









 本文通过Scala演示了如何实现基于Socket的分布式计算,包括服务器端(Executor)和客户端(Driver)的创建,以及如何封装计算逻辑并进行对象序列化传输。通过创建Task和SubTask类,实现了数据和计算任务的分配,从而展示了分布式计算的基本流程。
本文通过Scala演示了如何实现基于Socket的分布式计算,包括服务器端(Executor)和客户端(Driver)的创建,以及如何封装计算逻辑并进行对象序列化传输。通过创建Task和SubTask类,实现了数据和计算任务的分配,从而展示了分布式计算的基本流程。
- 在学习Spark, 深入分布式计算之前, 我们有必要先体会一下分布式计算的特性和简单原理;
- 那么我们基于Java去理解, 实现分布式的前提是什么呢? 当然是各个主机之间的通信, 即
Socket网络通信, 由于Scala引入了大量的Java类库, 自然的也就类似于Java实现Socket通信了;
第一步, Scala实现服务器端 Excutor.scala
package simpledistributeddemo
import java.io.{InputStream, ObjectInput, ObjectInputStream}
import java.net.{ServerSocket, Socket}
// excutor 作为服务器, 接收数据, 接收计算任务
object Excutor {
def main(args: Array[String]): Unit = {
//1. 新建一个xx端口的服务器
1.1 建立999端口的socket对象
val socket:ServerSocket = new ServerSocket(999)
1.2 建立服务器对象
val server:Socket = socket.accpet()
println("服务器已启动, 准备读取数据")
//2. 获取到客户端建立的输入流, 接收数据;
val in:InputStream = server.getInputStream
2.1读取流中的数据并输出
res:Int = in.read()
println("服务器读取到数据 ${res}")
//3. 关闭流
in.close()
}
}
第二步, Scala实现客户端 Driver.scala
package simpledistributeddemo
import java.io.{ObjectOutputStream, OutputStream}
import java.net.Socket
//客户端, 给服务器发送数据, 发送计算任务
object Driver {
def main(args: Array[String]): Unit = {
//1. 新建Socket对象, 这个socket 的端口为: xx端口
val client:Socket = new Socket("localhost", 9999)
//2. 建立输出流, 发送数据
val out:OutputStream = client.getOutputStream
out.write(5)
//3. 刷写到内存, 关闭资源
println("数据已发送完毕")
out.flush()
out.close()
client.close()
}
}
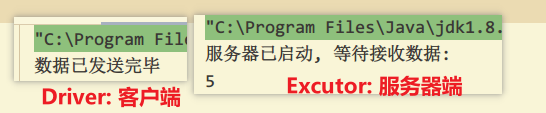
完成上面两步后, 先启动服务器端 Excutor.sala, 此时服务器端阻塞, 等待获取到客户端的数据, 然后再启动Driver.scala, 客户端发送数据后, 双方结束运行, 结果如下:
第三步: 客户端向服务器发送计算任务, Task.scala
- 上面的仅仅是发送了数据, 接受到数据的过程, 要想达到服务器接收计算任务, 我们需要封装一个计算逻辑, 由客户端提交到服务器端执行;
3.1 建立一个Task类, 封装数据和计算逻辑
class Task{
//计算需要的数据
val data: List[Int] = List(2,4,6,8,9)
//计算逻辑
//val logic = (num: Int) => {num * 2} //匿名函数,
val logic: (Int => Int) = _ * 2 //函数的至简原则, 对上面的函数进行化简
//执行计算逻辑
def compute(): List[Int] = {
data.map(logic)
}
}
- 不了解函数至简原则? 看我
3.2 进一步丰富客户端Driver.scala, 通过客户端类, 我们再给服务器端Excutor.scala发送一个计算任务
package simpledistributeddemo
import java.io.{ObjectOutputStream, OutputStream}
import java.net.Socket
//客户端, 给服务器发送数据, 发送计算任务
object Driver {
def main(args: Array[String]): Unit = {
//1. 新建Socket对象, 这个socket 的端口为: xx端口
val client:Socket = new Socket("localhost", 9999)
//2. 建立输出流, 发送数据
val out:OutputStream = client.getOutputStream
out.write(5)
//>>>>>>>>>>>>>///2.1 对输入流进一步包装, 使它能够传输对象
val objOut:ObjectOutputStream = new ObjectOutputStream(out)
objOut.writeObject(new Task()) //把计算对象传输过去
//3. 刷写到内存, 关闭资源
println("数据已发送完毕")
//>>>>>>>>>>>>>>>3.1刷写, 关闭对象输出流, 注意ObjOut要在out之前关闭噢!
objOut.flush()
out.flush()
objOut.close()
out.close()
client.close()
}
}
3.2 进一步丰富服务器端Excutor.scala, 通过接受客户端传过来的计算任务, 执行计算, 输出计算结果
package simpledistributeddemo
import java.io.{InputStream, ObjectInput, ObjectInputStream}
import java.net.{ServerSocket, Socket}
// excutor 作为服务器, 接收数据, 接收计算任务
object Excutor {
def main(args: Array[String]): Unit = {
//1. 新建一个xx端口的服务器
1.1 建立999端口的socket对象
val socket:ServerSocket = new ServerSocket(999)
1.2 建立服务器对象
val server:Socket = socket.accpet()
println("服务器已启动, 准备读取数据")
//2. 获取到客户端建立的输入流, 接收数据;
val in:InputStream = server.getInputStream
2.1读取流中的数据并输出
res:Int = in.read()
println("服务器读取到数据 ${res}")
//>>>>>>>>>>>/2.2 用对象输入流包装输入流, 读取得到传输过来的计算任务对象
///注意, 由于泛型擦除, 我们有必要对从对象流取到的对象进行强制类型转换
/// scala中的强制类型转换是 xx.asInstanceOf[]
var objIn:ObjectInputStream = new ObjectInputStream(in)
var task = objIn.readObject().asInstanceOf[Task] //强制类型转换
//>>>>>>>>>>>///2.3 执行计算任务
var result = task.compute()
println("服务器端的计算结果为: " + result)
//3. 关闭流
in.close()
objIn.close()
//关闭socket通信
socket.close()
server.close()
}
}
- 执行结果如下:

- 从这里我们可以体会到, java通信时传送的都是字节流或字符流, 要使对象能够进行网络传输, 就要对其进行序列化, 转换为字节流进行传输, 在达到目的地后再进行反序列化转为原来的对象继续使用; 序列化文章参考: 点我
- 解决方法, 使被传输的对象继承
Serializable类, 即可, 在Scala中, 我们叫混入特质 
- 修正后的执行结果:

第四步: 实现分布式计算
- 实现方法: 要想实现分布式计算, 封装计算逻辑的类需要有多个, 上面我们提到的Task封装了计算数据和计算逻辑, 但是因为不同任务的计算数据是不同的, 所以我们在这里改为:
- Task 类封装了计算数据和计算逻辑, 作用是供不同的分布式计算类提取不同的数据
- 新建一个类, 代表分布式的计算任务SubTask, 封装了计算方法, 引入了Task 的数据变量和计算逻辑变量, 但是把该对象置空, 比如
val x: String = _, - 为什么要置空呢? 还不是为了在new一个SubTask时, 我们可以手动的指定该subtask的计算数据, 和计算逻辑, 使得我们能够新建多个不同计算数据的计算任务
4.1 分布式计算类的
实体类, 提供计算数据和计算逻辑, Task.scala
package simpledistributeddemo
class Task extends Serializable{
//计算需要的数据
val data: List[Int] = List(2,4,6,8,9)
//计算逻辑
//val logic = (num: Int) => {num * 2} //匿名函数,
val logic: (Int => Int) = _ * 2 //函数的至简原则, 对上面的函数进行化简
}
4.2 分布式计算类, subTask, 调用实体类Task.scala 的计算数据和计算逻辑, 实现计算方法
package simpledistributeddemo
class SubTask extends Serializable{
var data:List[Int] = _
var logic: Int => Int = _
def compute() = {
data.map(logic)
}
}
4.3 服务器端, 执行计算任务1
package simpledistributeddemo
import java.io.{InputStream, ObjectInputStream}
import java.net.{ServerSocket, Socket}
// excutor 作为服务器, 接收数据, 接收计算任务
object Excutor {
def main(args: Array[String]): Unit = {
//1. 新建一个xx端口的服务器
1.1 建立999端口的socket对象
val socket:ServerSocket = new ServerSocket(9999)
1.2 建立服务器对象
val server:Socket = socket.accept()
//2. 获取到客户端建立的输入流, 接收数据;
val in:InputStream = server.getInputStream
println("服务器已启动, 准备读取数据")
2.1读取流中的数据并输出
// val res:Int = in.read()
// println(s"服务器读取到数据 ${res}")
//>>>>>>>>>>>/2.2 用对象输入流包装输入流, 读取得到传输过来的计算任务对象
///注意, 由于泛型擦除, 我们有必要对从对象流取到的对象进行强制类型转换
/// scala中的强制类型转换是 xx.asInstanceOf()
var objIn:ObjectInputStream = new ObjectInputStream(in)
var subTask = objIn.readObject().asInstanceOf[SubTask]//强制类型转换
//>>>>>>>>>>>///2.3 执行计算任务
var result = subTask.compute()
println("服务器端的计算结果为: " + result)
//3. 关闭流
//in.close()
objIn.close()
//关闭socket通信
socket.close()
server.close()
}
}
4.4 服务器端, 执行计算任务2
package simpledistributeddemo
import java.io.{InputStream, ObjectInputStream}
import java.net.{ServerSocket, Socket}
// excutor 作为服务器, 接收数据, 接收计算任务
object Excutor1 {
def main(args: Array[String]): Unit = {
//1. 新建一个xx端口的服务器
1.1 建立999端口的socket对象
val socket:ServerSocket = new ServerSocket(8888)
1.2 建立服务器对象
val server:Socket = socket.accept()
//2. 获取到客户端建立的输入流, 接收数据;
val in:InputStream = server.getInputStream
println("服务器已启动, 准备读取数据")
2.1读取流中的数据并输出
// val res:Int = in.read()
// println(s"服务器读取到数据 ${res}")
//>>>>>>>>>>>/2.2 用对象输入流包装输入流, 读取得到传输过来的计算任务对象
///注意, 由于泛型擦除, 我们有必要对从对象流取到的对象进行强制类型转换
/// scala中的强制类型转换是 xx.asInstanceOf()
var objIn:ObjectInputStream = new ObjectInputStream(in)
var subTask = objIn.readObject().asInstanceOf[SubTask]//强制类型转换
//>>>>>>>>>>>///2.3 执行计算任务
var result = subTask.compute()
println("服务器端的计算结果为: " + result)
//3. 关闭流
//in.close()
objIn.close()
//关闭socket通信
socket.close()
server.close()
}
}
4.5 客户端, 给服务端发送计算数据, 实现计算方法, 向服务器端输出计算对象
package simpledistributeddemo
import java.io.{ObjectOutputStream, OutputStream}
import java.net.Socket
//客户端, 给服务器发送数据, 发送计算任务
object Driver {
def main(args: Array[String]): Unit = {
//1. 新建Socket对象, 这个socket 的端口为: xx端口
val client:Socket = new Socket("localhost", 9999)
val client1:Socket = new Socket("localhost", 8888)
val task = new Task() //此时的task是专门的数据分配对象
//2. 建立输出流, 发送数据
val out:OutputStream = client.getOutputStream
///2.2 子计算任务1
// >>>>>>>>>>>>>///2.1 对输入流进一步包装, 使它能够传输对象
val objOut:ObjectOutputStream = new ObjectOutputStream(out)
val subTask = new SubTask()
// 给子计算任务分配数据和计算逻辑
subTask.logic = task.logic
subTask.data = task.data.take(task.data.length / 2)
objOut.writeObject(subTask) //把子计算对象传输过去
objOut.flush()
out.flush()
out.close()
objOut.close()
client.close()
///2.2 子计算任务2
2.2.1 client1的输出流
val out1:OutputStream = client1.getOutputStream
val objOut1:ObjectOutputStream = new ObjectOutputStream(out1)
val subTask1 = new SubTask()
// 给子计算任务分配数据和计算逻辑
subTask1.logic = task.logic
subTask1.data = task.data.takeRight(task.data.length / 2)
objOut1.writeObject(subTask1) //把子计算对象传输过去
//3. 刷写到内存, 关闭资源
println("数据已发送完毕")
//>>>>>>>>>>>>>>>3.1刷写, 关闭对象输出流, 注意ObjOut要在out之前关闭噢!
objOut1.flush()
objOut1.close()
out1.flush()
out1.close()
client1.close()
}
}
- 至此, 一个简单的分布式计算程序算是完成了, 理解本文 , 对于Spark的分布式计算原理会更进一步;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









