









数据分析库Pandas
前言
本篇博文对python的数据分析库pandas做了简略的介绍和应用指导,包含pandas模块简介,pandas绘图函数,read_csv,head方法,tail方法,columns方法,shape方法,loc方法,通过列读取数据,对数据加减乘除及其他操作,对数据排序和泰坦尼克号数据集例子。
pandas模块简介
pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
Pandas中常见的数据结构有两种:
| Series | DateFrame |
|---|---|
| 类似一维数组的对象 | 类似多维数组/表格数组;每列数据可以是不同的类型;索引包括列索引和行索引。 |
| Series |
- 构建Series:ser_obj = pd.Series(range(10))
- 由索引和数据组成(索引在左<自动创建的>,数据在右)。
- 获取数据和索引:ser_obj.index; ser_obj.values
- 预览数据: ser_obj.head(n);ser_obj.tail(n)
DateFrame
- 获取列数据:df_obj[col_idx]或df_obj.col_idx
- 增加列数据:df_obj[new_col_idx] = data
- 删除列:del df_obj[col_idx]
- 按值排序:sort_values(by = “label_name”)
常用方法
| 方法名称 | 方法功能 |
|---|---|
| Count | 非NA值得数量 |
| describe | 针对Series或各DataFrame列计算汇总统计 |
| min\max | 计算最小值和最大值 |
| argmin\argmax | 计算能够获取到最大值或最小值的索引位置 |
| idxmin\idxmax | 计算能够获取到最小值和最大值的索引值 |
| quantile | 计算样本的分位数(0-1) |
| sum | 值得总和 |
| mean | 值得平均值 |
| median | 值的算术中位数(50%分位数) |
| mad | 根据平均值计算平均绝对离差 |
| var | 样本值得方差 |
| std | 样本值得标准差 |
| skew | 样本值的偏度(三阶距) |
| kurt | 样本值的峰度(四阶距) |
| cumsum | 样本值的累计和 |
| cummin\cummax | 样本值的累计最大值和累计最小值 |
| cumprod | 样本值的累计积 |
| diff | 计算一阶差分(对时间序列很有用) |
| pct_change | 计算百分数变化 |
处理缺失数据
- Dropna()丢弃缺失数据
- Fillna()填充缺失数据
数据过滤
Df[filter_condition]依据filter_condition(条件)对Df(数据)进行过滤。
绘图功能
Plot(kind,x,y,title,figsize)
Kind(绘制什么形式的图),x(x轴内容),y(y轴内容),title(图标题)
,figsize(图大小)
保存图片:
plt.savefig()
Pandas的绘图函数
之前看的直接用matplotlib来绘图,画一张图还得配置各种标题,刻度标签等等。而pandas的DataFrame和Series都自带生成各类图表的plot方法,就可以省略去写行列标签,分组信息等。明显更简洁的多。
- 线型图
plot方法默认生成的就是线形图。
s = Series(data=np.random.randint(0,10, size=10))
s.plot()
- 柱状图
Series柱状图示例:
kind = 'bar'/'barh'
s.plot(kind='bar')
s.plot(kind='barh')
DataFrame柱状图示例
df.plot(kind='bar')
- 直方图
rondom生成随机数百分比直方图,调用hist方法
- 柱高表示数据的频数,柱宽表示各组数据的组距 参数bins可以设置直方图方
- 柱的个数上限,越大柱宽越小,数据分组越细致
- 设置normed参数为True,可以把频数转换为概率
s.plot(kind='hist')
kde图:核密度估计,用于弥补直方图由于参数bins设置的不合理导致的精度缺失问题
s.plot(kind='hist',bins=10,density=True) s.plot(kind='kde')
绘制一个由两个不同的标准正态分布组成的的双峰分布
n1 = np.random.normal(loc=10, scale=5, size=1000)
n2 = np.random.normal(loc=50, scale=7, size=1000)
n = np.hstack((n1,n2))
s = Series(data=n)
s.plot(kind='hist',bins=100,density=True)
s.plot(kind='kde')
- 散布图
这是官网上关于scatter_matrix方法的描述:
(有网友说看不懂,所以后期我又自己添加了翻译)
pandas.plotting.scatter_matrix(frame,alpha=0.5,figsize=None,ax=None,
grid=False,diagonal='hist',marker='.',
density_kwds=None, hist_kwds=None,
range_padding=0.05, **kwargs)
#主要列举了scatter_matrix的各种参数及其作用,散布图在机器学习里面用的挺多的
Draw a matrix of scatter plots.
#画一个散点图矩阵。
Parameters:
#参数
frame DataFrame
#关键帧 数据帧(关键字和关键字)
alpha float, optional
#alpha 浮点型,可选
Amount of transparency applied.
#透明度的应用
figsize(float,float), optional
#figsize(浮点型,浮点型),可选
A tuple (width, height) in inches.
#一个以英寸位单位的元组(宽,高)
ax Matplotlib axis object, optional
#轴对象
grid bool, optional
#grid 布尔型,可选
Setting this to True will show the grid.
#将此设置为True将显示网格。
diagonal {‘hist’, ‘kde’}
#对角线
Pick between ‘kde’ and ‘hist’ for either Kernel Density
#在“kde”和“hist”之间选择内核密度
Estimation or Histogram plot in the diagonal.
#在对角线上的估计或直方图。
marker str, optional
#maker 字符串,可选
Matplotlib marker type, default ‘.’.
#Matplotlib标记类型,默认' . '
density_kwds keywords
#密度关键字
Keyword arguments to be passed to kernel density estimate plot.
#关键字参数要传递到核密度估计图。
hist_kwds key words
#hist_kwds关键字
Keyword arguments to be passed to hist function.
#要传递给hist函数的关键字参数。
range_padding float, default 0.05
#range_padding float,默认0.05
Relative extension of axis range in x and y with respect to
(x_max - x_min) or (y_max - y_min).
#x和y轴范围相对于(x_max - x_min)或(y_max - y_min)的相对扩展。
kwargs
Keyword arguments to be passed to scatter function.
#要传递给scatter函数的关键字参数。
Returns
#返回值
numpy.ndarray
A matrix of scatter plots.
#返回一个矩阵的散点图
散布图 散布图是观察两个一维数据数列之间的关系的有效方法,DataFrame对象可用
使用方法: 设置kind = ‘scatter’,给明标签columns
df.plot(x='A', y='B',kind='scatter')
散布图矩阵,当有多个点时,两两点的关系
使用函数:
pd.plotting.scatter_matrix(),
参数diagnol:设置对角线的图像类型
pd.plotting.scatter_matrix(df)
pd.plotting.scatter_matrix(df, figsize=(16,16), diagonal='kde')
- 饼图
df.plot(kind='pie', autopct='%.2f%%')
read_csv
读取CSV数据文件
import pandas
url ="https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
names =['sepal-length', 'sepal-width','petal-length', 'petal-width','class']
food = pandas.read_csv(url, names=names)
print(type(food))
print(food.dtypes)
我使用鸢尾花数据集
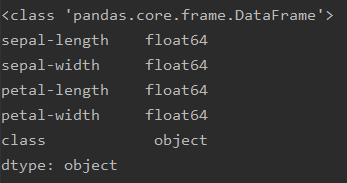
这里我打印了一下Type,可以看到类型为DataFrame,这个类型也是Pandas中,的核心类型。
下面我打印了一下,dtypes。可以看到,下面也是在pandas中非常常用的几种类型。int64,float64这两种就不用多说了。但是会发现一个新的类型。object类型
这个类型就相当于str类型,也就是字符串类型值。
pandas中常用的数据类型如下
- object 就是我们常说的字符串类型
- int 整型
- float 浮点型
- bool 布尔型
这里给出read_csv的参数介绍,尽量不要乱加参数
filepath_or_buffer : str,pathlib。str, pathlib.Path, py._path.local.LocalPath or any object with a read() method (such as a file handle or StringIO)
可以是URL,可用URL类型包括:http, ftp, s3和文件。对于多文件正在准备中
本地文件读取实例:://localhost/path/to/table.csv
sep : str, default ‘,’
指定分隔符。如果不指定参数,则会尝试使用逗号分隔。分隔符长于一个字符并且不是‘\s+’,将使用python的语法分析器。并且忽略数据中的逗号。正则表达式例子:'\r\t'
delimiter : str, default None
定界符,备选分隔符(如果指定该参数,则sep参数失效)
delim_whitespace : boolean, default False.
指定空格(例如’ ‘或者’ ‘)是否作为分隔符使用,等效于设定sep='\s+'。如果这个参数设定为Ture那么delimiter 参数失效。
在新版本0.18.1支持
header : int or list of ints, default ‘infer’
指定行数用来作为列名,数据开始行数。如果文件中没有列名,则默认为0,否则设置为None。如果明确设定header=0 就会替换掉原来存在列名。header参数可以是一个list例如:[0,1,3],这个list表示将文件中的这些行作为列标题(意味着每一列有多个标题),介于中间的行将被忽略掉(例如本例中的2;本例中的数据1,2,4行将被作为多级标题出现,第3行数据将被丢弃,dataframe的数据从第5行开始。)。
注意:如果skip_blank_lines=True 那么header参数忽略注释行和空行,所以header=0表示第一行数据而不是文件的第一行。
names : array-like, default None
用于结果的列名列表,如果数据文件中没有列标题行,就需要执行header=None。默认列表中不能出现重复,除非设定参数mangle_dupe_cols=True。
index_col : int or sequence or False, default None
用作行索引的列编号或者列名,如果给定一个序列则有多个行索引。
如果文件不规则,行尾有分隔符,则可以设定index_col=False 来是的pandas不适用第一列作为行索引。
usecols : array-like, default None
返回一个数据子集,该列表中的值必须可以对应到文件中的位置(数字可以对应到指定的列)或者是字符传为文件中的列名。例如:usecols有效参数可能是 [0,1,2]或者是 [‘foo’, ‘bar’, ‘baz’]。使用这个参数可以加快加载速度并降低内存消耗。
as_recarray : boolean, default False
不赞成使用:该参数会在未来版本移除。请使用pd.read_csv(...).to_records()替代。
返回一个Numpy的recarray来替代DataFrame。如果该参数设定为True。将会优先squeeze参数使用。并且行索引将不再可用,索引列也将被忽略。
squeeze : boolean, default False
如果文件值包含一列,则返回一个Series
prefix : str, default None
在没有列标题时,给列添加前缀。例如:添加‘X’ 成为 X0, X1, ...
mangle_dupe_cols : boolean, default True
重复的列,将‘X’...’X’表示为‘X.0’...’X.N’。如果设定为false则会将所有重名列覆盖。
dtype : Type name or dict of column -> type, default None
每列数据的数据类型。例如 {‘a’: np.float64, ‘b’: np.int32}
engine : {‘c’, ‘python’}, optional
Parser engine to use. The C engine is faster while the python engine is currently more feature-complete.
使用的分析引擎。可以选择C或者是python。C引擎快但是Python引擎功能更加完备。
converters : dict, default None
列转换函数的字典。key可以是列名或者列的序号。
true_values : list, default None
Values to consider as True
false_values : list, default None
Values to consider as False
skipinitialspace : boolean, default False
忽略分隔符后的空白(默认为False,即不忽略).
skiprows : list-like or integer, default None
需要忽略的行数(从文件开始处算起),或需要跳过的行号列表(从0开始)。
skipfooter : int, default 0
从文件尾部开始忽略。 (c引擎不支持)
skip_footer : int, default 0
不推荐使用:建议使用skipfooter ,功能一样。
nrows : int, default None
需要读取的行数(从文件头开始算起)。
na_values : scalar, str, list-like, or dict, default None
一组用于替换NA/NaN的值。如果传参,需要制定特定列的空值。默认为‘1.#IND’, ‘1.#QNAN’, ‘N/A’, ‘NA’, ‘NULL’, ‘NaN’, ‘nan’`.
keep_default_na : bool, default True
如果指定na_values参数,并且keep_default_na=False,那么默认的NaN将被覆盖,否则添加。
na_filter : boolean, default True
是否检查丢失值(空字符串或者是空值)。对于大文件来说数据集中没有空值,设定na_filter=False可以提升读取速度。
verbose : boolean, default False
是否打印各种解析器的输出信息,例如:“非数值列中缺失值的数量”等。
skip_blank_lines : boolean, default True
如果为True,则跳过空行;否则记为NaN。
parse_dates : boolean or list of ints or names or list of lists or dict, default False
boolean. True -> 解析索引
list of ints or names. e.g. If [1, 2, 3] -> 解析1,2,3列的值作为独立的日期列;
list of lists. e.g. If [[1, 3]] -> 合并1,3列作为一个日期列使用
dict, e.g. {‘foo’ : [1, 3]} -> 将1,3列合并,并给合并后的列起名为"foo"
infer_datetime_format : boolean, default False
如果设定为True并且parse_dates 可用,那么pandas将尝试转换为日期类型,如果可以转换,转换方法并解析。在某些情况下会快5~10倍。
keep_date_col : boolean, default False
如果连接多列解析日期,则保持参与连接的列。默认为False。
date_parser : function, default None
用于解析日期的函数,默认使用dateutil.parser.parser来做转换。Pandas尝试使用三种不同的方式解析,如果遇到问题则使用下一种方式。
1.使用一个或者多个arrays(由parse_dates指定)作为参数;
2.连接指定多列字符串作为一个列作为参数;
3.每行调用一次date_parser函数来解析一个或者多个字符串(由parse_dates指定)作为参数。
dayfirst : boolean, default False
DD/MM格式的日期类型
iterator : boolean, default False
返回一个TextFileReader 对象,以便逐块处理文件。
chunksize : int, default None
文件块的大小, See IO Tools docs for more informationon iterator and chunksize.
compression : {‘infer’, ‘gzip’, ‘bz2’, ‘zip’, ‘xz’, None}, default ‘infer’
直接使用磁盘上的压缩文件。如果使用infer参数,则使用 gzip, bz2, zip或者解压文件名中以‘.gz’, ‘.bz2’, ‘.zip’, or ‘xz’这些为后缀的文件,否则不解压。如果使用zip,那么ZIP包中国必须只包含一个文件。设置为None则不解压。
新版本0.18.1版本支持zip和xz解压
thousands : str, default None
千分位分割符,如“,”或者“."
decimal : str, default ‘.’
字符中的小数点 (例如:欧洲数据使用’,‘).
float_precision : string, default None
Specifies which converter the C engine should use for floating-point values. The options are None for the ordinary converter, high for the high-precision converter, and round_trip for the round-trip converter.
指定
lineterminator : str (length 1), default None
行分割符,只在C解析器下使用。
quotechar : str (length 1), optional
引号,用作标识开始和解释的字符,引号内的分割符将被忽略。
quoting : int or csv.QUOTE_* instance, default 0
控制csv中的引号常量。可选 QUOTE_MINIMAL (0), QUOTE_ALL (1), QUOTE_NONNUMERIC (2) or QUOTE_NONE (3)
doublequote : boolean, default True
双引号,当单引号已经被定义,并且quoting 参数不是QUOTE_NONE的时候,使用双引号表示引号内的元素作为一个元素使用。
escapechar : str (length 1), default None
当quoting 为QUOTE_NONE时,指定一个字符使的不受分隔符限值。
comment : str, default None
标识着多余的行不被解析。如果该字符出现在行首,这一行将被全部忽略。这个参数只能是一个字符,空行(就像skip_blank_lines=True)注释行被header和skiprows忽略一样。例如如果指定comment='#' 解析‘#empty\na,b,c\n1,2,3’ 以header=0 那么返回结果将是以’a,b,c'作为header。
encoding : str, default None
指定字符集类型,通常指定为'utf-8'. List of Python standard encodings
dialect : str or csv.Dialect instance, default None
如果没有指定特定的语言,如果sep大于一个字符则忽略。具体查看csv.Dialect 文档
tupleize_cols : boolean, default False
Leave a list of tuples on columns as is (default is to convert to a Multi Index on the columns)
error_bad_lines : boolean, default True
如果一行包含太多的列,那么默认不会返回DataFrame ,如果设置成false,那么会将改行剔除(只能在C解析器下使用)。
warn_bad_lines : boolean, default True
如果error_bad_lines =False,并且warn_bad_lines =True 那么所有的“bad lines”将会被输出(只能在C解析器下使用)。
low_memory : boolean, default True
分块加载到内存,再低内存消耗中解析。但是可能出现类型混淆。确保类型不被混淆需要设置为False。或者使用dtype 参数指定类型。注意使用chunksize 或者iterator 参数分块读入会将整个文件读入到一个Dataframe,而忽略类型(只能在C解析器中有效)
buffer_lines : int, default None
不推荐使用,这个参数将会在未来版本移除,因为他的值在解析器中不推荐使用
compact_ints : boolean, default False
不推荐使用,这个参数将会在未来版本移除
如果设置compact_ints=True ,那么任何有整数类型构成的列将被按照最小的整数类型存储,是否有符号将取决于use_unsigned 参数
use_unsigned : boolean, default False
不推荐使用:这个参数将会在未来版本移除
如果整数列被压缩(i.e. compact_ints=True),指定被压缩的列是有符号还是无符号的。
memory_map : boolean, default False
如果使用的文件在内存内,那么直接map文件使用。使用这种方式可以避免文件再次进行IO操作。
head方法
然后接着,我们在运行一个函数
print(food.head())
这个函数的作用是,将我们数据中的,前5行打印出来。结果如下:
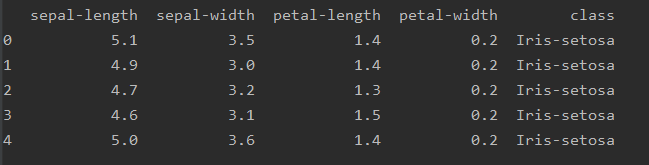 那么如果我们想让数据显示多条怎么处理呢?
那么如果我们想让数据显示多条怎么处理呢?
food.head(8),只需要在这个函数中添加参数即可
tail方法
可以显示前面的,那么肯定可以显示后面的:
print(food.tail(4))
这个方法相当于显示最后面的4条数据
columns方法
那么如果获取到数据表中,每一列的列名指标呢?
print(food.columns)
使用这个方便可以得到每个列表示的列名,结果是一个list,如下图

shape方法
还有一个要说的就是,如果看这个表的维度呢?
如果查看矩阵的维度,用shape方法
print(food.shape)
可以看到如下结果
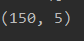
表示,当前数据,有150个样本,,5个属性
也就是150行,5列
loc方法
我们如何从pandas中获取到某个数据呢?
使用如下方法
print(food.loc[0])
这里我们可以看到,我们将第一个样本的全部值取出来了。
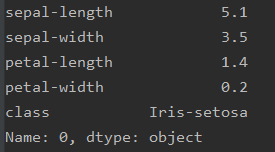
那么如果我们想去单独某条数据,那么只需要修改[0]到你需要的数据上即可。这里下标从0开始。大小超过数据的样本集,会直接报错。
如果我们在数据中,想去3,4,5这几行数据,那么我们怎么取呢?
print(food.loc[3:6])
可以看到,这种取法跟Python中,切片操作一样。
如果我想去单独某几条数据,只需要传入index值即可
print(food.loc[[2,5,10]])

通过列取数据
如果我先想不通过行去取数据,想通过列去取数据的话,我们该怎么做呢??
我们可以通过列名去拿取数据
length = food["sepal-length"]
print(length)
可以看到,我们取到了第一列的数据出来。
 那么我们想取两列数据出来,我们应该怎么操作呢?
那么我们想取两列数据出来,我们应该怎么操作呢?
方法跟上面一样,将列名加到里面,组成一个list列表。
sepal_2 = ["sepal-length","sepal-width"]
sepal_2_all = food[sepal_2]
print(sepal_2_all)

如果有些列名是带了单位的,那么我们怎么选择其中某几个一样单位的列呢?
我们先要取到全部的列名,然后将列名中带有单位(g)的列名取出,并单独放到一个列表中,最后在取这个列表中的列的数据即可
col_names = food.columns.tolist()
print(col_names)
gram_columns = []
for c in col_names:
if c.endswith("(g)"):
gram_columns.append(c)
gram_df = food[gram_columns]
print(gram_df.head(3))
对数据加减乘除及其他操作
再比如说,我们想进行一些加减乘除的操作
我想把单位为mg的数据,转换成g的数据
print(food["Iron_(mg)"])
div_1000 = food["Iron_(mg)"]/1000
print(div_1000)
我们在对某个数据上进行操作,即可得到我们想要的结果。
water_energy = food["Water_(g)"]*food["Energ_Kcal"]
对应位置的乘法操作,需要保证的是,维度要相同才可以!
water_energy = food["Water_(g)"]*food["Energ_Kcal"]
water_energy = food["Water_(g)"]*food["Energ_Kcal"]
iron_grams = food["Iron_(mg)"]/1000
print(food.shape)
food["Iron_(g)"]=iron_grams
print(food.shape)
上一段代码可以看到,我们把一列名称的值,进行单位转换,把mg转换为g,然后新建了一列数据,将这列数据放到数据集中。后面打印的是6个属性值,也就是我们将新的属性值,放入到原来的数据值中了!前提是,其中的维度要对应上才可以。
weighted_protein = food["Protein_(g)"]*2
weighted_fat =-0.75* food["Lipid_Tot_(g)"]
initial_rating = weighted_protein + weighted_fat
比如说这些运算操作, 维度一样,相当于对应位置进行运算。跟Numpy一样,我们也有一些别方法,求最大值,最小值,平均值等等方式基本上跟Numpy类似。
对数据排序
那么我们如何使用pandas对数据进行排序操作呢?
food.sort_values("sepal-length",inplace= True)
print(food["sepal-length"])
food.sort_values("sepal-length",inplace=True,ascending= False)
print(food["sepal-length"])
 我们对food,进行sort_values方法,会自动帮我们排序,第一个参数"sepal-length"是我们数据中的列名。
我们对food,进行sort_values方法,会自动帮我们排序,第一个参数"sepal-length"是我们数据中的列名。
意思是说,你要对哪一列数据进行排序,inplace 参数的意思是,你需要生成一个新的数据,还是在原来的基础上进行,可以通过该参数指定。
而sort_values排序的时候,就默认从小到大进行排序。
那么我们想做一个从大到小的排序如何做呢?
ascending这个参数,是指定一个排序升降序。在这里指定,默认该参数为True,也就是从小到大
那么我们在上面的代码中可以看到,ascending参数设置为Flase以后,即是从大到小
一个简单的案例(转)
下面我们讲个点单的例子,泰坦尼克号小案例
import pandas as pd
import numpy as np
titanic_survival = pd.read_csv("titanic_train.csv")
titanic_survival.head()
我现在有一下一些数据,每个值都代表不同的含义,实际是一个船人员信息表,有价格,有年龄,有名字,有座位编号,等等一些数据
 下面我们将年龄这一列进行数据处理,看看能得到什么结果,我们先查看了一下,前十个人的年龄如下
下面我们将年龄这一列进行数据处理,看看能得到什么结果,我们先查看了一下,前十个人的年龄如下

发现在5号人,的年龄为NAN,也就是说,这个数据为空,或者数据丢失。我们来对这个缺失值进处理
我们通过isnull方法,对数据进行判断,判断值是否为空。可以看到为True的说明数据丢失了
 然后我们将这个为空的数据作为索引,可以找到全部数据中,数据丢失的值
然后我们将这个为空的数据作为索引,可以找到全部数据中,数据丢失的值
 那我们现在统计一下,有多少个数据丢失了,可以用len方法。统计数据为空的值,为177就可以得到177个数据为空的值
那我们现在统计一下,有多少个数据丢失了,可以用len方法。统计数据为空的值,为177就可以得到177个数据为空的值

我们得到了缺失值后,要对缺失值进行处理
那么我先对数据没有做缺失值处理的情况下,进行一个求平均值的操作
 我们可以看到,算出来的值是nan,说明有问题!所以我们不能把带有缺失值得也计算在里面
我们可以看到,算出来的值是nan,说明有问题!所以我们不能把带有缺失值得也计算在里面
接下来我们对数据进行处理
一个基本的想法是这样的,就是说,当前数据中,有值的,我们就拿出来进行平均计算,没有值的,就不取出来进行运算

通过这样的计算,我们可以得到,平均年龄为29.6岁
这种方法可能有些麻烦,那么Pandas中有没有什么好的方法可以直接帮我们处理呢? 答案是有的

我们用这样一个简单的方法,一步就可以帮我们取出年龄的平均值。
那我们继续说些难一点的。我们在数据中,分了船舱有1, 2 ,3个等级,我们想计算一下,每个等级下的平均价格是多少
如何计算呢?

这段代码的意思是,我先用for循环,在数据中找到,哪些人是一等舱的人,哪些人是二等舱的人,哪些人是三等舱的人
我们先讲这些人的数据拿到手,拿到之后,我们进行列的定位,定位到价格这列,然后进行平均值,这样就可以得到一个平均价格
分别为以上三个,但是这种做法很麻烦,那么pandas中有没有一个更简单的方法帮我们处理数据呢?看下面的代码
我们有个需求,想算一下,3个舱位每个舱位的平均获救人数的值
 可以看到我们在pivot_table中,有三个参数,第一个参数为index,就是说我们要对哪列数据进行统计
可以看到我们在pivot_table中,有三个参数,第一个参数为index,就是说我们要对哪列数据进行统计
values则是说,你要在统计参数一的基础上和哪个数据有关系,作为统计。
第三个参数是aggfunc,就是说你要统计前面两个参数的什么值,我们这边统计平均值。既可以获得以上平均数据
那么我们在计算一下,每个舱位的平均年龄是多少
 我们可以直接按照这种方式进行计算,既可以得到每个舱的平均年龄,这里可以看到我们没有添加第三个参数因为如果不加参数3,那么系统会默认帮我们取平均值
我们可以直接按照这种方式进行计算,既可以得到每个舱的平均年龄,这里可以看到我们没有添加第三个参数因为如果不加参数3,那么系统会默认帮我们取平均值
那我们又有了新的需求。我们现在想看看。一个量之间,与其他量的关系
 我们将index设置为登船地点,那么values是船票的价格,和获救与否,最后一个参数是计算总值。
我们将index设置为登船地点,那么values是船票的价格,和获救与否,最后一个参数是计算总值。
这里我们想得到的数据就是,分别在C、Q、S这三个码头登船的人的获救总数
这个数据我们可以看到,C码头卖出了1万多块的票价,获救人数是93人。以此类推
那么我们先继续看
因为数据中有些缺失值,那么我们想把这些缺失值都丢掉应该怎么做呢?
 dropna的意思就是说,丢弃当前的缺失值。我们 想去掉Age Sex中有缺失值的数据,需要将这两列数据dropna方法中即可
dropna的意思就是说,丢弃当前的缺失值。我们 想去掉Age Sex中有缺失值的数据,需要将这两列数据dropna方法中即可
我们继续
那么我想对数据,定位到具体的某个值,我们怎么办呢?

我们可以看到,我们想找第83个样本的年龄,那么我们只需要在参数中添加样本编号,以及需要取到的数据对应的列名。
















 1908
1908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











