







在没有 YARN 之前,Hadoop 1.0 版本时候, MapReduce做很多的事情,
Job Tracker(作业跟踪者)既做资源管理又做任务调度/监控,Task Tracker 资源划
分过于粗,MapReduce 实现任务分配、资源分配、批量计算的框架图如下:
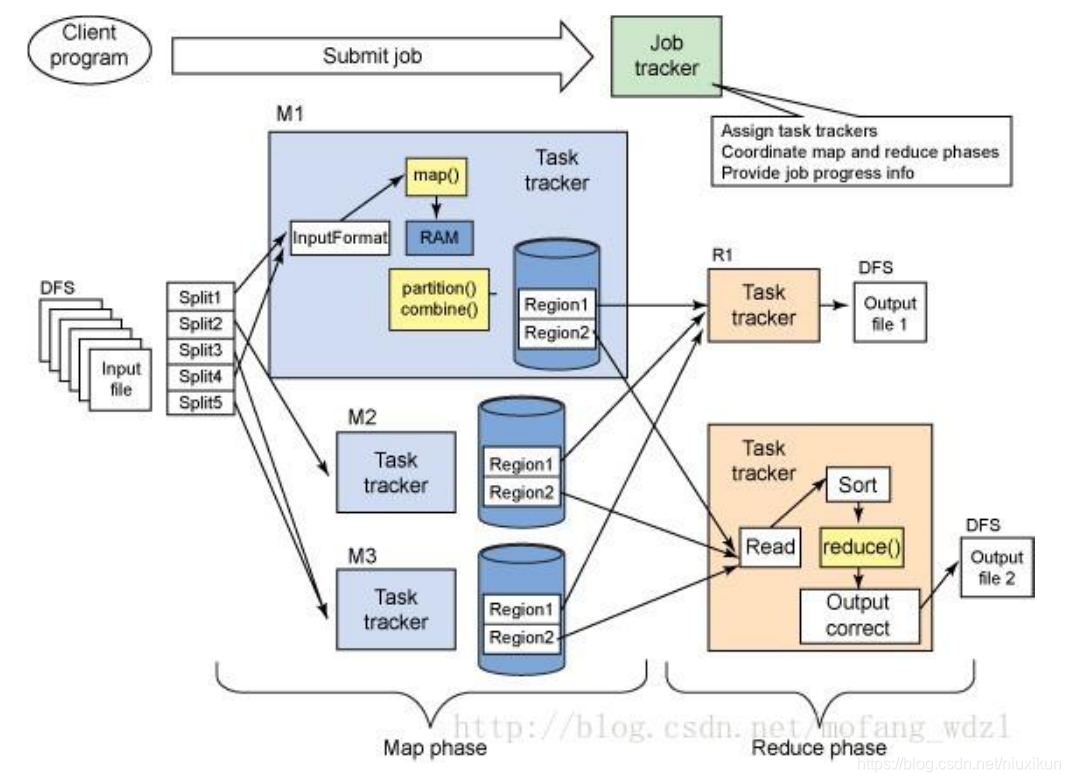
首先用户程序 (JobClient) 提交了一个 job,job 的信息会发送到 Job Tracker
中,Job Tracker 是 Map-reduce 框架的中心,他首先做任务分配,需要知道数据
分布在哪里,这意味着要和 HDFS Metadata Server 通讯;其次要根据数据分
布,分配任务给实际机器,这里又基本有两个步骤,先确定有哪些机器是存活
的、资源还剩余多少;另外,根据他们和数据的分布关系,做出任务分配策
略;然后开始分配任务,要将 MapReduce逻辑分发到各台机器上;然后,要监
控各个机器上 Mapper、Reducer实例的任务进度,如果失败要回收资源并重新
分配资源,指定数据索引,重新执行














 2725
2725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









