







01| etcd的前世今生:为什么Kubernetes使用etcd?
2013 年,有一个叫 CoreOS 的创业团队,他们构建了一个产品,Container Linux,它是
一个开源、轻量级的操作系统,侧重自动化、快速部署应用服务,并要求应用程序都在容
器中运行,同时提供集群化的管理方案,用户管理服务就像单机一样方便。
希望重启任意一节点的时候,用户服务不宕机 → 运行多个副本 → 多个副本如何协调,如何避免变更的时候所有副本不可用呢?
需要一个
协调服务来存储服务配置信息、提供分布式锁等能力 →
当然是分析业务场景、痛点、核心目标,然后是基于目标进行方案选
型,评估是选择社区开源方案还是自己造轮子。这其实就是我们遇到棘手问题时的通用解
决思路,CoreOS 团队同样如此。
一个协调服务,理想状态下大概需要满足以下5个目标:
1. 可用性角度:高可用
。协调服务作为集群的控制面存储,它保存了各个服务的部署、运
行信息。若它故障,可能会导致集群无法变更、服务副本数无法协调。业务服务若此时
出现故障,无法创建新的副本,可能会影响用户数据面。
2. 数据一致性角度:提供读取“最新”数据的机制
。既然协调服务必须具备高可用的目
标,就必然不能存在单点故障(single point of failure)→
多节点又引入了新的问
题,即多个节点之间的数据一致性如何保障?比如一个集群 3 个节点 A、B、C,从节点
A、B 获取服务镜像版本是新的,但节点 C 因为磁盘 I/O 异常导致数据更新缓慢,若控
制端通过 C 节点获取数据,那么可能会导致读取到过期数据,服务镜像无法及时更新。
3. 容量角度:低容量、仅存储关键元数据配置。
协调服务保存的仅仅是服务、节点的配置
信息(属于控制面配置),而不是与用户相关的数据。所以存储上不需要考虑数据分
片,无需过度设计。
4. 功能:增删改查,监听数据变化的机制
。协调服务保存了服务的状态信息,若服务有变
更或异常,相比控制端定时去轮询检查一个个服务状态,若能快速推送变更事件给控制
端,则可提升服务可用性、减少协调服务不必要的性能开销。
5. 运维复杂度:可维护性。
在分布式系统中往往会遇到硬件 Bug、软件 Bug、人为操作错
误导致节点宕机,以及新增、替换节点等运维场景,都需要对协调服务成员进行变更。
若能提供 API 实现平滑地变更成员节点信息,就可以大大降低运维复杂度,减少运维成
本,同时可避免因人工变更不规范可能导致的服务异常。
目标确定后,选择技术方案。
开源的ZooKeeper
从高可用性、数据一致性、功能这三个角度来说,ZooKeeper 是满足 CoreOS 诉求的。然
而当时的 ZooKeeper 不支持通过 API 安全地变更成员,需要人工修改一个个节点的配
置,并重启进程。
其次 ZooKeeper 是用 Java 编写的,部署较繁琐,占用较多的内存资源,同时
ZooKeeper RPC 的序列化机制用的是 Jute,自己实现的 RPC API。无法使用 curl 之类的
常用工具与之互动,CoreOS 期望使用比较简单的 HTTP + JSON。
最后自己造轮子
etcd v1
和
v2
诞生
解决目标二,数据一致性问题 → 引入共识算法
常见地
共识算法有Paxos、ZAB、Raft等。 CoreOS团队选择了易理解实现地Raft算法。
它将复杂的一致性问题分解成 Leader 选举、日志同步、安全性三个相
对独立的子问题,只要集群一半以上节点存活就可提供服务,具备良好的可用性。
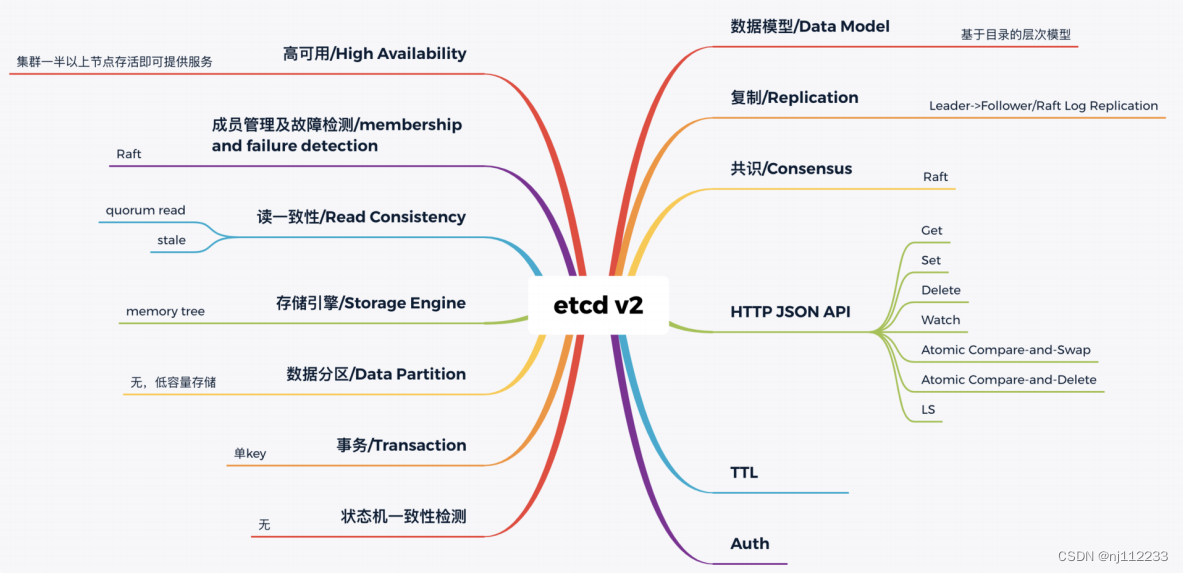
数据模型(Data Model)和API
数据模型参考了Zookeeper,使用基于目录地层级模式。
API相比Zookeeper来说,使用了简单、易用地REST API,提供了常用地Get/Set/Delete/Watch等API,实现了对key-value数据地查询、更新、删除、监听等操作。
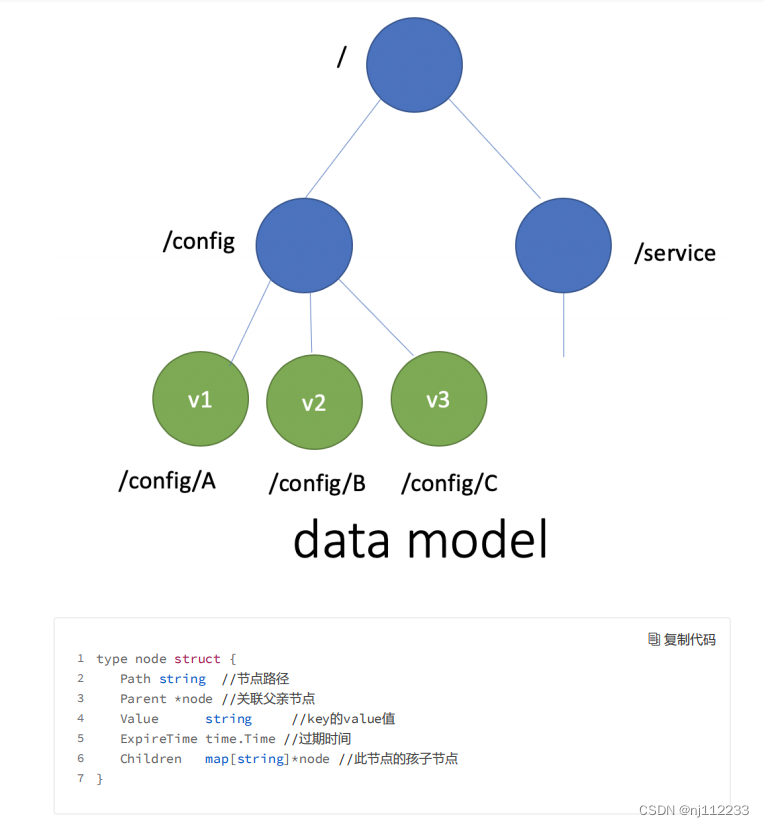
key-value存储引擎上,Zookeeper使用地是 Concurrent HashMap,而etcd使用地是简单内存树,它的节点数据结构精简后如下,节点路径、值、孩子节点信息。
简单内存树是一个典型地低容量设计,数据全放在内存,无需考虑数据分片,只能保存key地最新版本,简单易实现。
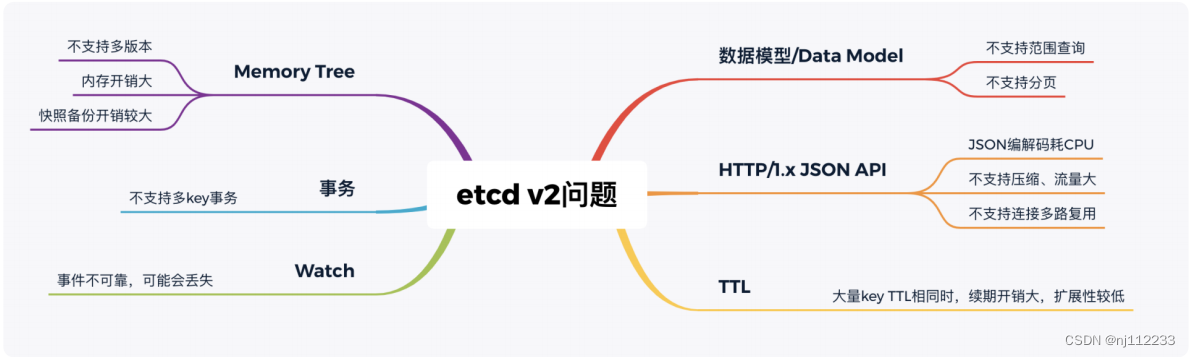
解决痛点:
在内存开销、Watch 事件可靠性、功能局限上,它通过引入 B-tree、boltdb 实现一个 MVCC 数据库,数据模型从层次型目录结构改成扁平的 key-value,提供稳定可靠的事件 通知,实现了事务,支持多 key 原子更新,同时基于 boltdb 的持久化存储,显著降低了 etcd 的内存占用、避免了 etcd v2 定期生成快照时的昂贵的资源开销
性能上,首先 etcd v3 使用了 gRPC API,使用 protobuf 定义消息,消息编解码性能相比
JSON 超过 2 倍以上,并通过 HTTP/2.0 多路复用机制,减少了大量 watcher 等场景下的
连接数。
其次使用 Lease 优化 TTL 机制,每个 Lease 具有一个 TTL,相同的 TTL 的 key 关联一个
Lease,Lease 过期的时候自动删除相关联的所有 key,不再需要为每个 key 单独续期。
最后是 etcd v3 支持范围、分页查询,可避免大包等 expensive request。
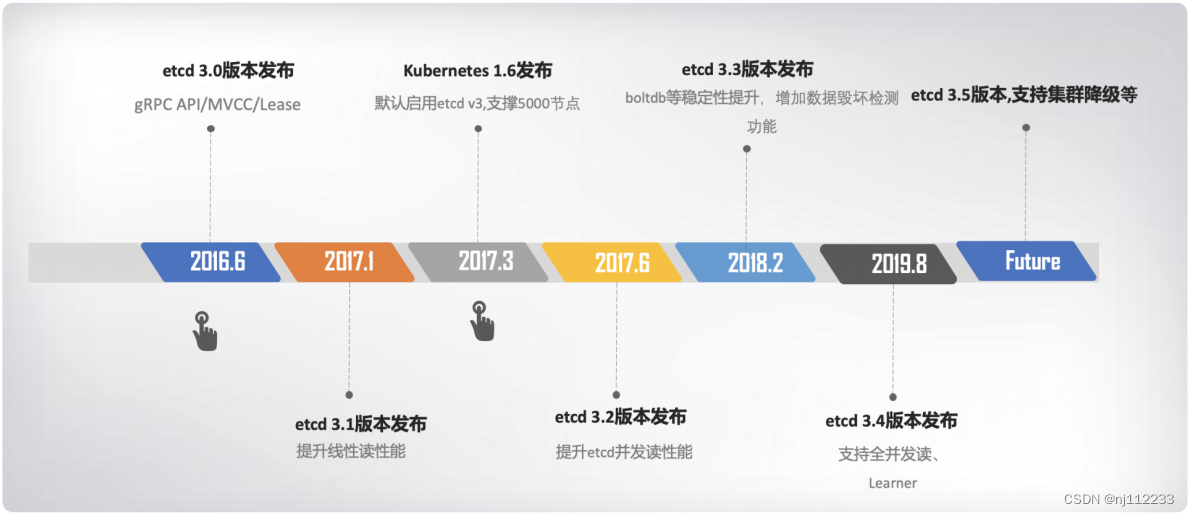
etcd 为什么有 v2 和 v3 两个大版本,etcd 如何从 HTTP/1.x API 到 gRPC API、单版本数据库到多版本数据库、内存树到 boltdb、TTL 到 Lease、单 key 原子更新到支持多 key 事务的演进过程有个清晰了解。
02| 基础架构:etcd一个读请求是如何执行的?
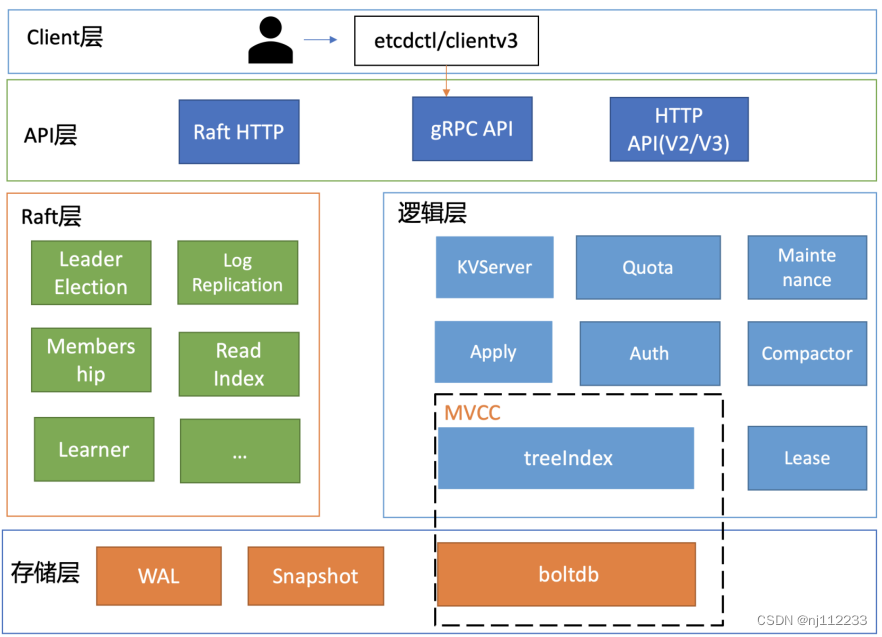
图1 etcd v3 简要基础架构图















 191
191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









