







一. MapReduce on Yarn流程
1. 什么是MapReduce
MapReduce是一个计算框架,核心思想是"分而治之",表现形式是有个输入(input),mapreduce操作这个输入(input),通过本身定义好的计算模型,得到一个输出(output),这个输出就是我们所需要的结果。在运行一个mapreduce计算任务时候,任务过程被分为两个阶段:map阶段和reduce阶段,每个阶段都是用键值对(key/value)作为输入(input)和输出(output)。而程序员要做的就是定义好这两个阶段的函数:map函数和reduce函数。
- Map:映射过程,把一组数据按照某种Map函数映射成新的数据。每一行解析成一个
<k,v>键值对。每一个键值对调用一次map函数,生成一个新的<k,v>键值对 - Shuffle:洗牌,对数据映射的排序、分组、拷贝。
- Reduce:归约过程,把若干组映射结果进行汇总并输出。
2. Yarn的作用
Yarn:ResourceManager,NodeManager
RM:application Manager 应用程序管理器
resource scheduler 资源memory+cpu调度器
- ResourceManager:负责资源管理。在运行过程中,整个系统有且只有一个RM,系统的资源由RM来负责调度管理。RM包含了两个主要的组件:定时调用器(Scheduler)以及应用管理器(ApplicationManager):
- 定时调度器(Scheduler):从本质上来说,定时调度器就是一种策略,或者说一种算法。当Client提交一个任务的时候,它会根据所需要的资源以及当前集群的资源状况进行分配。注意,它只负责向应用程序分配资源,并不做监控以及应用程序的状态跟踪。
- 应用管理器(ApplicationManager):同样,听名字就能大概知道它是干嘛的。应用管理器就是负责管理Client用户提交的应用。定时调度器(Scheduler)不对用户提交的程序进行监控,监控应用的工作正是由应用管理器(ApplicationManager)完成的。
- ApplicationMaster:每当Client(用户)提交一个Application(应用程序)时候,就会新建一个ApplicationMaster。由这个ApplicationMaster去与ResourceManager申请容器资源,获得资源后会将要运行的程序发送到容器上启动,然后进行分布式计算。
这里可能有些难以理解,为什么是把运行程序发送到容器上去运行?如果以传统的思路来看,是程序运行着不动,然后数据进进出出不停流转。但当数据量大的时候就没法这么玩了,因为海量数据移动成本太大,时间太长。但是中国有一句老话山不过来,我就过去。大数据分布式计算就是这种思想,既然大数据难以移动,那我就把容易移动的应用程序发布到各个节点进行计算呗,这就是大数据分布式计算的思路。
- NodeManager:相比起上面两个组件的掌控全局,NodeManager就显得比较细微了。NodeManager是ResourceManager在每台机器的上代理,主要工作是负责容器的管理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),并且它会定期向ResourceManager/Scheduler提供这些资源使用报告,再由ResourceManager决定对节点的资源进行何种操作(分配,回收等)。
3. MapReduce on Yarn
涉及概念:
| 简写 | 全称 | 备注 |
|---|---|---|
| Client | Client | 客户端 |
| RM | ResourceManager | |
| App | Application | 应用程序:job,App,java命令,sql等 |
| AppMaster | ApplicationMaster | 应用程序主入口 |
| AppManager | ApplicationManager | |
| NM | NodeManager | |
| container | container | |
| RPC | RPC | |
| task | task |

3.1. 任务提交
Client向RM提交应用程序(job,App,jar文件,sql),其中包括AppMaster程序、启动AppMaster的命令等;
3.2. 分配容器
RM为该job分配第一个container,运行job的AppMaster;
3.3. 注册状态
AppMaster向AppManager注册,这样就可以在RM WEB界面查询这个job的运行状态;
3.4. 申请资源
AppMaster通过RPC协议以轮询的方式向RM申请和领取资源
3.5. 申请启动
AppMaster拿到资源,与对应的与NM进行通信,要求启动任务
3.6. 启动task
NM为任务设置好运行环境,将任务启动命令写在一个脚本里,并通过该脚本启动任务(task)
3.7. 进度汇报
各个task通过RPC协议向AppMaster汇报自己的状态和进度,以此让AppMaster随时掌握各个task的运行状态,从而在task运行失败重启任务。
3.8. 结束注销
任务结束(包括success、failed、killed等),AppMaster向APPManager注销且关闭自己
简而言之,分为两步:
- 启动AppMaster,申请资源;
- 运行任务,结束释放资源。
二. HDFS文件格式初涉
hive原生支持的格式包括:
- TEXTFILE : textfile为默认格式,存储方式为行式存储,在检索时磁盘开销大,数据解析开销大,而对压缩的text文件,hive无法进行合并和拆分
- SEQUENCEFILE : 二进制文件,以<key,value>的形式序列化到文件中,存储方式为行式存储,可以对文件进行分割和压缩,一般使用block压缩,使用Hadoop 的标准的Writable接口实现序列化和反序列化,和hadoop api中的mapfile是相互兼容的。
- RCFILE : 存储方式为数据按行分块,每块按照列存储的行列混合模式,具有压缩快,列存取快的特点。在使用时,读记录尽量涉及到的block最少,这样读取需要的列只需要读取每个row group 的头部定义,具有明显速度优势。读取全量数据的操作 性能可能比sequencefile没有明显的优势。
hive发展过程中出现的存储格式并发展为Apache独立顶级项目:Apache Orc 和 Apache Parquet
- Orc是从HIVE的原生格式RCFILE优化改进而来。Parquet是Cloudera公司研发并开源的格式。
- 这两者都属于列存储格式,但Orc严格上应该算是行列混合存储,首先根据行组分割整个表,在每一个行组内进行按列存储。Parquet文件和Orc文件都是是自解析的,文件中包括该文件的数据和元数据,Orc的元数据使用Protocol Buffers序列化。
- 两者都支持嵌套数据格式(struct\map\list)但策略不同: Parquet支持嵌套的数据模型,类似于Protocol Buffers,每一个数据模型的schema包含多个字段,每一个字段有三个属性:重复次数、数据类型和字段名; ORC原生是不支持嵌套数据格式的,而是通过对复杂数据类型特殊处理的方式实现嵌套格式的支持。
- 压缩:两者都相比txt格式进行了数据压缩,相比而言,Orc的压缩比例更大,效果更好。
- 计算引擎支持:都支持spark、MR计算引擎。
- 查询引擎支持:Parquet被Spark SQL、Hive、Impala、Drill等支持;而Orc被Spark SQL、Presto、Hive支持,Orc不被Impala支持。
- 功能及性能对比:使用TPC-DS数据集并且对它进行改造以生成宽表、嵌套和多层嵌套的数据。使用最常用的Hive作为SQL引擎进行测试,最终表现:
功能:ORC的压缩比更大,对存储空间的利用更好;ORC可以一定程度上支持ACID操作,Parquet不可以
性能:数据导入orc更快;聚合查询 orc更快;单表查询orc快一点点点;带有复杂数据构成的表查询(1层)orc更快;带有复杂数据构成的表查询(3层)orc更快
相同数据(19M),分别以TextFile、SequenceFile、RcFile、ORC存储的磁盘空间占用大小比较:
ORCFile(7.7M) < parquet(13.1M) < RcFile(17.9M) < Textfile(18.1M) < SequenceFile(19.6)
https://ruozedata.github.io/2018/04/20/Hive%E5%AD%98%E5%82%A8%E6%A0%BC%E5%BC%8F%E7%9A%84%E7%94%9F%E4%BA%A7%E5%BA%94%E7%94%A8/
三. 压缩格式
- 优点
- 减少磁盘存储
- 降低网络IO和磁盘IO
- 加快数据传输,提升数据处理速度
- 缺点
- 使用时需要先解压,增加cpu负担
- 有哪些压缩格式
- gzip
- bzip2
- LZO
- LZ4
- snappy
https://ruozedata.github.io/2018/04/18/%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%8E%8B%E7%BC%A9%EF%BC%8C%E4%BD%A0%E4%BB%AC%E7%9C%9F%E7%9A%84%E4%BA%86%E8%A7%A3%E5%90%97%EF%BC%9F/
四. spilt数量和Map task数量关系
在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组。
输入分片(input split)往往和hdfs的block(块)关系很密切,假如我们设定hdfs的块的大小是64mb,如果我们输入有三个文件,大小分别是3mb、65mb和127mb,那么mapreduce会把3mb文件分为一个输入分片(input split),65mb则是两个输入分片(input split)而127mb也是两个输入分片(input split),换句话说我们如果在map计算前做输入分片调整,例如合并小文件,那么就会有5个map任务将执行,而且每个map执行的数据大小不均,这个也是mapreduce优化计算的一个关键点。
五. wordcount的剖解图
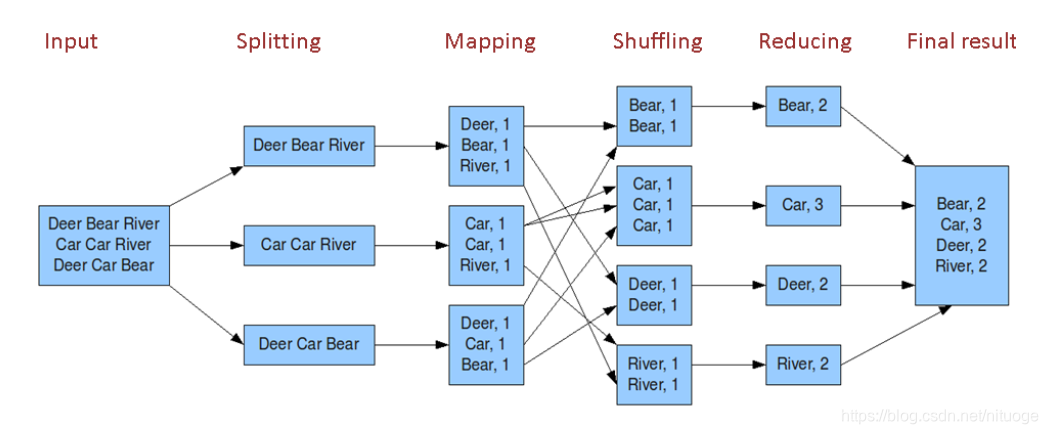
一般认为shuffle是属于reduce的过程
六. shuffle的理解
- https://www.cnblogs.com/qingyunzong/p/8615024.html

















 1980
1980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









