









 文章讲述了如何使用Scala提升大规模数据上传到Elasticsearch的效率,以及环境配置和基础操作示例。
文章讲述了如何使用Scala提升大规模数据上传到Elasticsearch的效率,以及环境配置和基础操作示例。
前言
因为某些原因,需要把MySQL的数据上传到Es
刚开始使用Python上传数据到Es,数据量少的话倒没事,
后面数据量达到了三四十万,甚至更高
就发觉速度很慢哪怕是批量以及多线程。
无意之中发现,使用Scala非快。
经过之前测试对比Python批上传:
批量上传一万条,需要十几秒
同样的数据在Scala批上传:
批量上传十万条数据,需要不到十秒
(以上都没算上读表时间)
并且在读取MySQL表数据时,速度也是比Python快十倍左右,
这很难不爱。
一、环境准备
1.下载IDEA
建议下载2023.1.3版本
https://www.jetbrains.com/datagrip/download/other.html
搭配以下神奇的网站
https://aijihuo.cn/jetbrains-license-servers.html
2. 配置环境
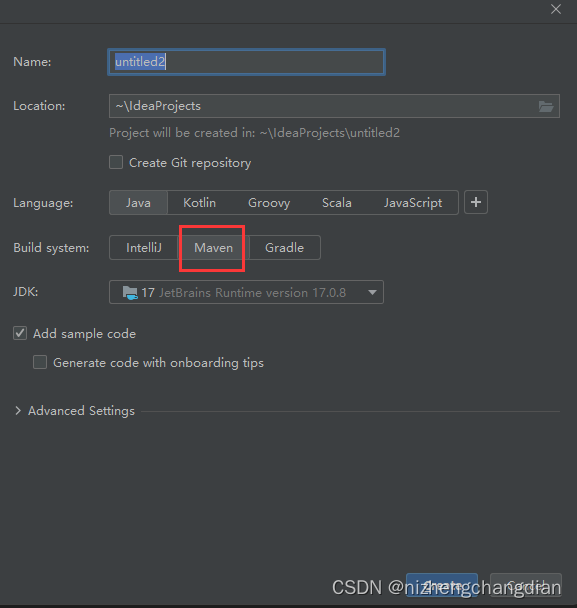
完成后,创建Maven项目
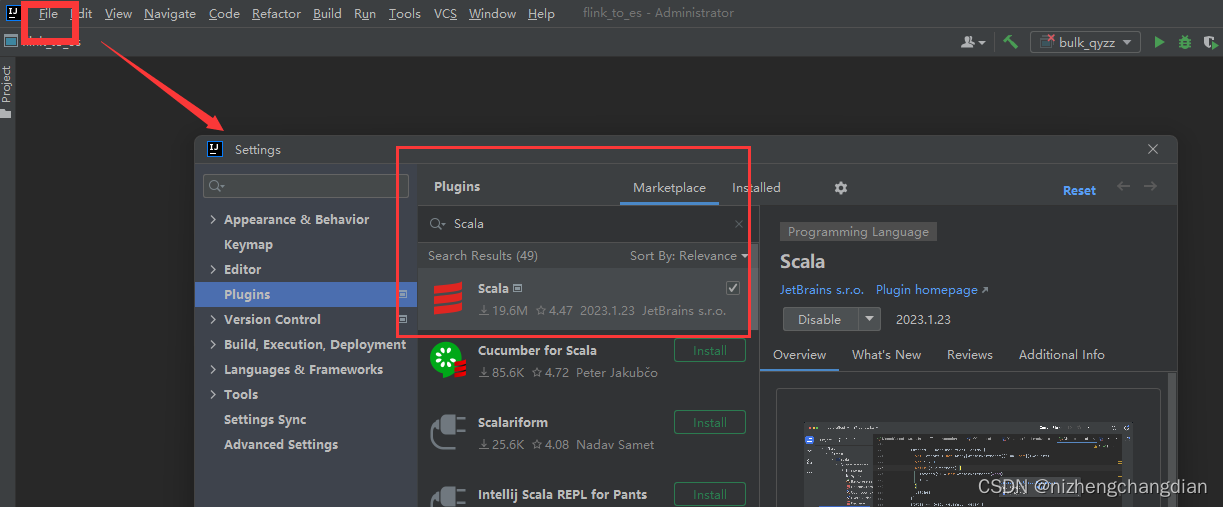
下载好Scala插件
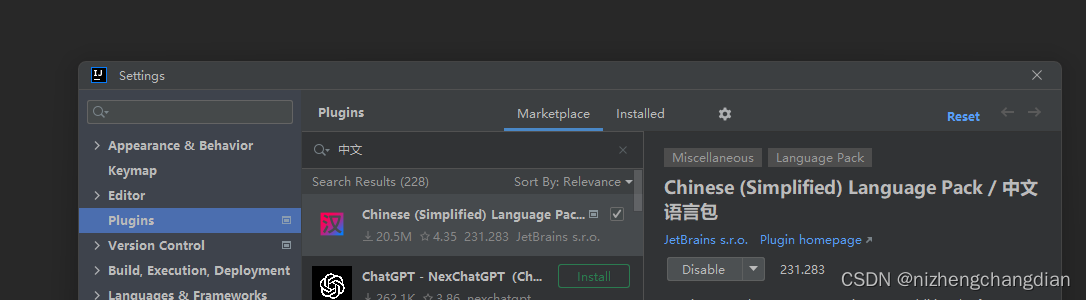
如果想要中文那就下载个中文语言包,重启生效
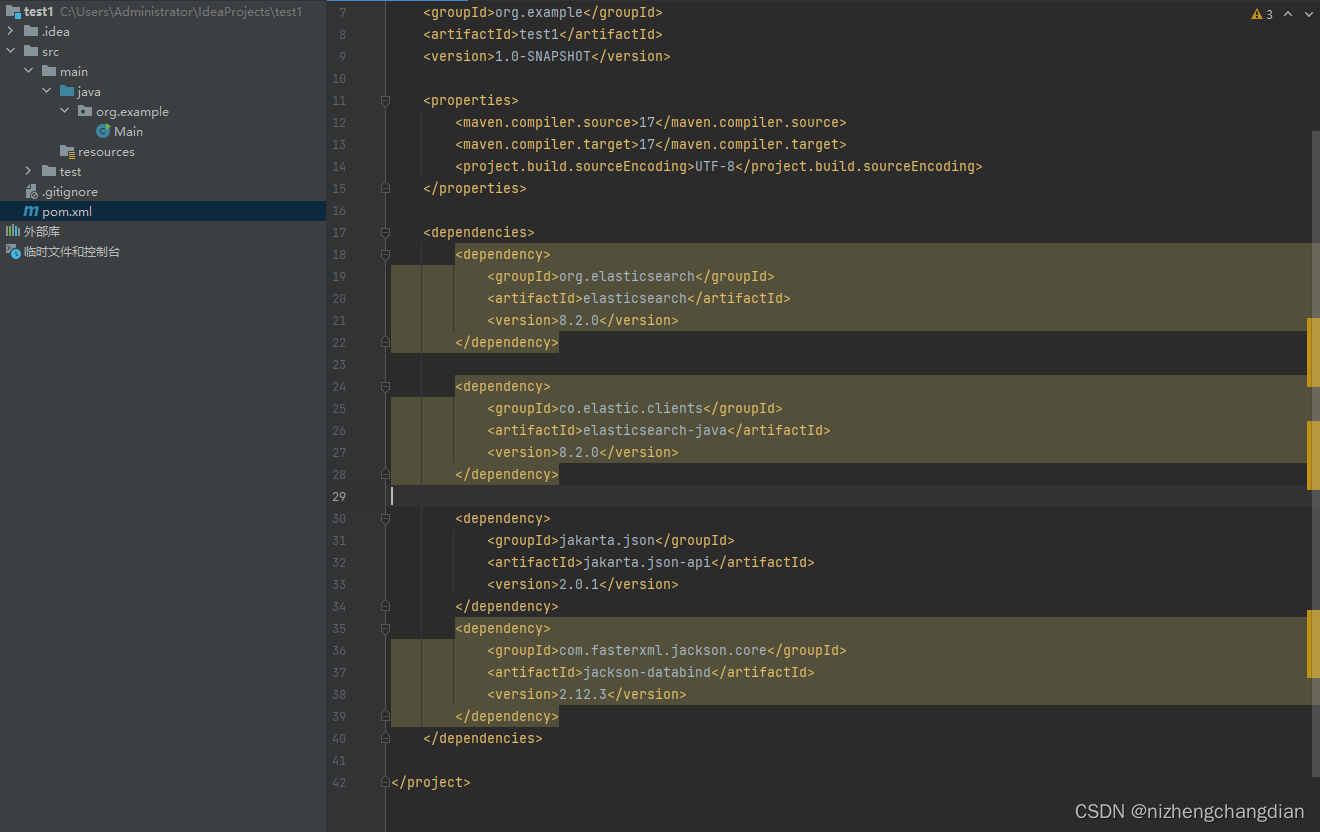
来到pom文件添加依赖
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>8.2.0</version>
</dependency>
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.2.0</version>
</dependency>
<dependency>
<groupId>jakarta.json</groupId>
<artifactId>jakarta.json-api</artifactId>
<version>2.0.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.12.3</version>
</dependency>
</dependencies>
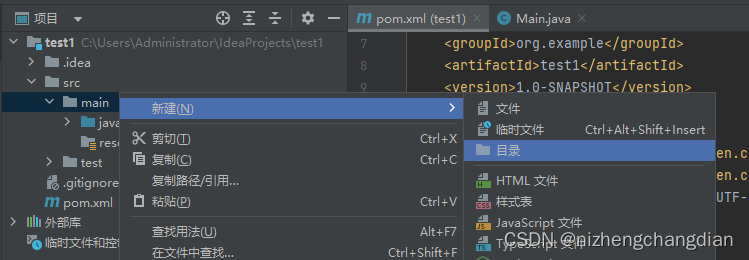
main目录下新建一个目录,目录名自定义
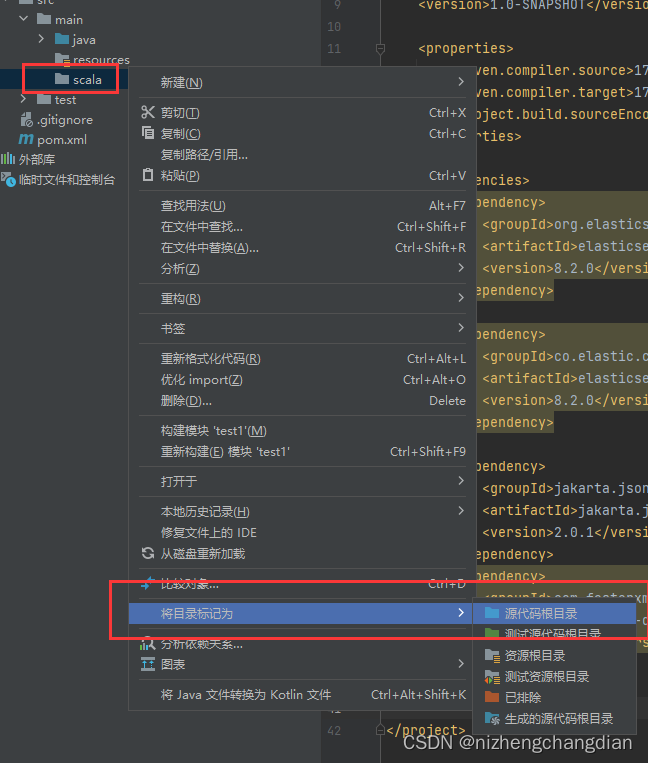
右键新建的目录标记为源代码根目录
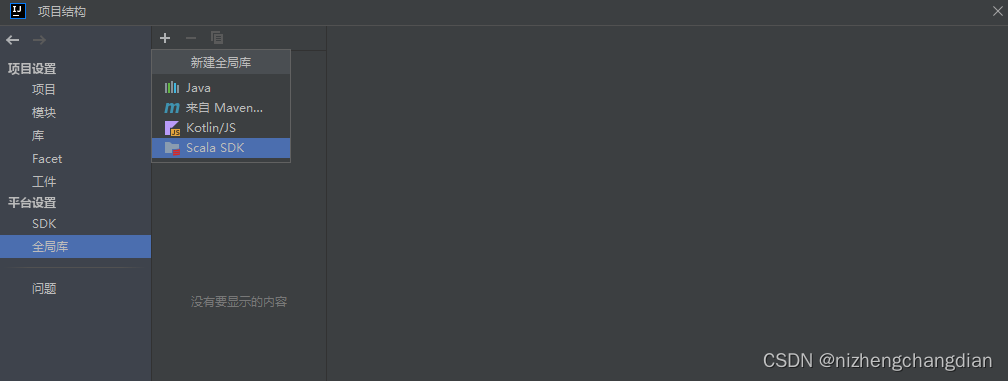
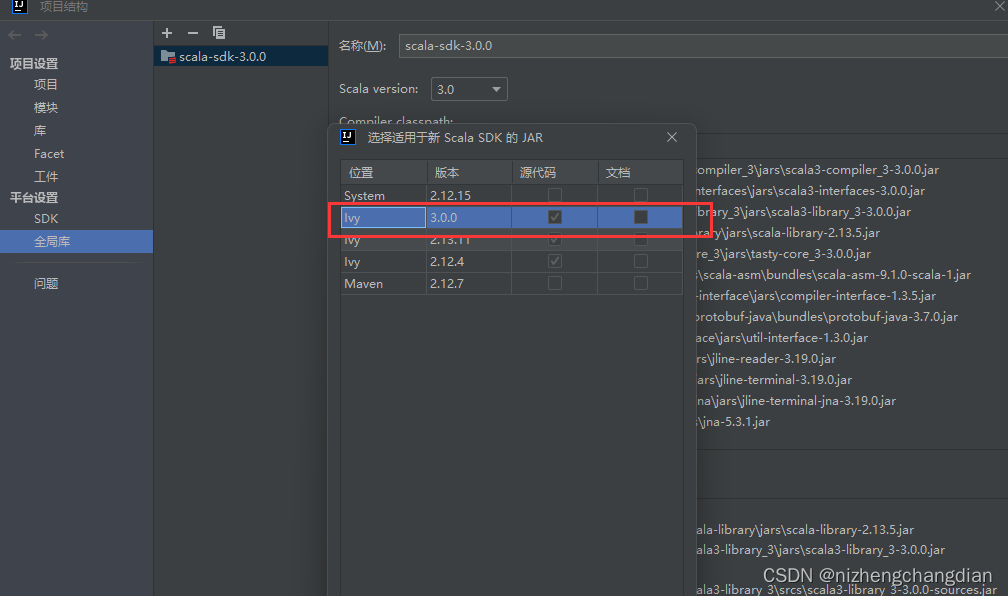
点击左上角文件---->项目结构----->全局库,添加Scala SDK
建议下载Scala3.0.0,我原先已经下载过了,如果你们没有可以点左下角去下载对应版本
点击SDK添加JDK,我用的是17版本,用1.8的也都可以
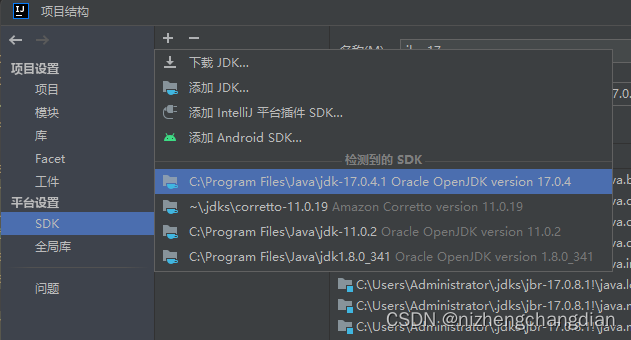
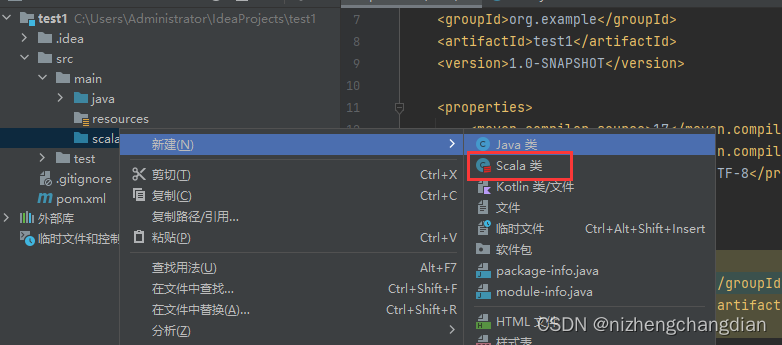
完成后,右键刚刚新建的目录可以看见Scala类
新建一个Scala类------->选择Object类
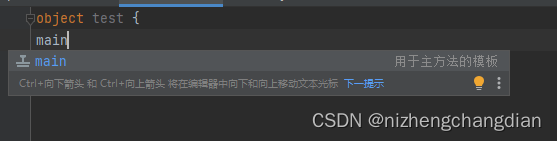
直接生成main方法
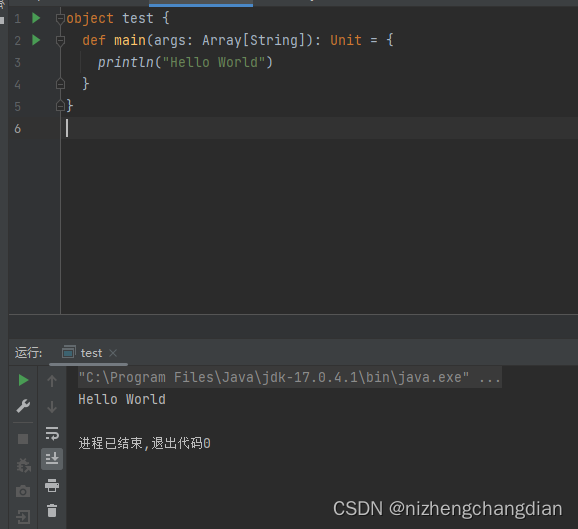
老规矩,打印Hello World
能够正常运行,即可搭建成功

二、基础语法
1. 判断、创建、删除索引
import co.elastic.clients.elasticsearch.ElasticsearchClient import co.elastic.clients.elasticsearch.indices.{CreateIndexRequest, DeleteIndexRequest, ExistsRequest} import co.elastic.clients.json.jackson.JacksonJsonpMapper import co.elastic.clients.transport.rest_client.RestClientTransport import org.apache.http.HttpHost import org.elasticsearch.client.RestClient import java.util import scala.util.Random object test { def main(args: Array[String]): Unit = { // TODO 配置连接es val restClient = RestClient.builder(new HttpHost("192.168.1.168", 9200)).build() val transport = new RestClientTransport(restClient, new JacksonJsonpMapper()) val client = new ElasticsearchClient(transport) // TODO 判断索引是否存在 返回布尔值 val ex = new ExistsRequest.Builder() .index("t1").build() // 设置索引名称 println("索引是否存在: " + client.indices().exists(ex).value()) // TODO 创建索引 val create = new CreateIndexRequest.Builder() .index("t1").build() client.indices().create(create) // 执行创建 // TODO 删除索引 val delete = new DeleteIndexRequest.Builder() .index("t1").build() client.indices().delete(delete) // 执行删除 transport.close() restClient.close() } }
2. 上传单条数据、数据查询指定数据
import co.elastic.clients.elasticsearch.ElasticsearchClient import co.elastic.clients.elasticsearch._types.query_dsl.{MatchAllQuery, MatchQuery, Query} import co.elastic.clients.elasticsearch.core.bulk.{BulkOperation, IndexOperation} import co.elastic.clients.elasticsearch.core.{BulkRequest, CreateRequest, DeleteRequest, IndexRequest, SearchRequest} import co.elastic.clients.elasticsearch.indices.{CreateIndexRequest, DeleteIndexRequest, ExistsRequest} import co.elastic.clients.json.jackson.JacksonJsonpMapper import co.elastic.clients.transport.rest_client.RestClientTransport import org.apache.http.HttpHost import org.elasticsearch.client.{RequestOptions, RestClient} import java.util import scala.util.Random object test { def main(args: Array[String]): Unit = { // TODO 配置连接es val restClient = RestClient.builder(new HttpHost("192.168.1.168", 9200)).build() val transport = new RestClientTransport(restClient, new JacksonJsonpMapper()) val client = new ElasticsearchClient(transport) // TODO 上传数据 // 准备一条数据 val data = new util.HashMap[String, String]() data.put("name", "小王") data.put("sex", "男") data.put("age", "18") // Builder[util.HashMap]里面是上传的数据类型 val index = new IndexRequest.Builder[util.HashMap[String, String]] .index("t1") // 索引名称 .id("1") // 文档ID .document(data) // 要上传的数据 // .routing() 看需求可插入父id .build() client.index(index) // 执行上传 // TODO 查询语句 val matchQuery = new MatchQuery.Builder() .field("name") // 选择字段 .query("小王").build() // 需要匹配的数据 val query = new Query.Builder() .`match`(matchQuery).build() // 需要 MatchQuery 对象 // 创建 查询请求 val search = new SearchRequest.Builder() .index("t1") .query(query).build() // 需要 Query 对象 // 执行查询 val result = client.search(search, new Object().getClass) result.hits().hits().forEach(s => println("search: " + s.source().toString)) // 觉得麻烦可以使用 Lambda 表达式 如果不是Scala3.0.0可能会提示报错 val result2 = client.search( s => { s.query( q => q.`match`( m => m.field("name").query("小王") ) ).index("t1") } , new Object().getClass ) result2.hits().hits().forEach(e => println("Lambda 表达式: " + e.source().toString)) transport.close() restClient.close() } }控制台打印结果为:
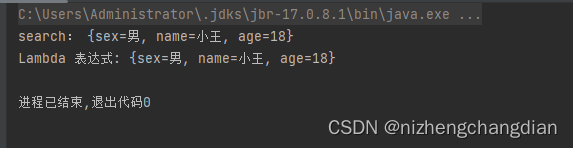
3. 批量上传、查询全部数据
import co.elastic.clients.elasticsearch.ElasticsearchClient import co.elastic.clients.elasticsearch._types.query_dsl.{MatchAllQuery, MatchQuery, Query} import co.elastic.clients.elasticsearch.core.bulk.{BulkOperation, IndexOperation} import co.elastic.clients.elasticsearch.core.{BulkRequest, CreateRequest, DeleteRequest, IndexRequest, SearchRequest} import co.elastic.clients.elasticsearch.indices.{CreateIndexRequest, DeleteIndexRequest, ExistsRequest} import co.elastic.clients.json.jackson.JacksonJsonpMapper import co.elastic.clients.transport.rest_client.RestClientTransport import org.apache.http.HttpHost import org.elasticsearch.client.{RequestOptions, RestClient} import java.util import scala.util.Random object test { def main(args: Array[String]): Unit = { // TODO 配置连接es val restClient = RestClient.builder(new HttpHost("192.168.1.168", 9200)).build() val transport = new RestClientTransport(restClient, new JacksonJsonpMapper()) val client = new ElasticsearchClient(transport) // TODO 批量上传 // 用于存储批数据 val opts = new util.ArrayList[BulkOperation]() // 创建多条数据 val names = List("小王", "小黑", "小白") var id = 1 for (name <- names) { val data = new util.HashMap[String, String]() data.put("name", name) data.put("age", (10 + Random.nextInt(21)).toString) // 随机生成10到30之间 val value = new IndexOperation.Builder[util.HashMap[String, String]] .index("t1") // 索引名称 .id(id.toString) // 文档id .document(data) // 每条数据 // .routing() //看需求可插入父id .build() val operation = new BulkOperation.Builder().index(value).build() opts.add(operation) id += 1 } // 创建批处理请求把批数据放进去 val bulkRequest = new BulkRequest.Builder().operations(opts).build() // 执行批量上传 val response = client.bulk(bulkRequest) println("上传是否异常: " + response.errors()) // 查看是否发生异常 // 查看数据 Lambda 表达式 val result = client.search( s => { s.query( q => q.`matchAll`( m => m ) ).index("t1") } , new Object().getClass ) result.hits().hits().forEach(e => println("数据: " + e.source().toString)) transport.close() restClient.close() } }控制台打印结果为:
好了,常用语句的基本语法你已经学会了,
现在开始做一个小练习吧。
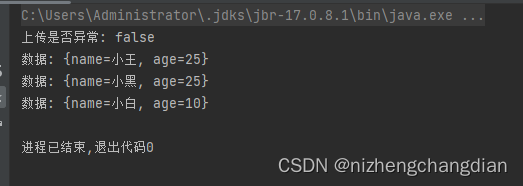
三、 小练习
要求
使用Scala读取本地MySQL数据库,使用批量将数据存储到Es。
提示:先到pom文件添加连接MySQL的依赖
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.47</version> </dependency>
参考代码
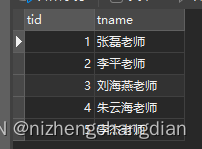
以下是当前我的MySQL数据
Ps:保密原因不能展示本地数据库的数据,
只能临时弄了几条数据做练习,
想要验证Scala批量是不是比Python快的话
可以测试使用两个批量插入一千,一万,十万的数据
从一千开始就能看见明显的速度差距了。
import co.elastic.clients.elasticsearch.ElasticsearchClient import co.elastic.clients.elasticsearch.core.BulkRequest import co.elastic.clients.elasticsearch.core.bulk.{BulkOperation, CreateOperation, IndexOperation} import co.elastic.clients.json.jackson.JacksonJsonpMapper import co.elastic.clients.transport.rest_client.RestClientTransport import co.elastic.clients.util.ObjectBuilder import jakarta.json.{Json, JsonObject} import org.apache.http.HttpHost import org.elasticsearch.client.{HttpAsyncResponseConsumerFactory, RequestOptions, RestClient} import java.io.StringReader import java.sql.{Connection, DriverManager, ResultSet} import java.time.Instant import java.util object mysql_to_es { def main(args: Array[String]): Unit = { val restClient = RestClient.builder(new HttpHost("192.168.1.168", 9200)).build val transport = new RestClientTransport(restClient, new JacksonJsonpMapper) val client = new ElasticsearchClient(transport) // 定义sql查询语句 val sql = "SELECT * FROM `demo`.`teacher`" // 配置本地MySQL var connection: Connection = null connection = DriverManager.getConnection("jdbc:mysql://127.0.0.1:13306/demo?useSSL=false&characterEncoding=UTF-8&useUnicode=true", "root", "1234") val statement = connection.createStatement() // 执行语句 val result_set: ResultSet = statement.executeQuery(sql) // 定义好批量上传需要的数据 val opts = new util.ArrayList[BulkOperation]() // 循环MySQL查询到的数据 while (result_set.next()) { val data = new util.HashMap[String, String]() val tid = result_set.getString("tid") //通过字段选取需要的值 也可以通过索引(从1开始) val tname = result_set.getString("tname") data.put("tid",tid) data.put("tname",tname) val value = new IndexOperation.Builder[util.HashMap[String, String]] .index("t2") .id(tid) // .routing() 如果需要父子表,在这设置好父的索引id .document(data) .build() val operation = new BulkOperation.Builder().index(value).build() opts.add(operation) } // 创建 批量请求 val request = new BulkRequest.Builder().operations(opts).build() val response = client.bulk(request) // 判断是否上传异常 println("是否异常: " + response.errors()) // 查询全部数据 val result = client.search( s => { s.query( q => q.`matchAll`( m => m ) ).index("t2") } , new Object().getClass ) result.hits().hits().forEach(e => println(e.source().toString)) transport.close() restClient.close() } }控制台打印结果
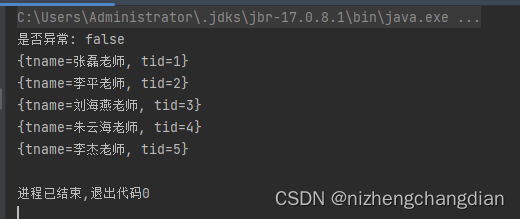
感谢观看
等以后有时间再出使用Flink监听本地端口、本地文件,MySQL,Kafka等数据,
实现实时上传至Es


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









