







爬虫方法
a warning
前两种方法注意网页HTML里的行与行之间的
'\'换行符

方法一(正则的匹配问题)
正则表达式通常用于输出标签的属性值和文本内容
基础语法可见这篇博客–爬虫中正则表达式
注意: 在使用正则表达式时,要考虑换行符
"\n"的匹配。而且,'.'不匹配"\n"。(使用 re.S 或 re.DOTALL 标志时,'.'字符将匹配包括换行符在内的任何字符)
第一次
import re
text = """
<div class="box picblock col3" style="width:186px;height:264px">
<img src2="http://pic2.sc.chinaz.com/Files/pic/pic9/202007/apic26584_s.jpg" 123nfsjgnalt="山水风景摄影图片">
<a target="_blank" href="http://sc.chinaz.com/tupian/200509002684.htm"
<img src2="http://pic2.sc.chinaz.com/Files/pic/pic9/202007/apic26518_s.jpg" enrberonbialt="山脉湖泊山水风景图片">
<a target="_blank" href="http://sc.chinaz.com/tupian/200509002684.htm"
<img src2="http://pic2.sc.chinaz.com/Files/pic/pic9/202006/apic26029_s.jpg" woenigoigniefnirneialt="旅游景点山水风景图片">
<a target="_blank" href="http://sc.chinaz.com/tupian/200509002684.htm"
"""
img_info = re.findall(r'<div class="(.*?)><', text) # 匹配src2 alt里的内容
for src in img_info:
print(src)
#无输出
第二次
import re
text = """
<div class="box picblock col3" style="width:186px;height:264px">
<img src2="http://pic2.sc.chinaz.com/Files/pic/pic9/202007/apic26584_s.jpg" 123nfsjgnalt="山水风景摄影图片">
<a target="_blank" href="http://sc.chinaz.com/tupian/200509002684.htm"
<img src2="http://pic2.sc.chinaz.com/Files/pic/pic9/202007/apic26518_s.jpg" enrberonbialt="山脉湖泊山水风景图片">
<a target="_blank" href="http://sc.chinaz.com/tupian/200509002684.htm"
<img src2="http://pic2.sc.chinaz.com/Files/pic/pic9/202006/apic26029_s.jpg" woenigoigniefnirneialt="旅游景点山水风景图片">
<a target="_blank" href="http://sc.chinaz.com/tupian/200509002684.htm"
"""
img_info = re.findall(r'<div class="(.*?)">\n<', text) # 匹配src2里的内容
for src in img_info:
print(src)
# 输出--> box picblock col3
原因:
<div class="box picblock col3" style="width:186px;height:264px"> #此处有换行符 '\n'
<img src2="http://pic2.sc.chinaz.com/Files/pic/pic9/202007/apic26584_s.jpg" 123nfsjgnalt="山水风景摄影图片">
小收获
生成随机的请求头通常涉及到构造一个字典,该字典包含HTTP请求可能使用的不同类型的头部字段。这可以包括用户代理(User-Agent)、接受(Accept)、语言(Accept-Language)等。使用fake_useragent库来生成随机用户代理通用代码:
from fake_useragent import UserAgent
# 初始化UserAgent
user_agent = UserAgent()
# 获取一个随机的用户代理字符串
random_user_agent = user_agent.random
# 产生随机请求头
def random_ua():
headers = {
"User-Agent": random_user_agent,
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
# 可以添加更多的头部字段
}
return headers
# requests模拟请求
def scrape_html(url):
resp = requests.get(url, headers=random_ua())
# print(resp.status_code, type(resp.status_code))
if resp.status_code == 200:
return resp.text
else:
logging.info('请求网页失败')
使用随机生成的用户代理可以帮助模拟不同的浏览器和设备,但过度使用或滥用可能导致你的请求被网站识别为爬虫或机器人,从而受到限制或封禁。
代码(正则,有bug)
bug–> 有的quote没有,这时候,代码不能批量处理(for循环)
import requests
import re
from pandas import DataFrame
from fake_useragent import UserAgent
import logging
# 日志输出的基本配置
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
# 初始化UserAgent
user_agent = UserAgent()
# 获取一个随机的用户代理字符串
random_user_agent = user_agent.random
def random_ua():
headers = {
"User-Agent": random_user_agent,
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
# 可以添加更多的头部字段
}
return headers
def scrape_html(url):
resp = requests.get(url, headers=random_ua())
# print(resp.status_code, type(resp.status_code))
if resp.status_code == 200:
return resp.text
else:
logging.info('请求网页失败')
def get_data(page):
url = f"https://movie.douban.com/top250?start={25 * page}&filter="
html_text = scrape_html(url)
# 电影名称 导演 主演
name = re.findall('<img width="100" alt="(.*?)" src', html_text)
# 第二页缺少一个主演
director_actor = re.findall('(.*?)<br>', html_text)
director_actor = [item.strip() for item in director_actor]
# 上映时间 上映地区 电影类型信息 去除两端多余空格
info = re.findall('<br>\n (.*?) / (.*?) / (.*?)\n', html_text)
time_ = [x[0].strip() for x in info]
area = [x[1].strip() for x in info]
genres = [x[2].strip() for x in info]
# 评分 评分人数
rating_score = re.findall('<span class="rating_num" property="v:average">(.*?)</span>', html_text)
rating_num = re.findall('<span>(.*?)人评价</span>', html_text)
# 一句话引言,第五页缺少一句引言
quote = re.findall('<span class="inq">(.*?)</span>', html_text)
data = {'电影名': name, '导演': director_actor,
'上映时间': time_, '上映地区': area, '电影类型': genres,
'评分': rating_score, '评价人数': rating_num, '引言': quote}
df = DataFrame(data)
if page == 0:
df.to_csv('movie_data2.csv', mode='a+', header=True, index=False)
else:
df.to_csv('movie_data2.csv', mode='a+', header=False, index=False)
logging.info(f'已爬取第{page + 1}页数据')
if __name__ == '__main__':
for i in range(10):
get_data(i)
方法二(关于bs4的使用)
find( )与 find_all( ) 是 BeautifulSoup 对象的两个方法,它们可以匹配 html 的标签和属性,把 BeautifulSoup 对象里符合要求的数据都提取出来:
- find( )只提取第一个满足要求的数据
- find_all( )提取出的是所有满足要求的数据
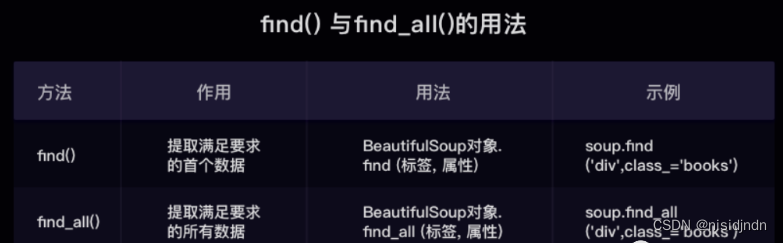
关于bs4对象tag的使用方法如下图:
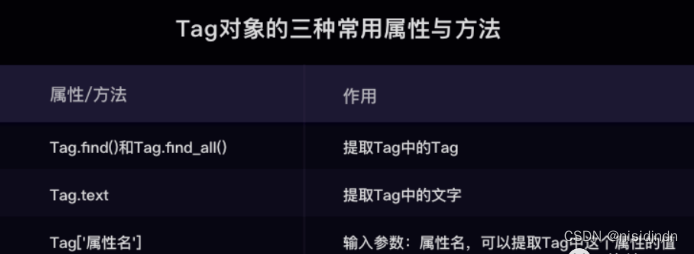
同时,还有
tag.tag1.tag2.text()的提取方法(也就是从父标签tag中按照等级依次取出子tag,最后取出text);
另外,关于取出标签属性值:
tag = soup.find('a') # 提取<a>标签
href_value = tag.get('href') # 提取标签的href属性
关于str.rsplit函数的使用
在Python中,
str.rsplit(separator, maxsplit)方法用于在一个字符串末尾进行分割操作。这里的separator是分隔符,可以是任何字符串;maxsplit是一个可选参数,表示最大分割次数,如果不提供,则默认为 -1,意味着分割操作会尽可能多地进行。
temp1.rsplit('/', 2)表示在temp[1]字符串的末尾开始,沿着每个'/'分隔符进行分割,最多分割两次。如果'/'出现的次数少于2次,则按照实际出现的次数进行分割。temp1将存储分割后的字符串列表。
temp[1] = 'dir1/dir2/dir3/file.txt'
temp1 = temp[1].rsplit('/', 2)
# 输出-->temp1 = ['dir1/dir2', 'dir3', 'file.txt']
将执行以下操作:
- 从右向左查找 ‘/’ 分隔符。遇到第一个 ‘/’,分割成 ‘dir1/dir2’ 和 ‘dir3/file.txt’。
- 由于 maxsplit 参数是2,所以继续分割 ‘dir3/file.txt’,但因为只剩下一个 ‘/’,所以只会再分割一次,得到 ‘dir3’ 和 ‘file.txt’。
- temp1 将是一个包含三个部分的列表:[‘dir1/dir2’, ‘dir3’, ‘file.txt’]。
代码(bs4)
import requests
from bs4 import BeautifulSoup
import openpyxl
from fake_useragent import UserAgent
import logging
# 日志输出的基本配置
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
# 初始化UserAgent
user_agent = UserAgent()
# 获取一个随机的用户代理字符串
random_user_agent = user_agent.random
wb = openpyxl.Workbook() # 创建工作簿对象
sheet = wb.active # 获取工作簿的活动表
sheet.title = "movie" # 工作簿重命名
sheet.append(["排名", "网址", "照片网址", "电影名", "电影英文名", "导演和主演", "上映时间", "上映地区", "电影类型", "评分", "评价人数", "引言"])
def random_ua():
headers = {
"User-Agent": random_user_agent,
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
# 可以添加更多的头部字段
}
return headers
def scrape_html(url):
resp = requests.get(url, headers=random_ua())
# print(resp.status_code, type(resp.status_code))
if resp.status_code == 200:
return resp.text
else:
logging.info('请求网页失败')
def get_data(page):
global rank
url = f"https://movie.douban.com/top250?start={25 * page}&filter="
html_text = scrape_html(url)
# 创建了一个BeautifulSoup对象
soup = BeautifulSoup(html_text, 'html.parser')
lis = soup.find_all('div', class_='item')
# 返回一个列表,列表中包含了所有具有类名item的<div>标签
for li in lis:
url_douban = li.find('div', class_='pic').a.get('href')
pic = li.find('div', class_='pic').a.img.get('src')
# 找到包含中文电影名的第一个 span 标签
chinese_title_span = li.find('div', class_='hd').a.find('span', class_='title')
name = chinese_title_span.text
next_sibling = chinese_title_span.next_sibling.next_sibling
# 使用 next_sibling 获取包含英文电影名的第二个 span 标签
# 注意:由于 被转换成 '\u00a0',我们需要将其替换为普通空格
if next_sibling == '\n':
# 跳过这个换行符,获取下一个同级元素
next_sibling = next_sibling.next_sibling
en_name = next_sibling.text.replace('\u00a0', ' ').split('/')[1].strip()
div_bd = li.find('div', class_='bd')
time_, area, genres, director_actor = None, None, None, None
if div_bd:
p_tag = li.find('div', class_='bd').find('p')
if p_tag:
# 使用separator='\n'来将<br/>和连续的空格转换为换行符
temp = p_tag.get_text(separator='\n').strip().split('\n')
director_actor = temp[0]
temp1 = temp[2].rsplit('/', 2)
time_, area, genres = [item.strip() for item in temp1]
quote = li.find('p', class_='quote')
# 有些电影信息没有一句话引言
if quote:
quote = quote.span.text
else:
quote = None
rating_score = li.find('span', class_='rating_num').text
rating_num = li.find('div', class_='star').find_all('span')[-1].text
sheet.append([rank, url_douban, pic, name, en_name, director_actor, time_, area, genres, rating_score, rating_num, quote])
logging.info([rank, url_douban, pic, name, en_name, director_actor, time_, area, genres, rating_score, rating_num, quote])
rank += 1
if __name__ == '__main__':
rank = 1
for i in range(10):
get_data(i)
wb.save(filename='movie_info4.xlsx')
关于网页中的非断行空格和换行标签:
是一个非断行空格的字符实体,它表示一个空格,但与普通的空格不同, 在文本中不会被拆分到新的一行。在解析HTML文档时,BeautifulSoup会将所有的HTML实体,包括 ,转换为它们对应的Unicode字符。<br/>在BeautifulSoup解析后通常不会直接转换成换行符\n,而是转换成了空行。(在网页中,注意行与行间的'\n'换行符)
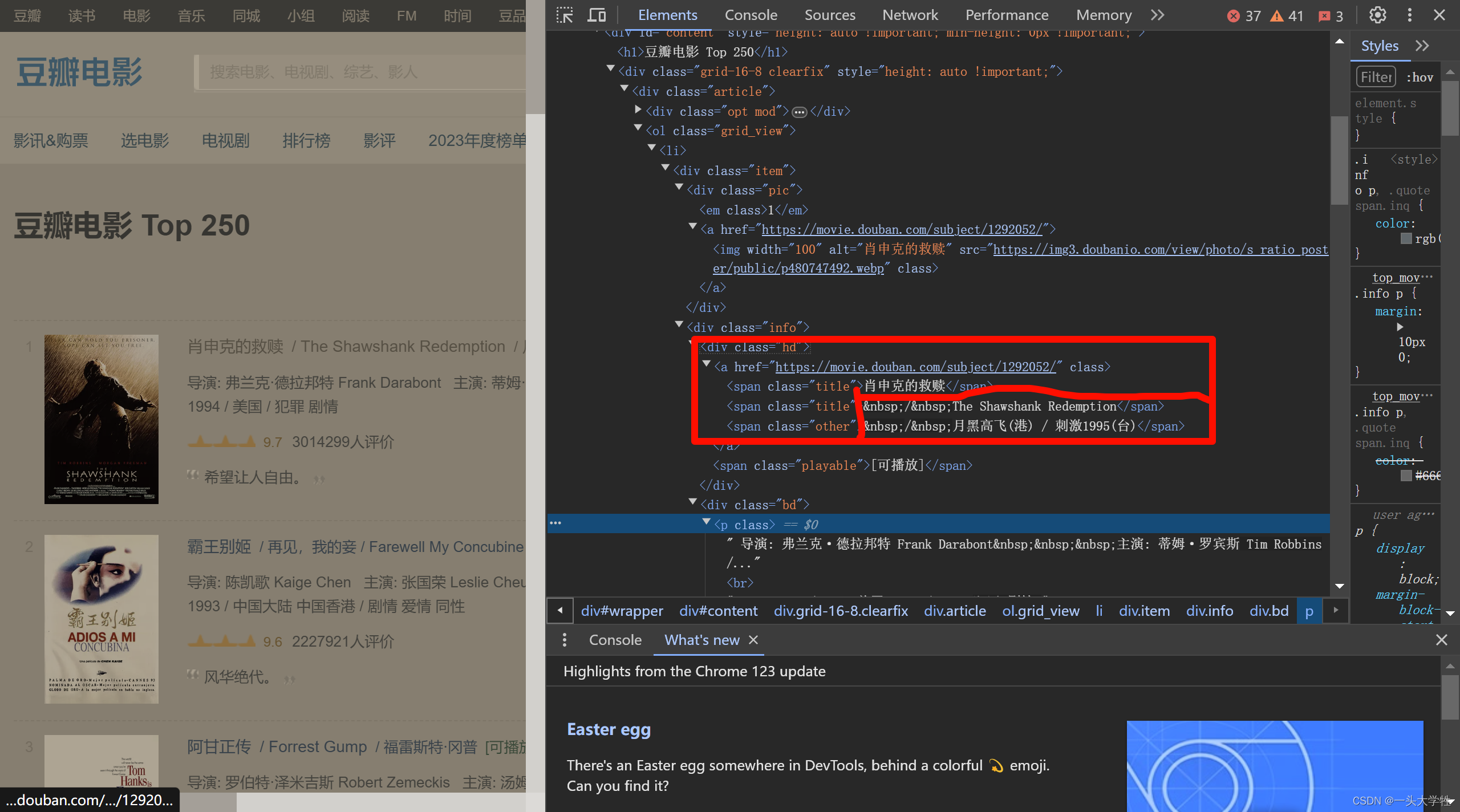
关于next_sibling的使用
next_sibling是一个特殊属性,用于获取与当前标签(Tag)相邻的下一个同级标签。所谓“同级”意味着这个标签与当前标签有相同的父标签。
问题:在使用BeautifulSoup的
.next_sibling方法时,空行被当作一种节点对待。这意味着如果我们的HTML标签之间有空行,.next_sibling会返回一个空行节点而不是下一个有效标签。
解决:
- 可以尝试使用
.next_sibling.next_element方法来忽略空行节点。这样可以确保你获得所需的下一个有效标签而不是空行1。(.next_element返回紧邻在当前节点之后的第一个元素,而不管它是什么类型。)本解决方案是'\n'换行符节点后的span有效标签。
- 使用
next_sibling.next_sibling,将此空行节点跳过。
两种查找文本方式
- 层级标签查找–>
tag.tag1.tag2.text- 通用查找–>
tag.find().text.get_text()和.text
方法三(使用Xpath)
基础语法可见:这篇文章–>Python爬虫实战之xpath解析
如图所示,直接借助浏览器copyXpath的路径
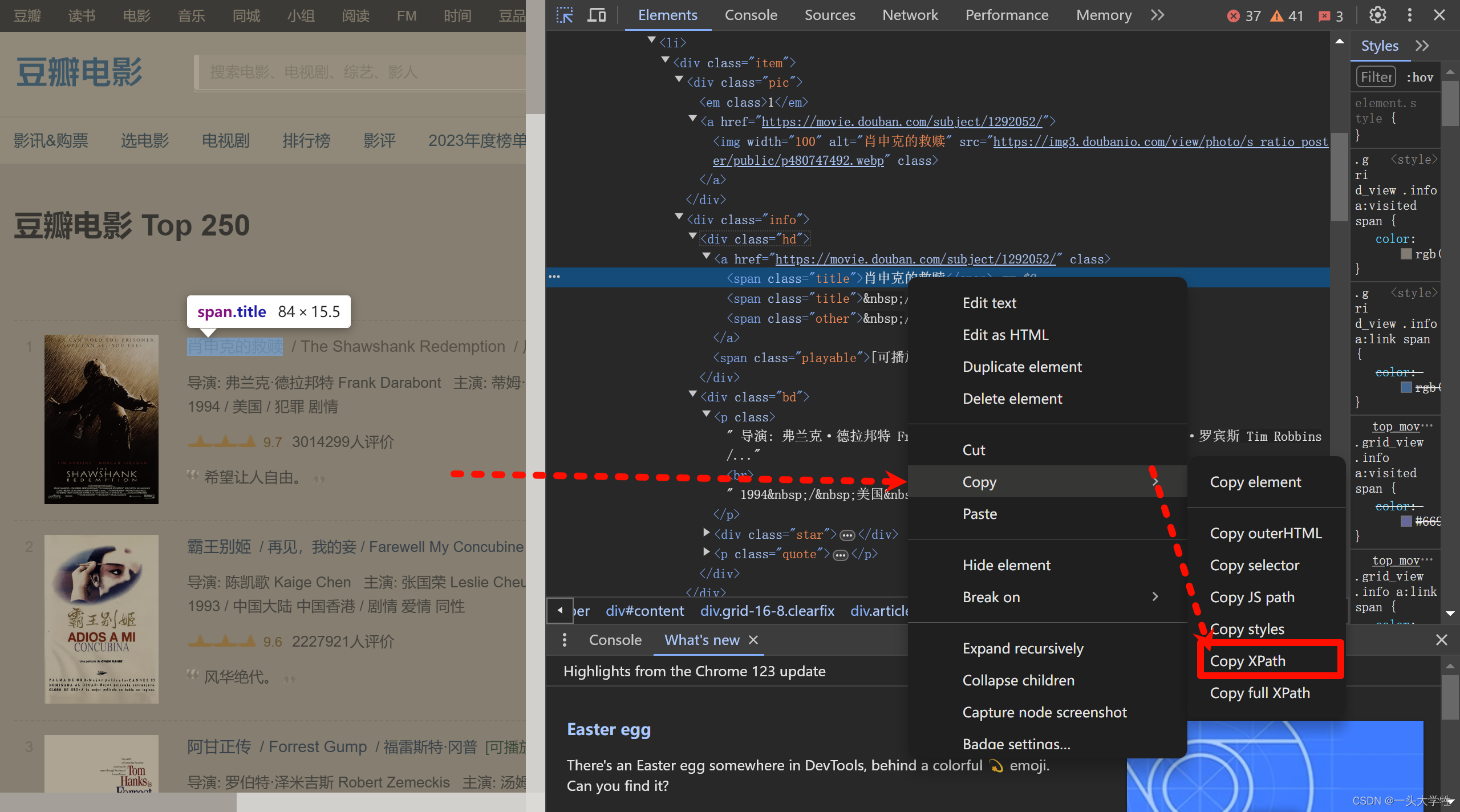
代码(Xpath)
import requests
from lxml import etree
import openpyxl
from fake_useragent import UserAgent
import logging
# 日志输出的基本配置
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
# 初始化UserAgent
user_agent = UserAgent()
# 获取一个随机的用户代理字符串
random_user_agent = user_agent.random
wb = openpyxl.Workbook() # 创建工作簿对象
sheet = wb.active # 获取工作簿的活动表
sheet.title = "movie" # 工作簿重命名
sheet.append(["排名", "网址", "照片网址", "电影名", "电影英文名", "导演和主演", "上映时间", "上映地区", "电影类型", "评分", "评价人数", "引言"])
def random_ua():
headers = {
"User-Agent": random_user_agent,
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
# 可以添加更多的头部字段
}
return headers
def scrape_html(url):
resp = requests.get(url, headers=random_ua())
# print(resp.status_code, type(resp.status_code))
if resp.status_code == 200:
return resp.text
else:
logging.info('请求网页失败')
def get_data(page):
global rank
url = f"https://movie.douban.com/top250?start={25 * page}&filter="
html = etree.HTML(scrape_html(url))
lis = html.xpath('//ol[@class="grid_view"]/li')
# 每个li标签里有每部电影的基本信息
for li in lis:
# .表示从当前li节点开始搜索,//是所有目标子节点
# ps: xpath返回的是一个列表,所以要加index取元素
url_douban = li.xpath('.//div[@class="pic"]/a/@href')[0]
pic = li.xpath('.//div[@class="pic"]/a/img/@src')[0]
en_name = li.xpath('.//div[@class="hd"]/a/span[2]/text()')[0].split("/")[1].strip()
name = li.xpath('.//div[@class="hd"]/a/span[1]/text()')[0]
director_actor = li.xpath('.//div[@class="bd"]/p/text()')[0].strip()
info = li.xpath('.//div[@class="bd"]/p/text()')[1].strip()
# 按"/"切割成列表
_info = info.split("/")
# 得到 上映时间 上映地区 电影类型信息 去除两端多余空格
time_, area, genres = _info[0].strip(), _info[1].strip(), _info[2].strip()
# print(time, area, genres)
rating_score = li.xpath('.//div[@class="star"]/span[2]/text()')[0]
rating_num = li.xpath('.//div[@class="star"]/span[4]/text()')[0]
quote = li.xpath('.//p[@class="quote"]/span/text()')
# 有些电影信息没有一句话引言 加条件判断 防止报错
if len(quote) == 0:
quote = None
else:
quote = quote[0]
sheet.append([rank, url_douban, pic, name, en_name, director_actor, time_, area, genres, rating_score, rating_num, quote])
logging.info([rank, url_douban, pic, name, en_name, director_actor, time_, area, genres, rating_score, rating_num, quote])
rank += 1
if __name__ == '__main__':
rank = 1
for i in range(10):
get_data(i)
wb.save(filename='movie_info1.xlsx')
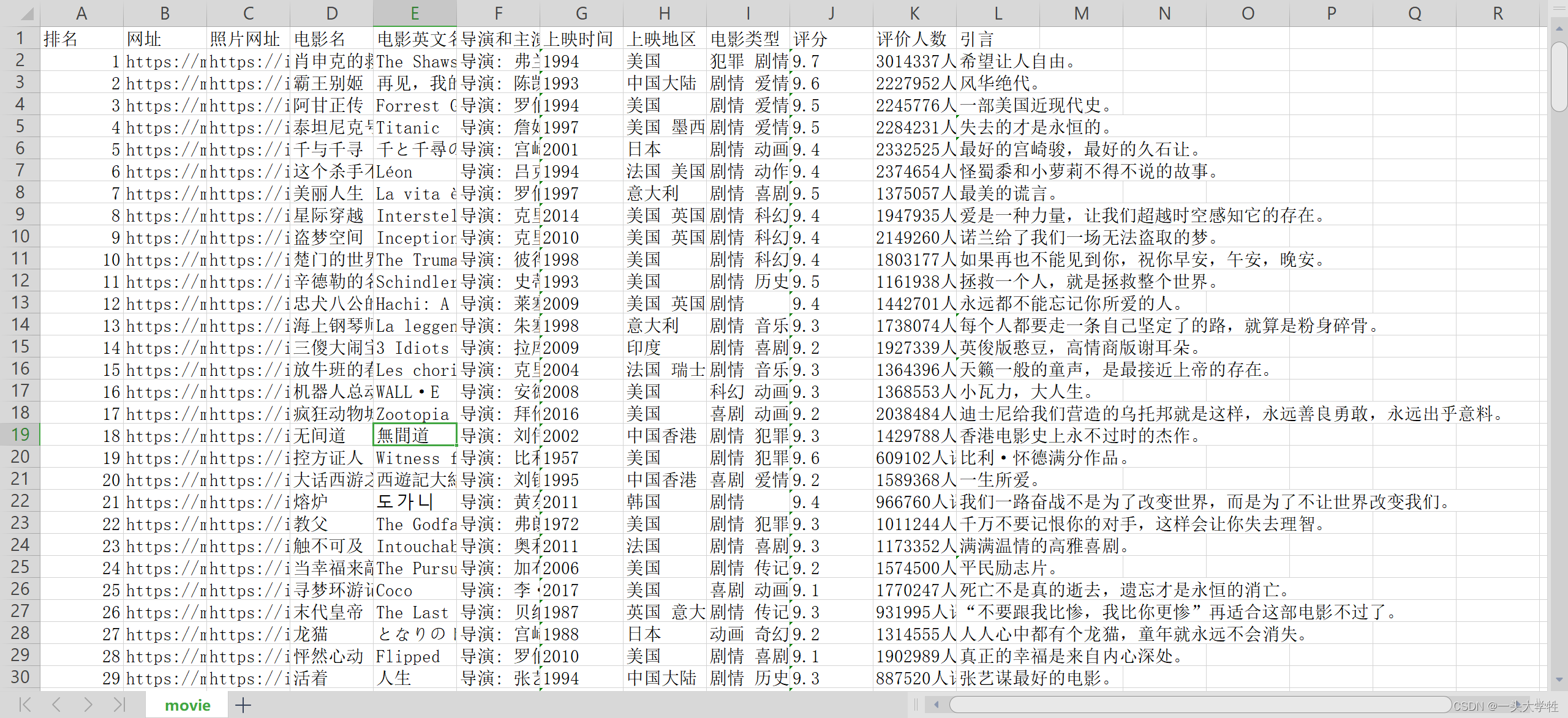
注意:
.表示从当前li节点开始搜索,//是所有目标子节点,\是从根节点开始。
ps: xpath返回的是一个列表,所以要加index取元素。
爬虫中的字符串处理2
具体可见:python 爬虫中的字符串处理
ps:处理 <br/>:
html_doc = "This is line one.<br/>This is line two."
soup = BeautifulSoup(html_doc, 'html.parser')
text = soup.get_text(separator='\n')
print(text) # 输出: This is line one.\nThis is line two.
.get_text(separator=‘\n’) 方法被用来获取文本,并将所有的
<br/>标签转换成换行符\n。attention:留意html文本中行与行之间的'\n'。
参考博客:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









