







文章目录
Kafka学习资料(持续更新)
Books
- 《Kafka权威指南》Neha Narkhede Gwen Shapira Todd Palino著
Links
- IBM Cloud | What is Kafka
- What is Apache Kafka®? (A Confluent Lightboard by Tim Berglund) + ksqlDB
- Apache Kafka Explained (Comprehensive Overview) 展示了大量的手绘图来帮助理解Kafka,强烈推荐!
- Apache Kafka in 6 minutes 用手绘方式讲述了如何用Kafka来直播多场篮球比赛。
- It’s Okay To Store Data In Apache Kafka 一文描述了Kafka与传统Message Queue的区别,以及为什么可以用Kafka来做Event Store
- Red Hat AMQ streams (Kafka) on OpenShift
- Kafka Quick Start
- Kafa Introduction
- Kafka Documentation
Kafka基本概念
cluster - broker - topic - partition - message
- 一个Kafka Cluster(集群)一般有3个Broker(节点)组成。
- 按消息类别份,每个Broker(节点)可有多个Topic(主题)。
- 为了保证容错性,将一个Topic(主题)分成3个Partition(分区),并在Broker(节点)上和跨Broker(节点)复制Partition(分区)。
- Partition(分区)分为Partition leader和Partition follower。其中,Partition leader用来供生产者(Producer)写入消息,Partition follower复制Partition leader的数据,并可供消费者(Consumer)读取消息。
producer-consumer
- producer往topic内写入消息,消息可以被负载均衡地写入到各个partition的结尾,也可根据key写入指定的partition
- consumer订阅topic,并根据topic、partition和offset读取消息
- 在一个consumer不能及时消费完消息时,可以将多个consumer放入到一个consumer group来加大吞吐量,consumer group可以实现负载均衡,并保证一个消息仅被一个consumer读取
参见:
Kafka架构
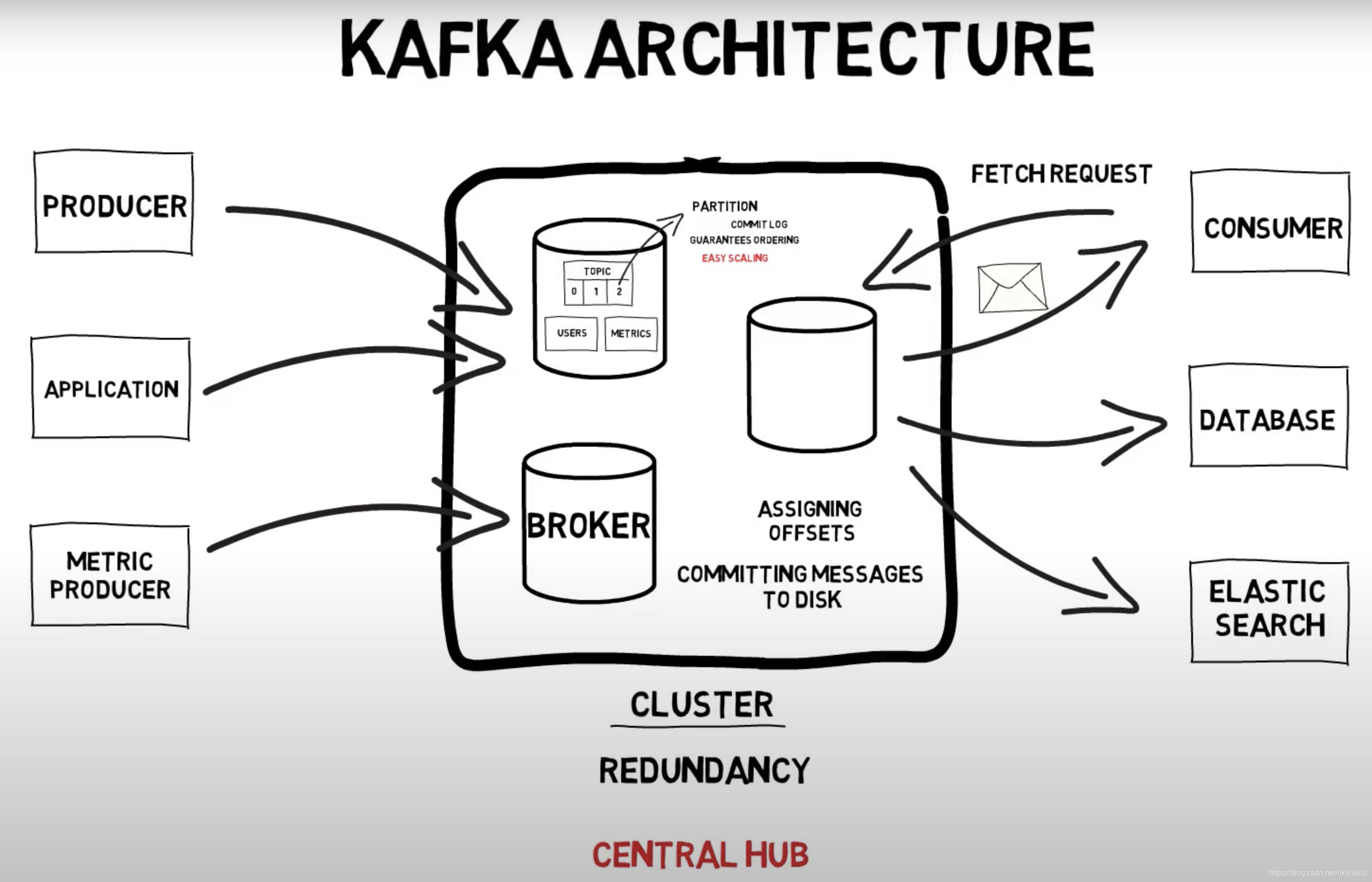
Kafka小结
- Kafka是一个分布式流处理平台。
- Kafka可以通过多个服务器组成的集群对单个数据流的数据进行分区。
- 每个分区都被跨服务器地复制,以实现对该数据的容错性。
- Kafka的核心是一个分布式提交日志。
- Kafka的关键的功能包括:
- 发布和订阅流
- 以容错、持久的方式存储事件流
- 在事件发生的时候就处理事件流
- 可使用Kafka Connect将数据库或其他系统成为Kafka的数据流的源。
- 不可变数据流,append-only。
- 记录是持久化的,日志保留在文件系统上。如果磁盘空间足够大,可以一直保存,否则需要设置保存的策略。
- 生产者总是将新事件写到分区的末尾,消费者通常按顺序处理事件,但也可以指定开始处理的偏移量(offset)
- 通过在读取记录时制定消费者组,可以对消费者实现负载均衡。消费者组是多个消费者的逻辑分组,确保每个记录仅由同一个消费者组中的单个消费者读取。
- Kafka的主题与记录的类别有关,比如主题A用于GPS实时定位数据,主题B用语车辆传感器的实时数据。
- 消息的有序性:因为默认只有在分区中的消息才是有序的,而一个主题的消息会被随机的分到多个分区上,也就是一个主题内的消息无法保证有序性。这在有些场景会导致问题。为了解决这个问题,可以利用message key,将相同message key的消息总是分发到一个分区中,而同一个分区中的消息是有序的,从而保证了业务逻辑上的消息有序性。
- 使用MirrorMaker跨Kafka集群复制数据,实现多Kafka集群的高可用。
Kafka最佳实践
最佳实践:
- 高吞吐量
- 低延迟
- 高可用
- 负载均衡
- 一致性,或业务逻辑有序性 // Kafka默认为分区内有序
- 消费且仅消费一次 (exactly once) // Kafka 默认为至少消费一次(at least once)
- 设置数据有效期
- 安全
说明:
- 将Kafka部署成高可用的Kafka cluster(3个Kafka broker),甚至考虑多集群的Kafka。
- 为每个应用配置一个消费者组,包含至少3个消费者。
- 将一个主题分成至少3个分区。
- 为消息编一个message key,按照message key将消息写入特定分区。
- 配置合适的数据保存策略。
- TLS传输加密,用Kafka user来作认证和鉴权
Kafka主要应用场景
- 消息处理 (和其他消息队列相比,Kafka的优势包括高吞吐量、低延迟、分区、复制、容错)
- 网站行为跟踪 (跟踪用户在网站上的实时行为,比如翻页/滑屏,搜索,查看详情、停留时间等)
- 指标 (从多个地方采集指标,汇总后展示)
- 日志归集(采集多个应用的标准输出)
- 流处理(处理流数据,比如物联网设备产生的源源不断的数据,并支持将多个流串联起来形成data pipeline)
- 事件溯源(Event Sourcing) - 按照事件发生时间顺序存储下来每个事件,可以回顾过去任何时刻的状态,也可查看当前状态
- 提交日志(Commit Log)- 可用来实现Change Data Capture模式
Kafka生态系统
- Kafka Encosystem
- Strimzi - http://strimzi.io/ - Apache Kafka Operator for Kubernetes and Openshift. Downloads and Helm Chart - https://github.com/strimzi/strimzi-kafka-operator/releases/latest
- Spring Cloud Stream - a framework for building event-driven microservices, Spring Cloud Data Flow - a cloud-native orchestration service for Spring Cloud Stream applications
Spring for Kafka
Spring for Kafka
- spring-kafka
- Spring for Kafka
- Spring for Kafka Reference
- How to Work with Apache Kafka in Your Spring Boot Application

















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









