






 本文深入探讨了中文分词技术,包括PaddleNLP的LAC模型和Jieba分词工具的使用,对比分析了两者的分词效果,并通过实际案例展示了如何计算信息熵。同时,文章详细解释了最大前向匹配算法及其复杂度,以及介绍了基于词表和统计模型的多种分词算法。
本文深入探讨了中文分词技术,包括PaddleNLP的LAC模型和Jieba分词工具的使用,对比分析了两者的分词效果,并通过实际案例展示了如何计算信息熵。同时,文章详细解释了最大前向匹配算法及其复杂度,以及介绍了基于词表和统计模型的多种分词算法。
2月25日第一次作业
作业奖励: 3月2日中午12点之前完成,会从中挑选10位回答优秀的同学获得飞桨定制数据线+本
作业1-1
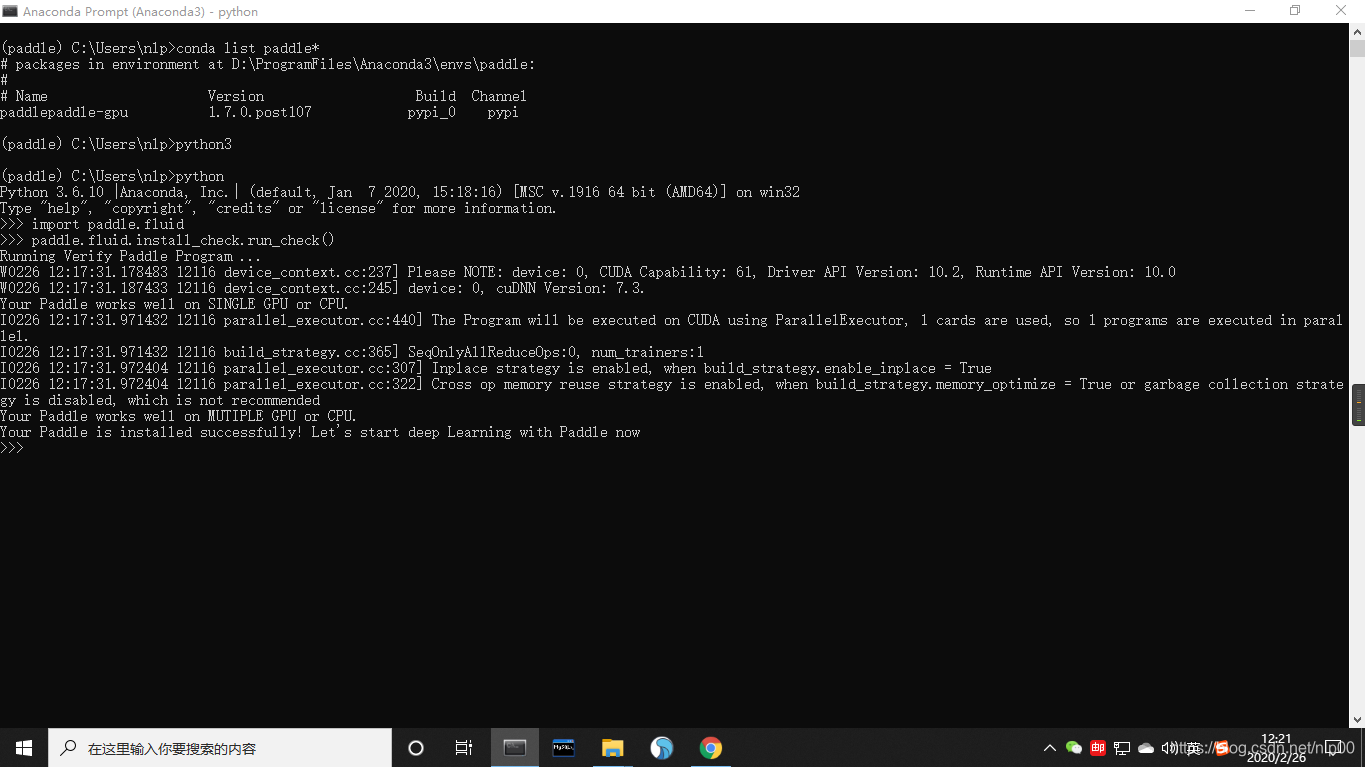
(1)下载飞桨本地并安装成功,将截图发给班主任
(2)学习使用PaddleNLP下面的LAC模型或Jieba分词
LAC模型地址:https://github.com/PaddlePaddle/models/tree/release/1.6/PaddleNLP/lexical_analysis
Jieba模型:https://github.com/fxsjy/jieba(3)对人民日报语料完成切词,并通过统计每个词出现的概率,计算信息熵
语料地址:https://github.com/fangj/rmrb/tree/master/example/1946%E5%B9%B405%E6%9C%88作业1-2
(1)思考一下,假设输入一个词表里面含有N个词,输入一个长度为M的句子,那么最大前向匹配的计算复杂度是多少?
(2)给定一个句子,如何计算里面有多少种分词候选,你能给出代码实现吗?
(3)除了最大前向匹配和N-gram算法,你还知道其他分词算法吗,请给出一段小描述。
作业1-1
(1) 下载飞桨本地并安装成功,将截图发给班主任
(2) 学习使用PaddleNLP下面的LAC模型或Jieba分词
- LAC是一个联合的词法分析模型,整体性地完成中文分词、词性标注、专名识别任务。LAC既可以认为是Lexical Analysis of Chinese的首字母缩写,也可以认为是LAC Analyzes Chinese的递归缩写。
- LAC基于一个堆叠的双向GRU结构,在长文本上准确复刻了百度AI开放平台上的词法分析算法。效果方面,分词、词性、专名识别的整体准确率95.5%;单独评估专名识别任务,F值87.1%(准确90.3,召回85.4%),总体略优于开放平台版本。在效果优化的基础上,LAC的模型简洁高效,内存开销不到100M,而速度则比百度AI开放平台提高了57%。
Paddlepaddle分词:
import paddlehub as hub
lac = hub.Module(name='lac')
text = ["南京市长江大桥",
"我在参加百度自然语言处理集训营,",
"Paddlepaddle很好用,也很强大!",
"“百度”二字,来自于八百年前南宋词人辛弃疾的一句词:众里寻他千百度。这句话描述了词人对理想的执着追求。"]
inputs = {"text": text}
results = lac.lexical_analysis(data=inputs)
print("Paddle分词结果:")
for result in results:
print(result['word'])
# print(result['tag']) # 词性标注
Jieba分词:
import jieba
print("Jieba分词结果:")
for txt in text:
jieba_result = jieba.lcut(txt)
print(jieba_result)
输出:
Paddle分词结果:
['南京市', '长江大桥']
['我', '在', '参加', '百度', '自然语言处理集训营', ',']
['Paddlepaddle', '很好', '用', ',', '也', '很', '强大', '!']
['“', '百度', '”', '二', '字', ',', '来自', '于', '八百年前', '南宋', '词人', '辛弃疾', '的', '一句', '词', ':', '众里寻他千百度', '。', '这句话', '描述', '了', '词人', '对', '理想', '的', '执着', '追求', '。']
Jieba分词结果:
['南京市', '长江大桥']
['我', '在', '参加', '百度', '自然语言', '处理', '集训营', ',']
['Paddlepaddle', '很', '好', '用', ',', '也', '很', '强大', '!']
['“', '百度', '”', '二字', ',', '来自', '于', '八百年', '前', '南宋', '词人', '辛弃疾', '的', '一句', '词', ':', '众里', '寻', '他', '千百度', '。', '这句', '话', '描述', '了', '词人', '对', '理想', '的', '执着', '追求', '。']
结果分析:
Paddlepaddle的分词粒度大于Jieba,可以推测Paddle的预设词汇表比Jieba更大。
(3) 对人民日报语料完成切词,并通过统计每个词出现的概率,计算信息熵
import paddlehub
import os
import re
import numpy as np
import collections
# 加载paddle的lac模型
lac = paddlehub.Module('lac')
path = '1946年05月'
# 遍历文件夹
files_path = []
for root, dirs, files in os.walk(path):
for file in files:
files_path.append(os.path.join(root,file))
# 读取文件内容
passages = []
for path in files_path:
with open(path, encoding='utf-8') as f:
one_passage = f.read()
passages.append(one_passage)
inputs = {"text": passages}
passages = lac.lexical_analysis(data=inputs)
passages_cut = [p['word'] for p in passages]
# 处理特殊字符,替换为空格
text_cleaned = []
for p in passages_cut:
for string in p:
strings = re.split(r'[a-zA-Z0-9’!"#$%&\'()*+,-./:;<=>?@,。:()?@★、…【】《》?“”‘’!^_`{|}~\s]+', string)
text_cleaned.extend(strings)
# 删除所有空字符
text_cleaned = [t for t in text_cleaned if t != '']
print(text_cleaned)
# 三种方法统计词频
# ①直接使用dict【不导包】
# ②使用collections.defaultdict(int)
# ③使用collections.Counter【最简洁】
# # ①直接使用dict
# frequency = {}
# for word in text_cleaned:
# if word not in frequency:
# frequency[word] = 1
# else:
# frequency[word] += 1
# # ②使用defaultdict
# frequency = collections.defaultdict(int)
# for word in text_cleaned:
# frequency[word] += 1
# ③使用Counter
frequency = collections.Counter(text_cleaned)
# 按词频排序
frequency = sorted(frequency.items(), key=lambda x: x[1], reverse=True)
# 总词数
word_count = 0
for item in frequency:
word_count += item[1]
# 求信息熵
entropy = 0
for item in frequency:
p = int(item[1]) / word_count
entropy += -p*np.log2(p)
print("信息熵=", entropy)
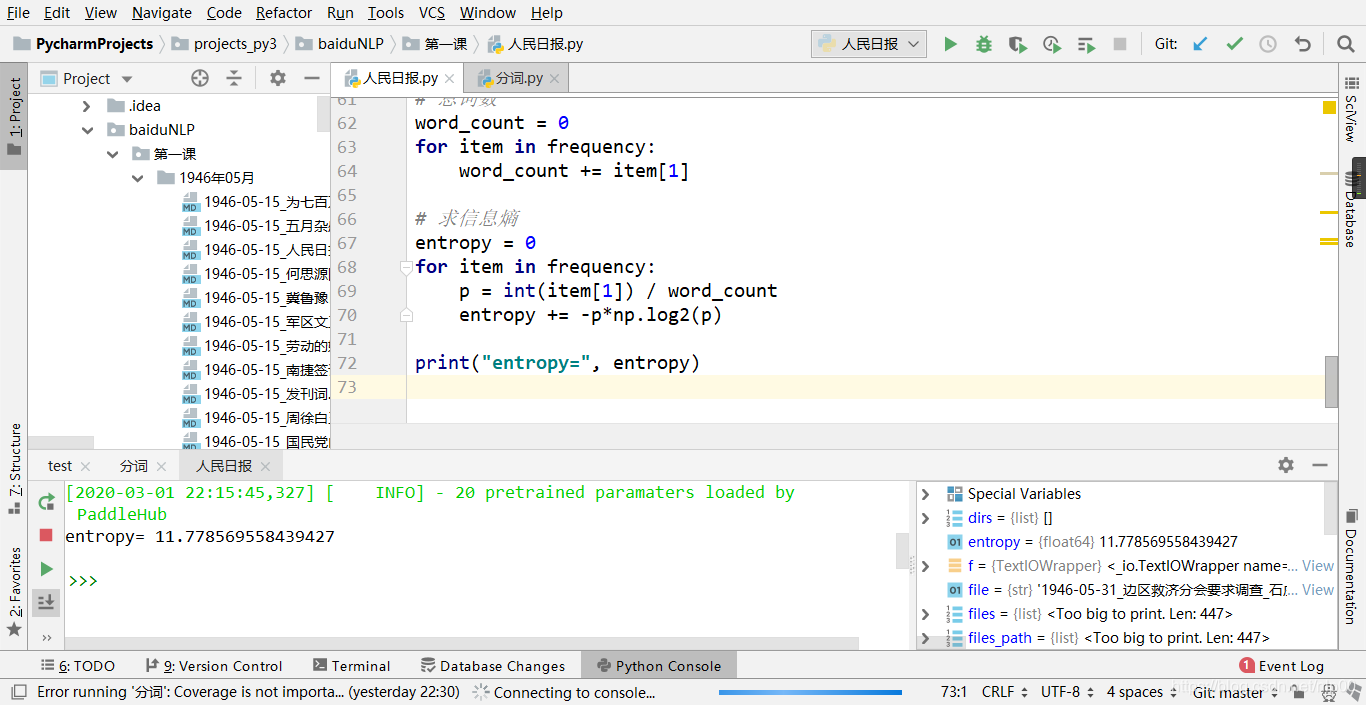
结果
entropy= 11.778569558439427
截图如下
作业1-2
(1)思考一下,假设输入一个词表里面含有N个词,输入一个长度为M的句子,那么最大前向匹配的计算复杂度是多少?
答: O(M * N)
理由: 最大前向匹配最坏的情况是:句子分词结果为单个字,并且每个字都需要遍历词表全部。所以最后的匹配结果次数为N * (M + M-1 + … + 2 + 1),所以时间复杂度为O(N * M^2)
正向最大匹配算法:首先需要给定一个最大的词条长度,假设定义最大词条长度(滑动窗口的长度)为max_num=3,我们首先取出句子的前3个字符,看前3个字符是否存在于词库中,如果存在,则返回第一个分词,滑动窗口向后滑动3个位置;如果不存在,我们把滑动窗口从右向左缩小1,判断前两个字符是否存在于词库,如果存在,则返回这个分词,滑动窗口向后滑动2,不存在则继续缩小滑动窗口…直至将整个句子遍历完,就得到了最后的分词结果。
摘自:https://zhuanlan.zhihu.com/p/65190736
(2)给定一个句子,如何计算里面有多少种分词候选,你能给出代码实现吗?
(3)除了最大前向匹配和N-gram算法,你还知道其他分词算法吗,请给出一段小描述。
-
1.基于词表
-
a) 逆向最大匹配法(BMM):类比前向匹配法,顺序相反
-
b) 双向最大匹配法:正向与逆向结合
-
-
2.基于统计模型
-
a)隐马尔可夫模型:HMM模型认为在解决序列标注问题时存在两种序列,一种是观测序列,即人们显性观察到的句子,而序列标签是隐状态序列,即观测序列为X,隐状态序列是Y,因果关系为Y->X。因此要得到标注结果Y,必须对X的概率、Y的概率、P(X|Y)进行计算,即建立P(X,Y)的概率分布模型。
-
b)CRF分词算法:CRF可以看作一个无向图模型,对于给定的标注序列Y和观测序列X,对条件概率P(Y|X)进行定义,而不是对联合概率建模。CRF可以说是目前最常用的分词、词性标注和实体识别算法,它对未登陆词有很好的识别能力,但开销较大
-
引用:
- https://blog.csdn.net/ld326/article/details/81364405
- Jiao, Zhenyu and Sun, Shuqi and Sun, Ke. Chinese Lexical Analysis with Deep Bi-GRU-CRF Network. arXiv: https://arxiv.org/abs/1807.01882
- https://github.com/PaddlePaddle/models/tree/release/1.6/PaddleNLP/lexical_analysis


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









