









1 Historical Node
Historical Node的职责单一,就是负责加载Druid中非实时窗口内且满足加载规则的所有历史数据的Segment。每一个Historical Node只与Zookeeper保持同步,不与其他类型节点或者其他Historical Node进行通信。
根据上节知晓,Coordinator Nodes会定期(默认为1分钟)去同步元信息库,感知新生成的Segment,将待加载的Segment信息保存在Zookeeper中在线的Historical Nodes的load queue目录下,当Historical Node感知到需要加载新的Segment时,首先会去本地磁盘目录下查找该Segment是否已下载,如果没有,则会从Zookeeper中下载待加载Segment的元信息,此元信息包括Segment存储在何处、如何解压以及如何如理该Segment。Historical Node使用内存文件映射方式将index.zip中的XXXXX.smoosh文件加载到内存中,并在Zookeeper中本节点的served segments目录下声明该Segment已被加载,从而该Segment可以被查询。对于重新上线的Historical Node,在完成启动后,也会扫描本地存储路径,将所有扫描到的Segment加载如内存,使其能够被查询。
2 Broker Node
Broker Node是整个集群查询的入口,作为查询路由角色,Broker Node感知Zookeeper上保存的集群内所有已发布的Segment的元信息,即每个Segment保存在哪些存储节点上,Broker Node为Zookeeper中每个dataSource创建一个timeline,timeline按照时间顺序描述了每个Segment的存放位置。我们知道,每个查询请求都会包含dataSource以及interval信息,Broker Node根据这两项信息去查找timeline中所有满足条件的Segment所对应的存储节点,并将查询请求发往对应的节点。
对于每个节点返回的数据,Broker Node默认使用LRU缓存策略;对于集群中存在多个Broker Node的情况,Druid使用memcached共享缓存。对于Historical Node返回的结果,Broker Node认为是“可信的”,会缓存下来,而Real-Time Node返回的实时窗口内的数据,Broker Node认为是可变的,“不可信的”,故不会缓存。所以对每个查询请求,Broker Node都会先查询本地缓存,如果不存在才会去查找timeline,再向相应节点发送查询请求。
3 Coordinator Node
Coordinator Node主要负责Druid集群中Segment的管理与发布,包括加载新Segment、丢弃不符合规则的Segment、管理Segment副本以及Segment负载均衡等。如果集群中存在多个Coordinator Node,则通过选举算法产生Leader,其他Follower作为备份。
Coordinator会定期(默认一分钟)同步Zookeeper中整个集群的数据拓扑图、元信息库中所有有效的Segment信息以及规则库,从而决定下一步应该做什么。对于有效且未分配的Segment,Coordinator Node首先按照Historical Node的容量进行倒序排序,即最少容量拥有最高优先级,新的Segment会优先分配到高优先级的Historical Node上。由3.3.4.1节可知,Coordinator Node不会直接与Historical Node打交道,而是在Zookeeper中Historical Node对应的load queue目录下创建待加载Segment的临时信息,等待Historical Node去加载该Segment。
Coordinator在每次启动后都会对比Zookeeper中保存的当前数据拓扑图以及元信息库中保存的数据信息,所有在集群中已被加载的、却在元信息库中标记为失效或者不存在的Segment会被Coordinator Node记录在remove list中,其中也包括我们在3.3.3节中所述的同一Segment对应的新旧version,旧version的Segments同样也会被放入到remove list中,最终被逻辑丢弃。
对于离线的Historical Node,Coordinator Node会默认该Historical Node上所有的Segment已失效,从而通知集群内的其他Historical Node去加载该Segment。但是,在生产环境中,我们会遇到机器临时下线,Historical Node在很短时间内恢复服务的情况,那么如此“简单粗暴”的策略势必会加重整个集群内的网络负载。对于这种场景,Coordinator会为集群内所有已丢弃的Segment保存一个生存时间(lifetime),这个生存时间表示Coordinator Node在该Segment被标记为丢弃后,允许不被重新分配最长等待时间,如果该Historical Node在该时间内重新上线,则Segment会被重新置为有效,如果超过该时间则会按照加载规则重新分配到其他Historical Node上。
考虑一种最极端的情况,如果集群内所有的Coordinator Node都停止服务,整个集群对外依然有效,不过新Segment不会被加载,过期的Segment也不会被丢弃,即整个集群内的数据拓扑会一直保持不变,直到新的Coordinator Node服务上线。
4 Indexing Service
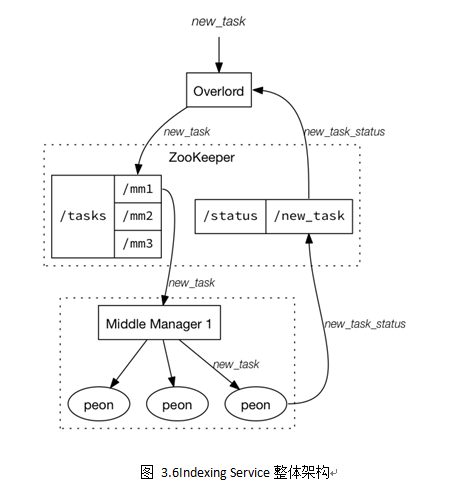
Indexing Service是负责“生产”Segment的高可用、分布式、Master/Slave架构服务。主要由三类组件构成:负责运行索引任务(indexing task)的Peon,负责控制Peon的MiddleManager,负责任务分发给MiddleManager的Overlord;三者的关系可以解释为:Overlord是MiddleManager的Master,而MiddleManager又是Peon的Master。其中,Overlord和MiddleManager可以分布式部署,但是Peon和MiddleManager默认在同一台机器上。图3.5给出了Indexing Service的整体架构。
Overlord
Overlord负责接受任务、协调任务的分配、创建任务锁以及收集、返回任务运行状态给调用者。当集群中有多个Overlord时,则通过选举算法产生Leader,其他Follower作为备份。
Overlord可以运行在local(默认)和remote两种模式下,如果运行在local模式下,则Overlord也负责Peon的创建与运行工作,当运行在remote模式下时,Overlord和MiddleManager各司其职,根据图3.6所示,Overlord接受实时/批量数据流产生的索引任务,将任务信息注册到Zookeeper的/task目录下所有在线的MiddleManager对应的目录中,由MiddleManager去感知产生的新任务,同时每个索引任务的状态又会由Peon定期同步到Zookeeper中/Status目录,供Overlord感知当前所有索引任务的运行状况。
Overlord对外提供可视化界面,通过访问http://:/console.html,我们可以观察到集群内目前正在运行的所有索引任务、可用的Peon以及近期Peon完成的所有成功或者失败的索引任务。
MiddleManager
MiddleManager负责接收Overlord分配的索引任务,同时创建新的进程用于启动Peon来执行索引任务,每一个MiddleManager可以运行多个Peon实例。
在运行MiddleManager实例的机器上,我们可以在${ java.io.tmpdir}目录下观察到以XXX_index_XXX开头的目录,每一个目录都对应一个Peon实例;同时restore.json文件中保存着当前所有运行着的索引任务信息,一方面用于记录任务状态,另一方面如果MiddleManager崩溃,可以利用该文件重启索引任务。
Peon
Peon是Indexing Service的最小工作单元,也是索引任务的具体执行者,所有当前正在运行的Peon任务都可以通过Overlord提供的web可视化界面进行访问。
5 Real-Time Node
在流式处理领域,有两种数据处理模式,一种为Stream Push,另一种为Stream Pull。
Stream Pull
如果Druid以Stream Pull方式自主地从外部数据源拉取数据从而生成Indexing Service Tasks,我们则需要建立Real-Time Node。Real-Time Node主要包含两大“工厂”:一个是连接流式数据源、负责数据接入的Firehose(中文翻译为水管,很形象地描述了该组件的职责);另一个是负责Segment发布与转移的Plumber(中文翻译为搬运工,同样也十分形象地描述了该组件的职责)。在Druid源代码中,这两个组件都是抽象工厂方法,使用者可以根据自己的需求创建不同类型的Firehose或者Plumber。Firehose和Plumber给我的感觉,更类似于Kafka_0.9.0版本后发布的Kafka Connect框架,Firehose类似于Kafka Connect Source,定义了数据的入口,但并不关心接入数据源的类型;而Plumber类似于Kafka Connect Sink,定义了数据的出口,也不关心最终输出到哪里。
Stream Push
如果采用Stream Push策略,我们需要建立一个“copy service”,负责从数据源中拉取数据并生成Indexing Service Tasks,从而将数据“推入”到Druid中,我们在druid_0.9.1版本之前一直使用的是这种模式,不过这种模式需要外部服务Tranquility,Tranquility组件可以连接多种流式数据源,比如Spark-Streaming、Storm以及Kafka等,所以也产生了Tranquility-Storm、Tranquility-Kafka等外部组件。Tranquility-Kafka的原理与使用将在3.4节中进行详细介绍。
6 外部拓展
Druid集群依赖一些外部组件,与其说依赖,不如说正是由于Druid开放的架构,所以用户可以根据自己的需求,使用不同的外部组件。
Deep Storage
Druid目前支持使用本地磁盘(单机模式)、NFS挂载磁盘、HDFS、Amazon S3等存储方式保存Segments以及索引任务日志。
Zookeeper
Druid使用Zookeeper作为分布式集群内部的通信组件,各类节点通过Curator Framework将实例与服务注册到Zookeeper上,同时将集群内需要共享的信息也存储在Zookeeper目录下,从而简化集群内部自动连接管理、leader选举、分布式锁、path缓存以及分布式队列等复杂逻辑。
Metadata Storage
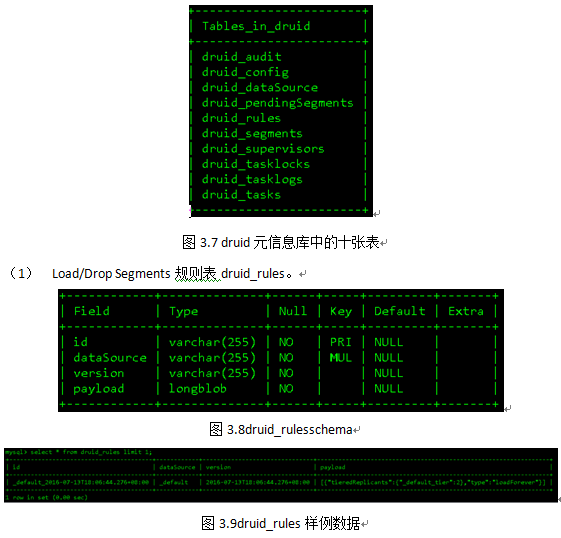
Druid集群元信息使用MySQL 或者PostgreSQL存储,单机版使用derby。在Druid_0.9.1.1版本中,元信息库druid主要包含十张表,均以“druid_”开头,如图3.7所示。
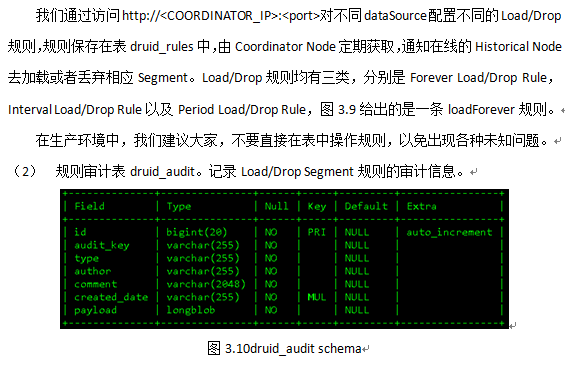
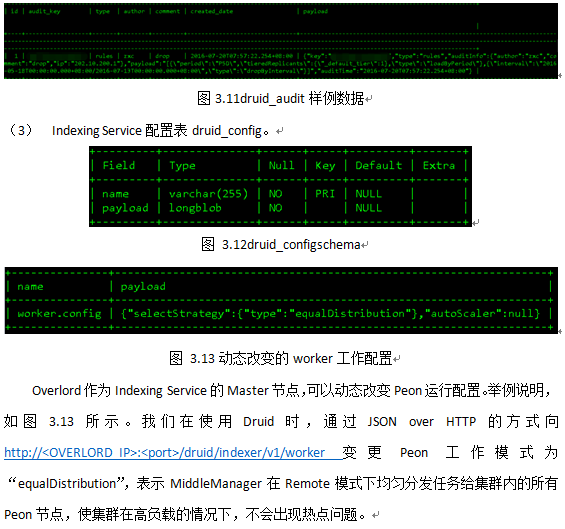
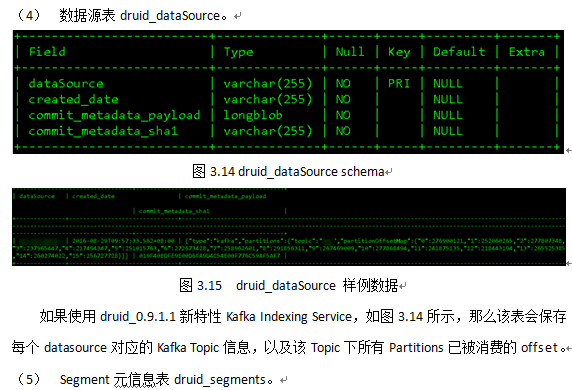
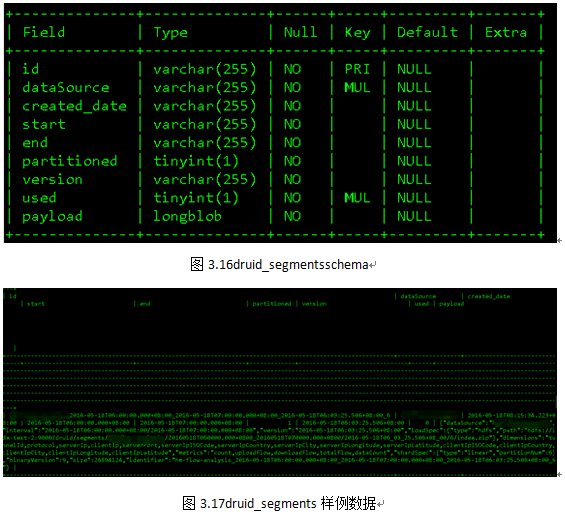
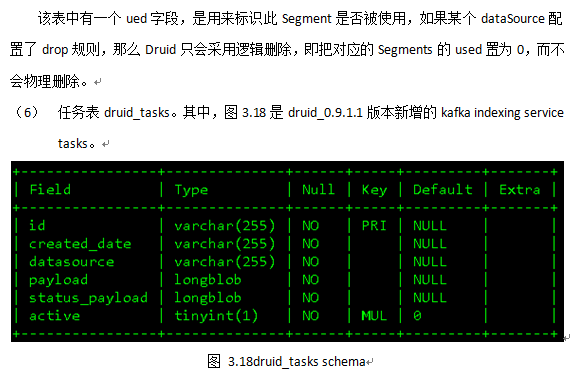
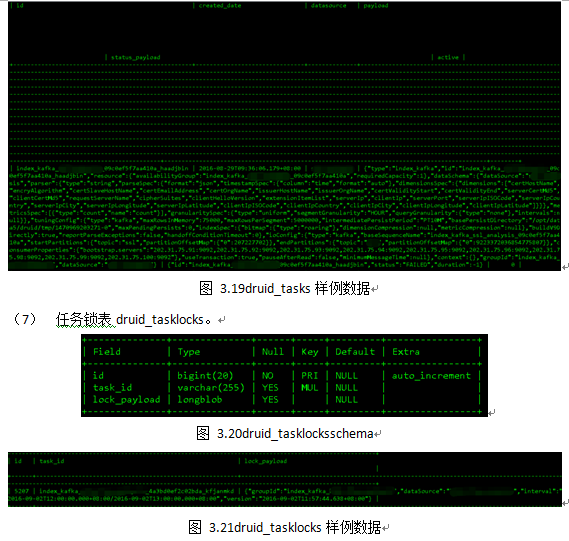
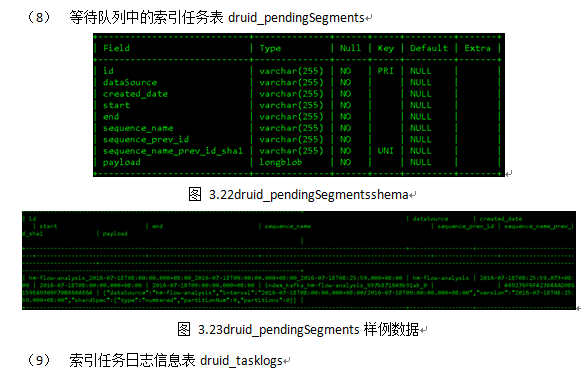
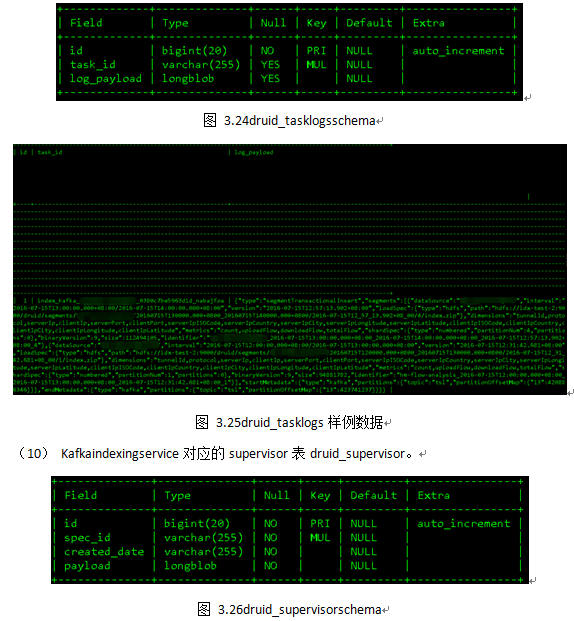
7 加载数据
对于加载外部数据,Druid支持两种模式:实时流(real-time ingestion)和批量导入(batch ingestion)。
Real-Time Ingestion
实时流过程可以采用Apache Storm、Apache Spark Streaming等流式处理框架产生数据,再经过pipeline工具,比如Apache Kafka、ActiveMQ、RabbitMQ等消息总线类组件,使用Stream Pull 或者Stream Push模式生成Indexing Service Tasks,最终存储在Druid中。
Batch Ingestion
批量导入模式可以采用结构化信息作为数据源,比如JSON、Avro、Parquet格式的文本,Druid内部使用Map/Reduce批处理框架导入数据。
8 高可用性
Druid高可用性可以总结以下几点:
Historical Node
如3.3.4.1节中所述,如果某个Historical Node离线时长超过一定阈值,Coordinator Node会将该节点上已加载的Segments重新分配到其他在线的Historical Nodes上,保证满足加载规则的所有Segments不丢失且可查询。
Coordinator Node
集群可配置多个Coordinator Node实例,工作模式为主从同步,采用选举算法产生Leader,其他Follower作为备份。当Leader宕机时,其他Follower能够迅速failover。
即使当所有Coordinator Node均失效,整个集群对外依然有效,不过新Segments不会被加载,过期的Segments也不会被丢弃,即整个集群内的数据拓扑会一直保持不变,直到新的Coordinator Node服务上线。
Broker Node
Broker Node与Coordinator Node在HA部署方面一致。
Indexing Service
Druid可以为同一个Segment配置多个Indexing Service Tasks副本保证数据完整性。
Real-Time
Real-Time过程的数据完整性主要由接入的实时流语义(semantics)决定。我们在0.9.1.1版本前使用Tranquility-Kafka组件接入实时数据,由于存在时间窗口,即在时间窗口内的数据会被提交给Firehose,时间窗口外的数据则会被丢弃;如果Tranquility-Kafka临时下线,会导致Kafka中数据“过期”从而被丢弃,无法保证数据完整性,同时这种“copy service”的使用模式不仅占用大量CPU与内存,又不满足原子操作,所以在0.9.1.1版本后,我们使用Druid的新特性Kafka Indexing Service,Druid内部使用Kafka高级Consumer API保证exactly-once semantics,尽最大可能保证数据完整性。不过我们在使用中,依然发现有数据丢失问题。
Metadata Storage
如果Metadata Storage失效,Coordinator则无法感知新Segment的生成,整个集群中数据拓扑亦不会改变,不过不会影响老数据的访问。
Zookeeper
如果Zookeeper失效,整个集群的数据拓扑不会改变,由于Broker Node缓存的存在,所以在缓存中的数据依然可以被查询。
9 数据分层
Druid访问控制策略采用数据分层(tier),有以下两种用途:
将不同的Historical Node划分为不同的group,从而控制集群内不同权限(priority)用户在查询时访问不同group。
通过划分tier,让Historical Node加载不同时间范围的数据。例如tier_1加载2016年Q1数据,tier_2加载2016年Q2数据,tier_3加载2016年Q3数据等;那么根据用户不同的查询需求,将请求发往对应tier的Historical Node,不仅可以控制用户访问请求,同时也可以减少响应请求的Historical Node数量,从而加速查询。















 1214
1214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









