









什么是大端模式,什么是小端模式?
所谓的大端模式(Big-endian),是指数据的高字节,保存在内存的低地址中,而数据的低字节,保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;
所谓小端模式(Little-endian), 是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内在的低地址中,这种存储模式将地址的高低和数据位 权有效结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致;
为什么有大小端之分:
因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为 8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于 8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。我们常用的X86结构是小端模式,而KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
用图来形象地说明一下:

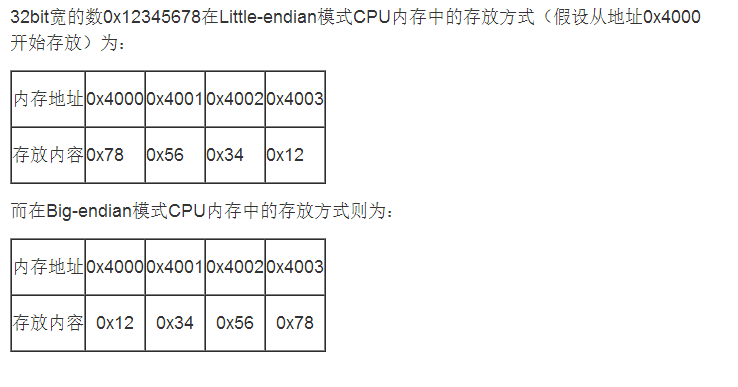
如何检测自己电脑是大端还是小端模式:
输入以下程序,即可以检测:
#include<stdio.h>
int main()
{
short int x;
char x0, x1;
x = 0x1122;
x0 = *((char *)&x); //把x的低位地址的值赋给x0;
x1 = *((char *)&x + 1); //把x的高位地址的值赋给x1;
if( x0 == 0x11 && x1 == 0x22)
printf(" This is big-endian \n");
else if( x0 == 0x22 && x1 == 0x11)
printf("This is little-endian \n");
else
printf("呵呵,你这个方法有误啊\n");
return 0;
}
如何把数据转换呢??
具体要看数据是如何存储的啦,以我遇到的一个问题为例,在人工手写体的数据库中,60000张训练图片的文件为:train-labels-idex1-ubyte.首先说明的是它的存储格式为大端模式,而我的计算机为小端模式,那我怎么办??
我们首先要做的就是知道它内部是如何存放数据的,即多少个字字为一个数据单位.我现在有在matlab读取文件的源代码,如下:
function images = loadMNISTImages(filename)
%loadMNISTImages returns a 28x28x[number of MNIST images] matrix containing
%the raw MNIST images
fp = fopen(filename, 'rb');
assert(fp ~= -1, ['Could not open ', filename, ''])
magic = fread(fp, 1, 'int32', 0, 'ieee-be')
assert(magic == 2051, ['Bad magic number in ', filename, ''])
numImages = fread(fp, 1, 'int32', 0, 'ieee-be');
numRows = fread(fp, 1, 'int32', 0, 'ieee-be');
numCols = fread(fp, 1, 'int32', 0, 'ieee-be');
images = fread(fp, inf, 'unsigned char');
images = reshape(images, numCols, numRows, numImages);
images = permute(images,[2 1 3]);
fclose(fp);
% Reshape to #pixels x #examples
images = reshape(images, size(images, 1) * size(images, 2), size(images, 3));
% Convert to double and rescale to [0,1]
images = double(images) / 255;
end
从上面我们可以看出文件的开头为4个 int32 类型的数,后面就是 unsigned char类型的数. 所以得出:int32 占4个字节即32个bit, 文件的前 4 * 4 个字节需要 由大端模式转为小端模式,而后面的unsigned char 类型数据本身占8 个bit, 不需要转换.以下是如何读取文件的源代码:
#include<stdio.h>
#include<stdlib.h>
int main()
{
int temp, i, nClose;
int num1[4]; //用于存放前四个int32的数;
unsigned char num2[1000]; //用于存放读出的1000个unsigned char类型的数;
FILE *fp;
fp = fopen("train-images-idx3-ubyte","rb");
if ( NULL == fp )
{
printf("Open file error");
exit(-1);
}
fread(num1, 4, 4, fp); //读取前4个int32类型的数据;
for(i=0; i<4; i++)
{ // 由大端模式转换为小端模式,其实对于占4个字节的数据来说,由小端转大端,也是一样的代码;
temp = (num1[i]>>24 & 0x000000FF) | (num1[i] >> 8 & 0x0000FF00) | (num1[i] << 8 & 0x00FF0000 ) | (num1[i] << 24 & 0xFF000000);
num1[i] = temp;
}
fread(num2, 1, 1000, fp); //读取1000个char类型的数据;
for(i=0; i<4; i++) //输出4个数;
printf(" %d\n", num1[i]);
for(i=0; i<1000; i++) // 输出1000个数;
printf("%d ", num2[i]);
nClose = fclose(fp); // 关闭文件;
if(EOF == nClose)
{
printf("Close file Error\n");
exit(-1);
}
return 0;
}
最再补充一个转换32位的更精简的方法,直接上代码(2016年11.28补充),可以由大端转为小端,也可以由小端转为大端:
uint32_t swap_endian(uint32_t val)
{
val = ((val << 8) & 0xFF00FF00) | ((val >> 8) & 0xFF00FF);
return (val << 16) | (val >> 16);
}
更新一个检测大端还是小端的代码(来自linux内核设计与实现一书, 2019-06-19)
int x = 1;
if (*(char*) &x == 1)
printf("小端");
else
pirntf("大端");
自己理解:
在大端模式中,0x12345678,高字节保存在低地址中。将大端模式中的文件复制在小端模式中时,由于低地址保存低字节,读到的数据为0x78563412,因此需将数据由大端模式转为小端模式。
==========================================================================
本文主要以linux下网络编程实验对大端存储与小端存储进行简单讲解:
概念
大端存储与小端存储模式主要指的是数据在计算机中存储的两种字节优先顺序。小端存储指从内存的低地址开始,先存储数据的低序字节再存高序字节;相反,大端存储指从内存的低地址开始,先存储数据的高序字节再存储数据的低序字节。
各自优点:
小端存储:便于数据之间的类型转换,例如:long类型转换为int类型时,高地址部分的数据可以直接截掉。
大端存储:便于数据类型的符号判断,因为最低地址位数据即为符号位,可以直接判断数据的正负号。
用途:
小端存储:常见于本地主机上(也有部分类型主机为大端存储)。
大端存储:常见于网络通信上,网际协议TCP/IP在传输整型数据时一般使用大端存储模式表示,例如TCP/IP中表示端口和IP时,均采用的是大端存储。
注:Linux中套接字ip地址的表示结构sockaddr_in.in_addr.in_addr_t类型实质上一般采用32位的unsigned int实现。
实验
Ubuntu中,建立客户端与服务器端程序之间的TCP链接,并绑定服务器端的端口为9877,注意此处直接将本地主机中用小端存储表示的9877整型数值复制给TCP的地址。
服务器端部分程序:
#define PORT 9877
int s_fd,c_fd;// 服务器和客户套接字标识符
struct sockaddr_in s_addr; // 服务器套接字地址
s_fd = socket(AF_INET, SOCK_STREAM, 0);// 创建套接字
s_addr.sin_family = AF_INET; // 定义服务器套接字地址中的域
s_addr.sin_addr.s_addr=htonl(INADDR_ANY);// 定义套接字地址
s_addr.sin_port = PORT;//直接将小端存储表示的9877赋值给地址中的端口
客户端部分程序:
#define PORT 9877
struct sockaddr_in addr;// 服务器段套接字地址
int sockfd;// 客户套接字标识符
sockfd = socket(AF_INET,SOCK_STREAM, 0);// 创建套接字
addr.sin_family = AF_INET; // 客户端套接字地址中的域
addr.sin_addr.s_addr=htonl(INADDR_ANY);// 定义套接字地址
addr.sin_port = PORT;//直接将小端存储表示的9877赋值给地址中的端口
len = sizeof(addr);
newsockfd = connect(sockfd,(struct sockaddr *)&addr,len);//发送连接服务器的请求
在上面的客户端与服务器端的TCP链接程序中,均是直接将将小端存储表示的9877赋值给地址中的端口。在将该客户端程序和服务端程序运行成功后,我们在Linux的终端中输入netstat -a查看网络链接情况,结果图如下:

由图可知,服务器端的监听端口和与客户端建立TCP链接的实际端口是38182,并不是9877。
其实,这就是由于主机字节序和网络字节序不一致导致的,因为9877在主机上由小端存储表示的,所以其二进制位10010101 10010101,TCP协议在解析该整型时则会按照大端存储模式来解析,解析结果为10010101 10010101,即38182。
进行字节序的转换
在将端口号9877赋值给网络地址的端口前,先利用htons将主机字节序转换为网络字节序。客户端和服务器端的代码修改为:
//服务器端程序修改部分
s_addr.sin_port = htons(PORT);//进行主机字节序到网络字节序的转换
//客户端程序修改部分
addr.sin_port = htons(PORT);
修改完成后,重新编译运行程序,建立客户端与服务器端之间的TCP链接。再次用netstat -a查看网络链接情况,结果图如下:
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









