







一文读懂BERT(原理篇)
2018年的10月11日,Google发布的论文《Pre-training of Deep Bidirectional Transformers for Language Understanding》,成功在 11 项 NLP 任务中取得 state of the art 的结果,赢得自然语言处理学界的一片赞誉之声。
本文是对近期关于BERT论文、相关文章、代码进行学习后的知识梳理,仅为自己学习交流之用。因笔者精力有限,如果文中因引用了某些文章观点未标出处还望作者海涵,也希望各位一起学习的读者对文中不恰当的地方进行批评指正。
1)资源梳理
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
论文原文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
官方代码和预训练模型
Github: https://github.com/google-research/bert
2)NLP发展史
关于NLP发展史,特别推荐weizier大佬的NLP的巨人肩膀。学术性和文学性都很棒,纵览NLP近几年的重要发展,对各算法如数家珍,深入浅出,思路清晰,文不加点,一气呵成。
现对NLP发展脉络简要梳理如下:

2001 - Neural language models(神经语言模型)
2008 - Multi-task learning(多任务学习)
2013 - Word embeddings(词嵌入)
2013 - Neural networks for NLP(NLP神经网络)
2014 - Sequence-to-sequence models
2015 - Attention(注意力机制)
2015 - Memory-based networks(基于记忆的网络)
2018 - Pretrained language models(预训练语言模型)
2001 - 神经语言模型
第一个神经语言模型是Bengio等人在2001年提出的前馈神经网络:如下图所示:
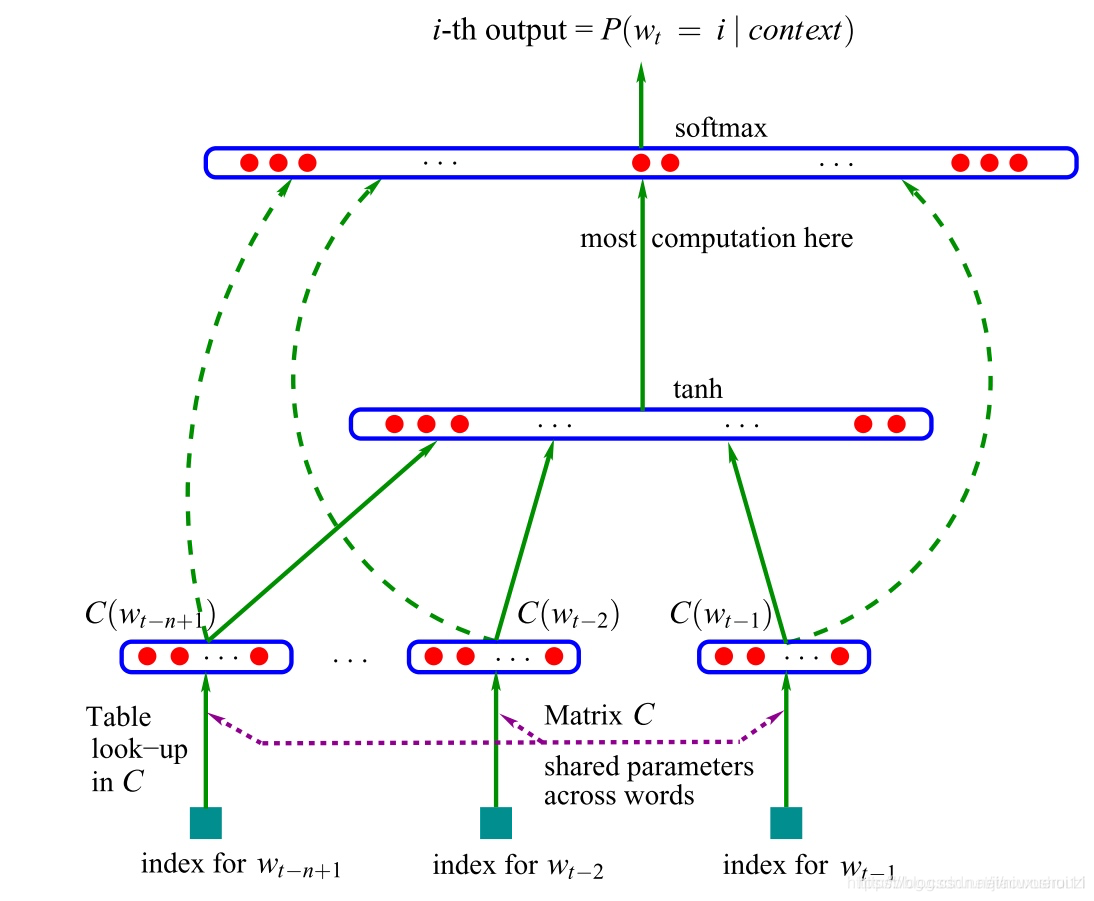
这个模型将从表C中查找到的n个单词作为输入向量表征。这种向量被现在的学者们称做“词嵌入”。这些词嵌入级联后被输入到一个隐藏层中,该隐藏层的输出又被输入到softmax层。
语言建模通常是应用RNN时的第一步,是一种非监督学习形式。尽管它很简单,但却是本文后面讨论的许多技术发展的核心:
词嵌入:word2vec 的目标是简化语言建模。
sequence-to-sequence 模型:这种模型通过一次预测一个单词生成一个输出序列。
预训练语言模型:这些方法使用来自语言模型的表述进行迁移学习。
反过来讲,这意味着近年来 NLP 的许多重要进展都可以归结为某些形式的语言建模。为了“真正”理解自然语言,仅仅从文本的原始形式中学习是不够的。我们需要新的方法和模型。
2008- 多任务学习
多任务学习是在多个任务上训练的模型之间共享参数的一种通用方法。在神经网络中,可以通过给不同层施以不同的权重,来很容易地实现多任务学习。多任务学习的概念最初由Rich Caruana 在1993年提出,并被应用于道路跟踪和肺炎预测(Caruana,1998)。直观地说,多任务学习鼓励模型学习对许多任务有用的表述。这对于学习一般的、低级的表述形式、集中模型的注意力或在训练数据有限的环境中特别有用。
在2008年,Collobert 和 Weston 将多任务学习首次应用于 NLP 的神经网络。在他们的模型中,查询表(或单词嵌入矩阵)在两个接受不同任务训练的模型之间共享,如下面的图所示。
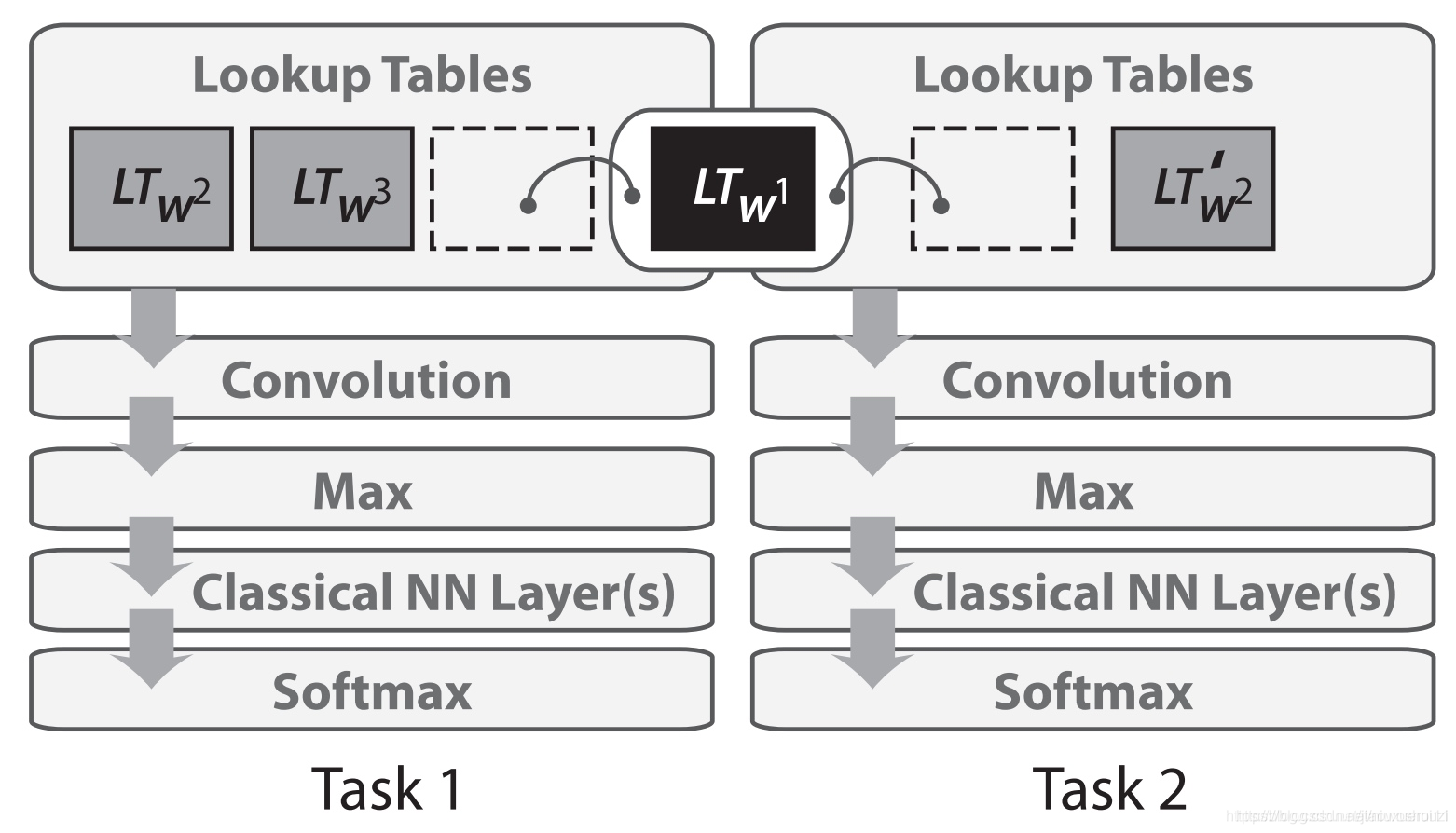
2013- 词嵌入
用稀疏向量表示文本,即所谓的词袋模型在NLP上有着悠久的历史,词嵌入技术是通过去除隐藏层,逼近目标,从而使得单词的嵌入的训练更加高效,虽然 这些技术比较简单,但是他们与word2vec配合使用,便能使大规模的词嵌入技术成为可能。
Word2vec有两种风格,如下图所示:连续自带CBOW和skip-gam, 前一个的目标是根据周围的单词预测周围的单词,后者是根据周围的单词预测中心单词。
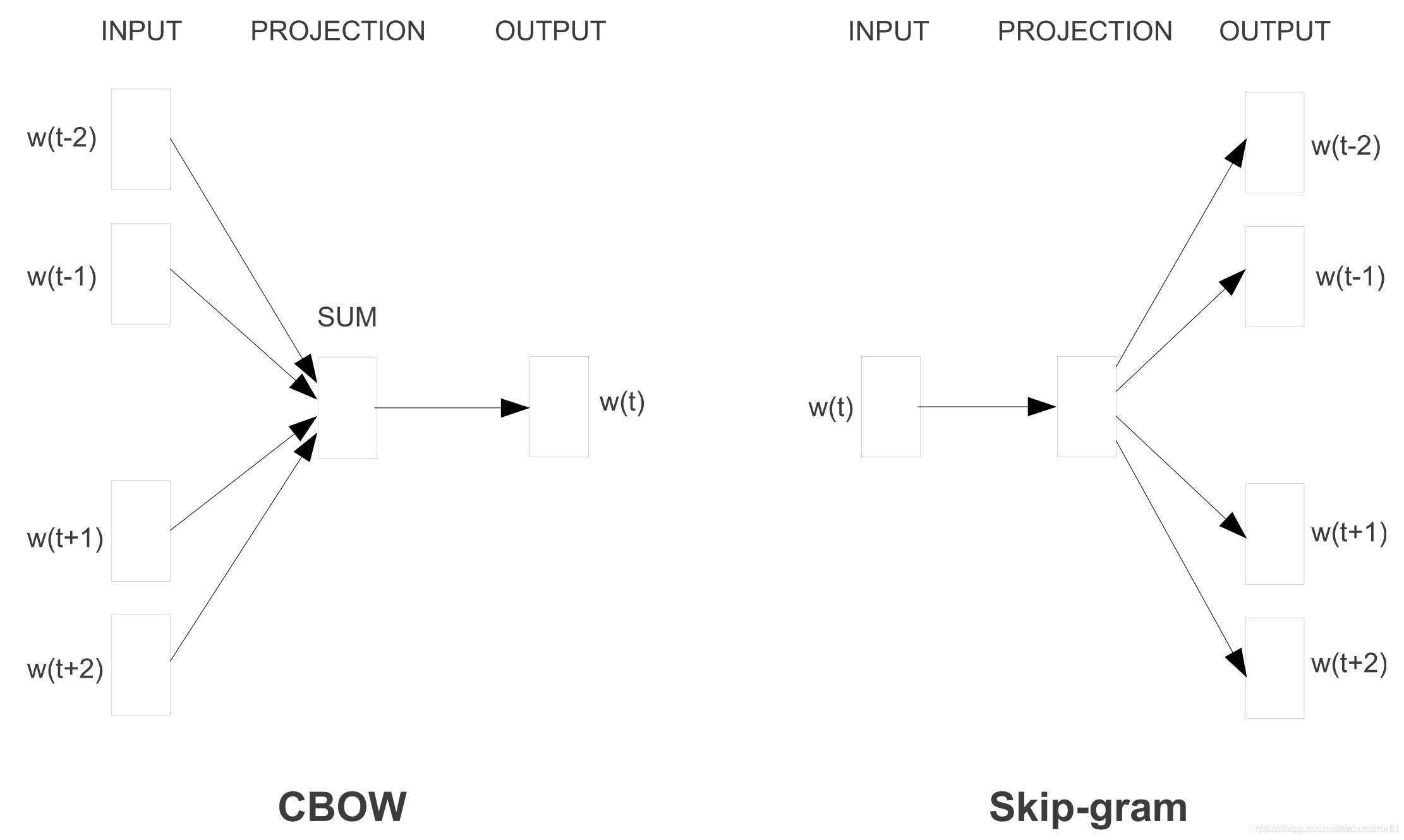
虽然这些嵌入在概念上与使用前馈神经网络学习的嵌入在概念上没有区别,但是在一个非常大的语料库上训练之后,它们就能够捕获诸如性别、动词时态和国家-首都关系等单词之间的特定关系,如下图所示。
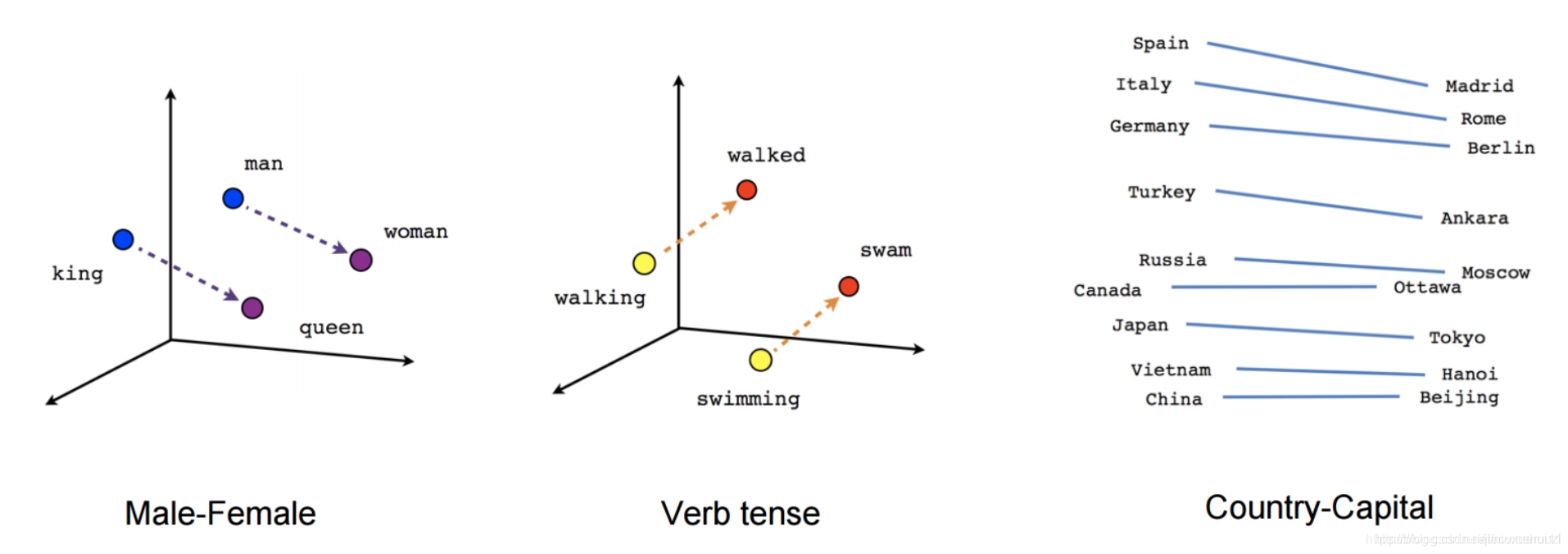
2013 - NLP 神经网络
使用最广泛的主要三种神经网络: 循环神经网络,卷积神经网络,长短时记忆网络。
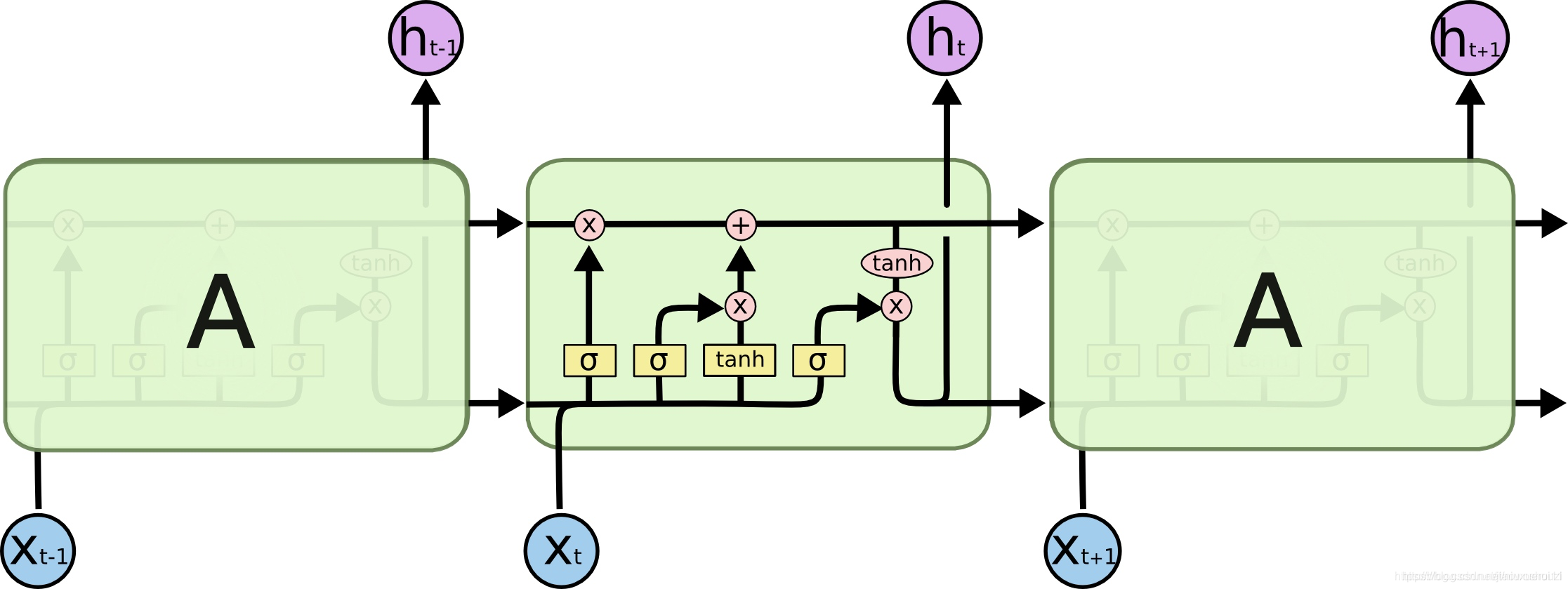
循环神经网络是NLP中普遍存在的动态输入序列的一个最佳的方案, 很快被LSTM替代,下面是对LSTM进行可视化显示。,双向LSTM常常被用作处理左右两边的上下文。
卷积神经网络常常被用作计算机视觉技术,本文的卷积神经网络只在两个维度工作,其中滤波器只需要沿着时间维度移动,下图是 NLP中的 cnn的使用 。
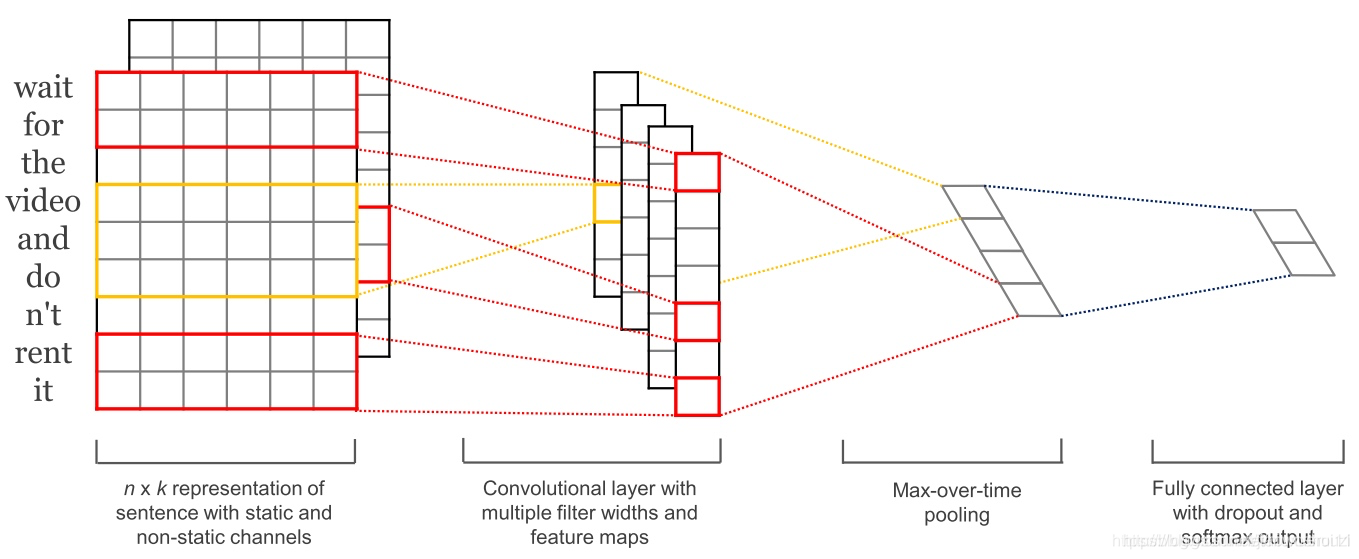
卷积神经网络比cnn更加并行化, 因为其在每个时间步长的状态只依赖于上下文,而不像RNN那样以来与过去的状态,使用膨胀卷积,增大卷积的感受野, 使得网络更有能力捕获上下文, CNN和LSTM可以组合使用哦个,卷积也可以用来LSTM加速。
递归神经网络 RNN 和 CNN 都将语言视为一个序列。然而,从语言学的角度来看,语言本质上是层次化的:单词被组合成高阶短语和从句,这些短语和从句本身可以根据一组生产规则递归地组合。将句子视为树而不是序列的语言学启发思想产生了递归神经网络(Socher 等人, 2013),如下图所示
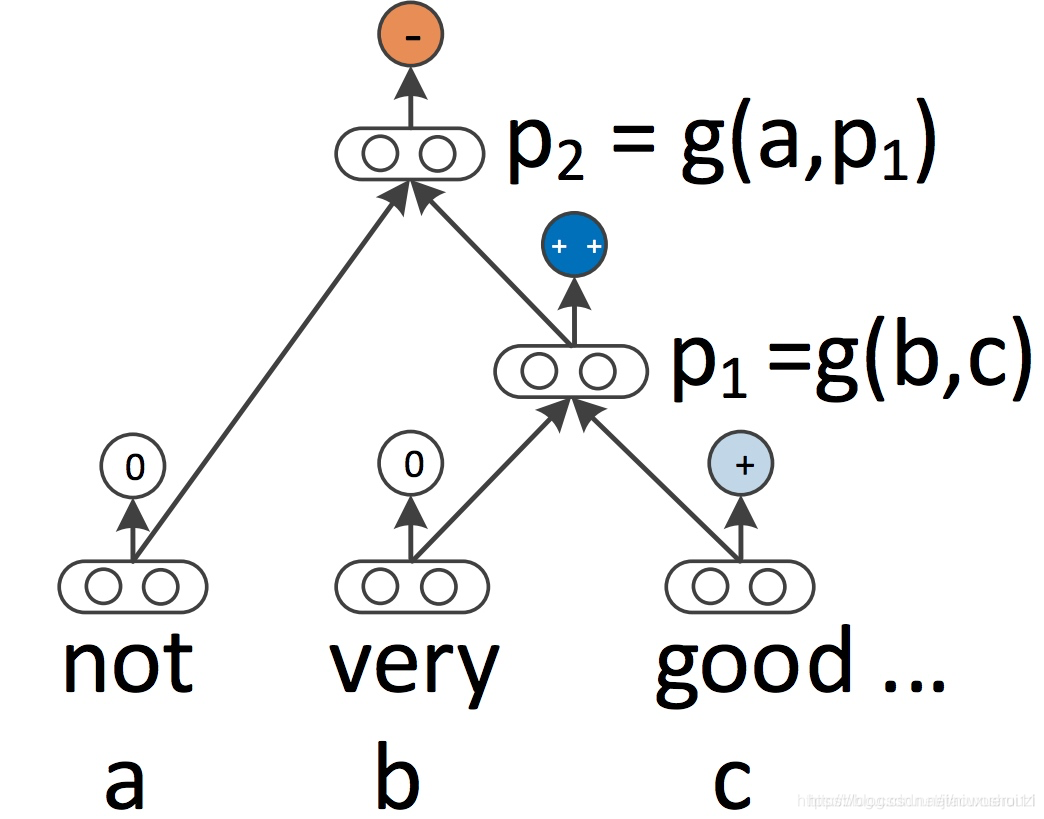
递归神经网络从下到上构建序列的表示,这一点不同于从左到右或从右到左处理句子的 RNN。在树的每个节点上,通过组合子节点的结果来计算新的结果。由于树也可以被视为在 RNN 上强加不同的处理顺序,所以 LSTM 自然地也被扩展到树上(Tai等,2015)。
RNN 和 LSTM 可以扩展到使用层次结构。单词嵌入不仅可以在本地学习,还可以在语法语境中学习(Levy & Goldberg等,2014);语言模型可以基于句法堆栈生成单词(Dyer等,2016);图卷积神经网络可以基于树结构运行(Bastings等,2017)。
2014-sequence-to-sequence 模型
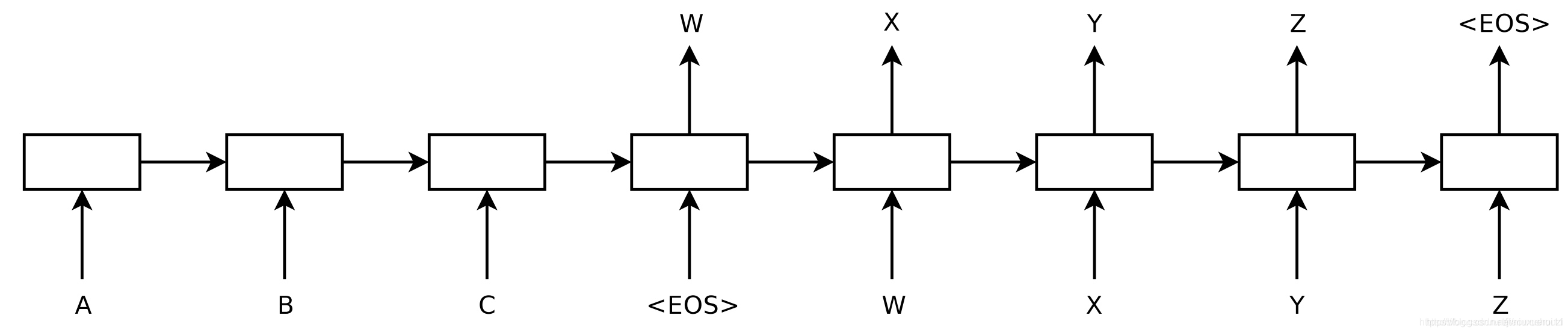
这是一个使用神经网络将序列映射到另一个序列的通用框架, 在这个网络中,编码器神经网络逐符号处理每一个句子,并将其压缩为一个向量表示, 然后,一个解码器神经网络根据编码器 状态 逐符号输出预测值,并将之前预测的符号作为每一步的输入, 如下图所示:
2015- 注意力机制
sequence - to - sequence 主要的瓶颈是必须要将原序列压缩成一个固定大小的向量 ,注意力机制允许解码器回头查看原序列中的隐藏状态来缓解这一个问题, 然后将其加权平均对其进作为额外输入给解码器,如下图所示:
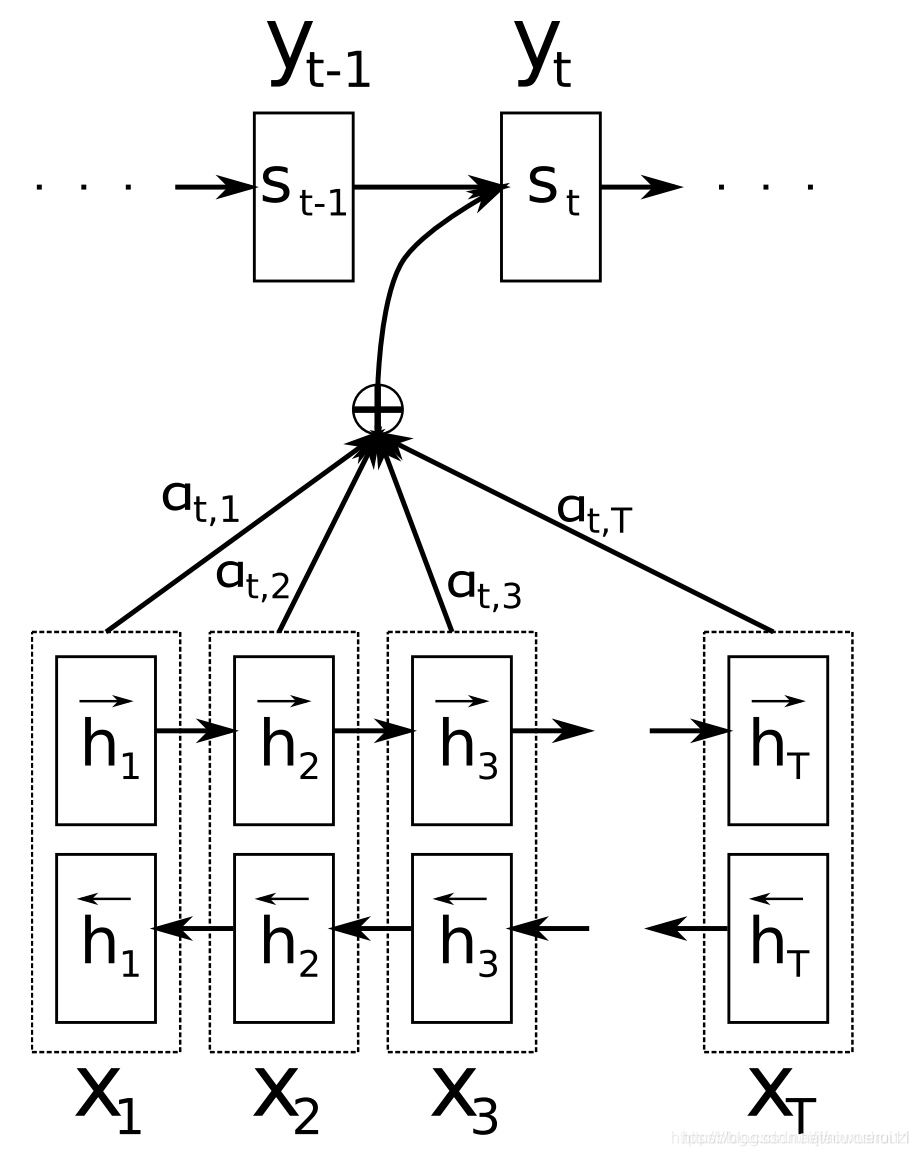
BERT:一切过往, 皆为序章
Attention机制讲解
Attention 机制能够让模型对重要的信息重点关注, 他不算是一个完整的模型,应当是一种技术,能够作用于任何序列模型中。
Transrofmer模型讲解
下期学习讲解@@@
















 1018
1018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











