map.Entry只包含一个键值对。然后通过Set的iterator方法类迭代即可。具体看下面代码即可理解。
HashMap的Demo:
package com.yd.map;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
import com.yd.bean.Employee;
//哈希图
public class Test_Map_HashMap {
//程序入口
public static void main(String[] args) {
//map中键值是不能重复的但是可以为null
Map map=new HashMap();
Employee employee1=new Employee("张1",22,"201301");
Employee employee2=new Employee("张2",26,"201302");
Employee employee3=new Employee("张3",28,"201303");
Employee employee4=new Employee("张4",20,"201304");
Employee employee5=new Employee("张5",20,"201301");
map.put("201301", employee1);
map.put("201302", employee2);
map.put("201303", employee3);
map.put("201304", employee4);
//hashmap他是可以存储null值
map.put(null, null);
//添加一个键值相同的
map.put("201301", employee5);
Iterator iterator=map.entrySet().iterator();
while(iterator.hasNext()){
Map.Entry map1=(Entry) iterator.next();
String key=(String) map1.getKey();
Employee vaEmployee=(Employee) map1.getValue();
System.out.println("键值:"+key+" 值:"+vaEmployee);
}
//结果如下:添加键值相同时 原来此键值的值被覆盖了
/*键值:201304 值:Employee [name=张4, age=20, num=201304]
键值:201301 值:Employee [name=张5, age=20, num=201301]
键值:201303 值:Employee [name=张3, age=28, num=201303]
键值:201302 值:Employee [name=张2, age=26, num=201302]*/
}
}package com.yd.map;
import java.util.Hashtable;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import com.yd.bean.Employee;
//哈希表
public class Test_Collection_HashTable {
//程序入口
public static void main(String[] args) {
Hashtable hashtable=new Hashtable();
Employee employee1=new Employee("张1",22,"201301");
Employee employee2=new Employee("张2",26,"201302");
Employee employee3=new Employee("张3",28,"201303");
Employee employee4=new Employee("张4",20,"201304");
Employee employee5=new Employee("张5",20,"201301");
hashtable.put("201301", employee1);
hashtable.put("201302", employee2);
hashtable.put("201303", employee3);
hashtable.put("201304", employee4);
//hashhashtable他是不可以存储null值
/*hashtable.put(null, null); */ //at com.yd.map.Test_Collection_HashTable.main(Test_Collection_HashTable.java:24)
//添加一个键值相同的
hashtable.put("201301", employee5);
//迭代显示
Iterator iterator=hashtable.entrySet().iterator();
while(iterator.hasNext()){
Map.Entry map= (Entry) iterator.next();
String key=(String) map.getKey();
Employee employee=(Employee) map.getValue();
System.out.println("键值:"+key+" 值:"+employee);
}
}
}















 5646
5646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









