







day01
b站:https://space.bilibili.com/1567748478/channel/seriesdetail?sid=358497
教材:https://zh-v2.d2l.ai/chapter_preface/index.html#sec-code
代码注解:https://blog.csdn.net/shakalakaphd/category_10318255_2.html
03 安装
我没有按照他的来 我使用的是anaconda
1)anaconda prompt
2) cd 到下载好的jupyter记事本位置
3)jupyter notebook
即可
04 数据操作+数据预处理
(沐神没告诉我在jupyter记事本的位置…尬住
数据操作:notebooks/pytorch/chapter_preliminaries/ndarray.ipynb
数据预处理:notebooks/pytorch/chapter_preliminaries/pandas.ipynb
数据预处理
读取数据集
下载torch很慢
→ pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch

我保存在了./data1/house_tiny.csv
import os
os.makedirs(os.path.join('.', 'data1'), exist_ok=True)
data_file = os.path.join('.', 'data1', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每行表示一个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
os.makedirs 创建目录
os.path.join 路径拼接函数


处理缺失值
注意,“NaN”项代表缺失值。 [为了处理缺失的数据,典型的方法包括插值法和删除法,] 其中插值法用一个替代值弥补缺失值,而删除法则直接忽略缺失值。 在(这里,我们将考虑插值法)。
通过位置索引iloc,我们将data分成inputs和outputs, 其中前者为data的前两列,而后者为data的最后一列。 对于inputs中缺少的数值,我们用同一列的均值替换“NaN”项。
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean())
print(inputs)
fillna()会填充nan数据,返回填充后的结果。
mean()函数功能:求取均值
这里运行的时候报了个警告
FutureWarning: Dropping of nuisance columns in DataFrame reductions (with ‘numeric_only=None’) is deprecated; in a future version this will raise TypeError. Select only valid columns before calling the reduction.
inputs = inputs.fillna(inputs.mean())
应该是因为里面有非数值的元素

[对于inputs中的类别值或离散值,我们将“NaN”视为一个类别。] 由于“巷子类型”(“Alley”)列只接受两种类型的类别值“Pave”和“NaN”, pandas可以自动将此列转换为两列“Alley_Pave”和“Alley_nan”。 巷子类型为“Pave”的行会将“Alley_Pave”的值设置为1,“Alley_nan”的值设置为0。 缺少巷子类型的行会将“Alley_Pave”和“Alley_nan”分别设置为0和1。
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)
特征提取之pd.get_dummies()
cr:https://www.jianshu.com/p/5f8782bf15b1
- pandas提供对one-hot编码的函数是:pd.get_dummies()
one-hot的基本思想:将离散型特征的每一种取值都看成一种状态,若你的这一特征中有N个不相同的取值,那么我们就可以将该特征抽象成N种不同的状态,one-hot编码保证了每一个取值只会使得一种状态处于“激活态”,也就是说这N种状态中只有一个状态位值为1,其他状态位都是0。
作者:轰鸣龙
链接:https://www.jianshu.com/p/5f8782bf15b1
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。



转换为张量模式
[现在inputs和outputs中的所有条目都是数值类型,它们可以转换为张量格式。] 当数据采用张量格式后,可以通过在 :numref:sec_ndarray中引入的那些张量函数来进一步操作。
import torch
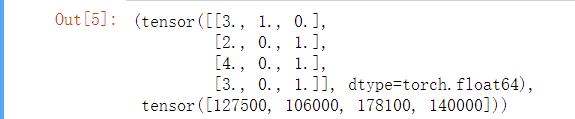
X, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
X, y
作业
data = pd.read_csv(data_file)
nan_numer = data.isnull().sum(axis=0)

day02
%matplotlib inline
在pycharm里报错
=》注释掉,在末尾加上
plt.show()

day03
3. 线性神经网络
3.1 线性回归
回归(regression)是能为一个或多个自变量与因变量之间关系建模的一类方法。 在自然科学和社会科学领域,回归经常用来表示输入和输出之间的关系。
3.1.1 线性回归的基本元素
线性回归基于几个简单的假设: 首先,假设自变量 x 和因变量 y 之间的关系是线性的, 即 y 可以表示为 x 中元素的加权和,这里通常允许包含观测值的一些噪声; 其次,我们假设任何噪声都比较正常,如噪声遵循正态分布。
为了解释线性回归,我们举一个实际的例子: 我们希望根据房屋的面积(平方英尺)和房龄(年)来估算房屋价格(美元)。 为了开发一个能预测房价的模型,我们需要收集一个真实的数据集。 这个数据集包括了房屋的销售价格、面积和房龄。 在机器学习的术语中,该数据集称为训练数据集(training data set) 或训练集(training set)。 每行数据(比如一次房屋交易相对应的数据)称为样本(sample), 也可以称为数据点(data point)或数据样本(data instance)。 我们把试图预测的目标(比如预测房屋价格)称为标签(label)或目标(target)。 预测所依据的自变量(面积和房龄)称为特征(feature)或协变量(covariate)。
3.1.1.1 线性模型


3.1.1.2 损失函数

3.1.1.3 解析解
3.1.1.4 随机梯度下降

3.2 线性回归的从零开始实现
代码注解:https://blog.csdn.net/ShakalakaPHD/article/details/108134227
%matplotlib inline
import random
import torch
from d2l import torch as d2l

构造数据集
def synthetic_data(w, b, num_examples): #@save
"""生成y=Xw+b+噪声"""
X = torch.normal(0, 1, (num_examples, len(w))) #num_example是n个样本 均值为0 方差为1
y = torch.matmul(X, w) + b #torch.matmul是tensor的乘法,输入可以是高维的。
y += torch.normal(0, 0.01, y.shape)#torch.shape 和 torch.size() 输出结果相同。
return X, y.reshape((-1, 1))#torch.reshape用来改变tensor的shape。
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)

reshape((-1,1)) 中-1=n
cr:https://blog.csdn.net/weixin_42599499/article/details/105896894

读取数据集

def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
# 这些样本是随机读取的,没有特定的顺序
random.shuffle(indices)#打乱indices的顺序
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]

batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
break
初始化模型参数















 754
754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









