







RDBMS在设计和实现商业应用方面扮演了一个不可或缺的角色,经常会被拿来作为前端应用服务器的持久化数据服务。这种结构非常适合有限的数量,一旦数据急剧增长,这种方案就显得力不从心了。
1. RDBMS
RDBMS常见的解决方案,包括应对数据压力的措施:
1. 事务:提供了原子性的跨表更新数据的特性,可以让修改同时可见或者不可见
2. 参照完整性负责约束不同的表结构之间的关系,利用SQL语言能够写出任意复杂 的查询语句
3. 增加用于并行读取的从服务器,将读写分离
4. 利用memcached等缓存技术
5. 辅助索引
6. 数据分区分库
虽然这些方案能在一定程度上缓解数据剧增带来的压力,但是伴随的问题也是不可忍受的。缓存的使用可以提供读的性能,但是这种方案无法保证数据一致性;辅助索引随着数据量的增大,索引量也大到了足以让数据库的性能直线下降。分区分表往往会带来运维的压力。正是伴随着这一系列的问题NoSQL解决方案问世。
2.HBase简介
Hbase是bigtable的开源山寨版本。是建立的hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。
它介于nosql和RDBMS之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。主要用来存储非结构化和半结构化的松散数据。与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
在介绍HBase之前,先比较下典型的RDBMS和其他非关系型数据库底层存储结构的不同。B树和B+树被广泛用于关系型存储引擎,而LSM树在某种程度上构成了BigTable的底层存储结构。
B+树的一些特性使其能通过主键对记录进行高效的插入、查找及删除。它表示为一个动态的、多层并有上下界的索引。除此之外、B+树能够提供高效的范围扫描功能,这主要是因为它的叶节点相互连接并且按主键有序、扫描时避免了耗时的遍历树操作。
LSM树对于插入数据首先被存储在日志文件中,这些文件内的数据完全有序的。当有日志文件被修改时,对应的更新会被优先保存在内存中来加速查询。当内存空间被逐渐占满时,LSM会把有序的记录写到磁盘中。
B+树的性能瓶颈在于磁盘的寻道时间,而LSM的限制在于磁盘的转速。
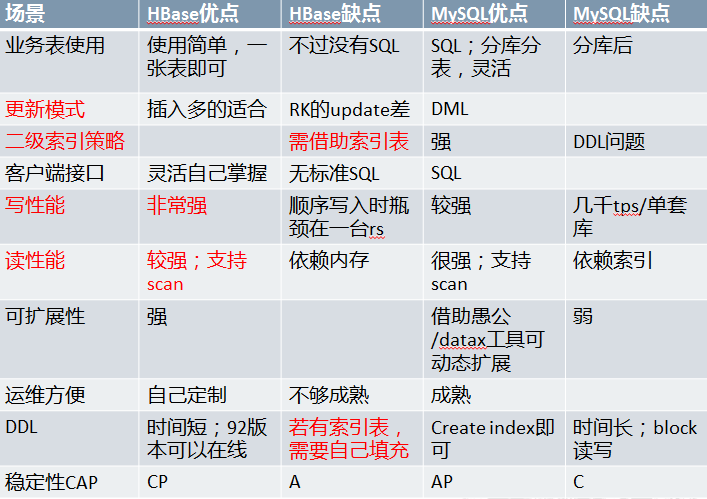
上图简单对比了Hbase和mysql,CAP原本是一个猜想,2000年PODC大会的时候大牛Brewer提出的,他认为在设计一个大规模可扩放的网络服务时候会遇到三个特性:一致性(consistency)、可用性(Availability)、分区容错(partition-tolerance)都需要的情景,然而这是不可能都实现的。之后在2003年的时候,Mit的Gilbert和Lynch就正式的证明了这三个特征确实是不可以兼得的。
3.HBase详述
3.1 存储结构图
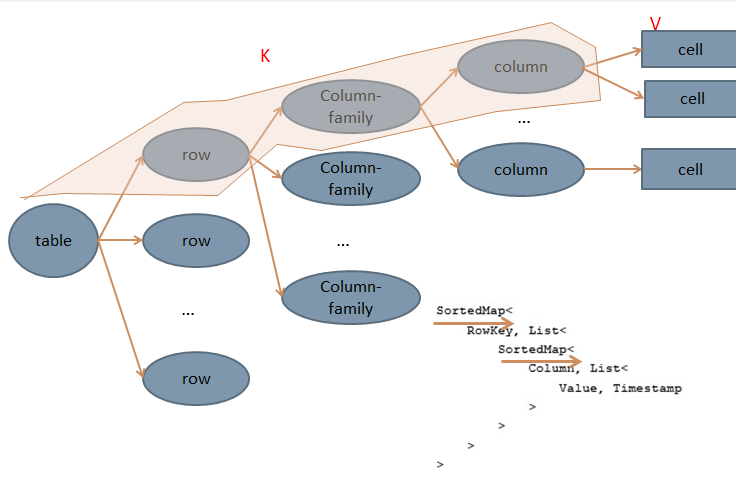
Row key:用来检索记录的主键。访问hbase table中的行,只有三种方式:
1 .通过单个row key访问
2 .通过row key的range
3 .全表扫描
列族:hbase表中的每个列,都归属与某个列族。列族是表的Schema的一部分(而列不是),必须在使用表之前定义。
时间戳:HBase中通过row和columns确定的为一个存贮单元称为cell,每个 cell都保存着同一份数据的多个版本,版本通过时 间戳来索引。
Cell:由{row key, column(=<family> +<label>), version} 唯一确定的单元。cell中的数据是没有类型的,全部是字节码形式存 贮。
HBase专注于byte[]的操作。对此,方案在设计时避开了“SQL解析”和“在各种数据类型与byte[]之间进行转化”的棘手问题,而是使用了一组可以描述查询的Query API。
3.2 架构
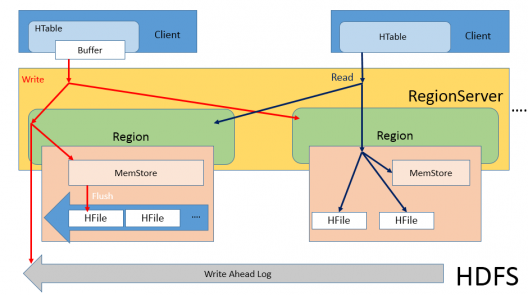
Client:Client 负责寻找提供需求数据的ReginServer。Client 将首先与Master 通信,找到ROOT 区域。这个操作是Client 和Master 之间仅有的通信操作。一旦ROOT 区域被找到以后,Client 就可以通过扫描ROOT 区域找到相应的META 区域去定位实际提供数据的ReginServer。
Master:Master 负责给RegionServer 分配区域,并且负责对集群环境中的ReginServer 进行负载均衡,Master 还负责监控集群环境中的ReginServer 的运行状况,如果某一台ReginServer down机,BaseMaster 将会把不可用的ReginServer 来提供服务的Log 和表进行重新分配转交给其他ReginServer 来提供,BaseMaster 还负责对数据和表进行管理,处理表结构和表中数据的变更,因为在META 系统表中存储了所有的相关表信息。并且Master 实现了ZooKeeper 的Watcher 接口可以和zookeeper 集群交互。
在HBase 中创建的一张表可以分布在多个region, 也就说一张表可以被拆分成多块 ,每一块称我们呼为一个region。每个region 会保存一个表里面某段连续的数据,用户创建的那个大表中的每个region 块是由region 服务器提供维护,访问region 块是要通过region 服务器,而一个region 块对应一个region 服务器,一张完整的表可以保存在多个region 上。Region Server 与Region 的对应关系是一对多的关系。每一个Region 在物理上会被分为三个部分:MemStore(缓存)、WAL(日志)、HFile(持久层)。
3.3 读
假设你需要通过某个特定的RowKey查询一行记录,首先Client端会连接Zookeeper Qurom,通过Zookeeper,Client能获知哪个Server管理-ROOT- Region。接着Client访问管理-ROOT-的Server,进而获知哪个Server管理.META.表。这两个信息Client只会获取一次并缓存起来。在后续的操作中Client会直接访问管理.META.表的Server,并获取Region分布的信息。一旦Client获取了这一行的位置信息,比如这一行属于哪个Region,Client将会缓存这个信息并直接访问HRegionServer。久而久之Client缓存的信息渐渐增多,即使不访问.META.表也能知道去访问哪个HRegionServer。注意:当HBase启动的时候HMaster负责分配Region给HRegionServer,这其中当然也包括-ROOT-表和.META.表的Region。
接下来HRegionServer打开这个Region并创建一个HRegion对象。当HRegion打开以后,它给每个table的每个HColumnFamily创建一个Store实例。每个Store实例拥有一个或者多个StoreFile实例。StoreFile对HFile做了轻量级的包装。除了Store实例以外,每个HRegion还拥有一个MemStore实例和一个HLog实例。现在我们就可以看看这些实例是如何在一起工作的,遵循什么样的规则以及这些规则的例外。
3.4 写
Client发起了一个HTable.put(Put)请求给HRegionServer,HRegionServer会将请求匹配到某个具体的HRegion上面。紧接着的操作时决定是否写WAL log。是否写WAL log由Client传递的一个标志决定,你可以设置这个标志:Put.writeToWAL(boolean)。WAL log文件是一个标准的Hadoop SequenceFile(现在还在讨论是否应该把文件格式改成一个更适合HBase的格式)。在文件中存储了HLogKey,这些Keys包含了和实际数据对应的序列号,用途是当RegionServer崩溃以后能将WAL log中的数据同步到永久存储中去。做完这一步以后,Put数据会被保存到MemStore中,同时会检查MemStore是否已经满了,如果已经满了,则会触发一个Flush to Disk的请求。HRegionServer有一个独立的线程来处理Flush to Disk的请求,它负责将数据写成HFile文件并存到HDFS上。它也会存储最后写入的数据序列号,这样就可以知道哪些数据已经存入了永久存储的HDFS中。
3.5索引
目前HBase主要应用在结构化和半结构化的大数据存储上,其在插入和读取上都具有极高的性能表现,这与它的数据组织方式有着密切的关系,在逻辑上,HBase的表数据按RowKey进行字典排序, RowKey实际上是数据表的一级索引(Primary Index),由于HBase本身没有二级索引(Secondary Index)机制,基于索引检索数据只能单纯地依靠RowKey,为了能支持多条件查询,开发者需要将所有可能作为查询条件的字段一一拼接到RowKey中,这是HBase开发中极为常见的做法,但是无论怎样设计,单一RowKey固有的局限性决定了它不可能有效地支持多条件查询。通常来说,RowKey只能针对条件中含有其首字段的查询给予令人满意的性能支持,在查询其他字段时,表现就差强人意了,在极端情况下某些字段的查询性能可能会退化为全表扫描的水平,这是因为字段在RowKey中的地位是不等价的,它们在RowKey中的排位决定了它们被检索时的性能表现,排序越靠前的字段在查询中越具有优势,特别是首位字段具有特别的先发优势,如果查询中包含首位字段,检索时就可以通过首位字段的值确定RowKey的前缀部分,从而大幅度地收窄检索区间,如果不包含则只能在全体数据的RowKey上逐一查找,由此可以想见两者在性能上的差距。
受限于单一RowKey在复杂查询上的局限性,基于二级索引(Secondary Index)的解决方案成为最受关注的研究方向,并且开源社区已经在这方面已经取得了一定的成果,像ITHBase、IHBase以及华为的hindex项目,这些产品和框架都按照自己的方式实现了二级索引,各自具有不同的优势,同时也都有一定局限性,本文阐述的方案借鉴了它们的一些优点,在确保非侵入的前提下,以高性能为首要目标,通过建立二级多列索引实现了对复杂条件查询的支持,同时通过提供通用的查询API,以及完全基于配置的索引结构,完全封装了索引的创建和使用细节,使之成为一种通用的查询引擎。
3.6布隆过滤器
数据块索引提供了一个有效的方法,在访问一个特定的行时用来查找应该读取的HFile的数据块,但是它的效用是有限的。如果你要查找一个短行,只在整个数据块的起始行键上建立索引无法给你细粒度的索引信息。你要查找的行可能落在特定数据块上的行区间里, 但也不是肯定存放在那个数据块上。这有多种情况的可能,或者该行在表里不存在,或者存放在另一个HFile里,甚至在MemStore里。这些情况下,从硬盘读取数据块会带来IO开销,也会滥用数据块缓存。这会影响性能,尤其是当你面对一个巨大的数据集并且有很多并发读用户时。
布隆过滤器允许你对存储在每个数据块的数据做一个反向测试。当某行被请求时,先检查布隆过滤器看看该行是否不在这个数据块。一个行级布隆过滤器用ROW打开,列标识符级布隆过滤器用ROWCOL打开。行级布隆过滤器在数据块里检查特定行键是否不存在,列标识符级布隆过滤器检查行和列标识符联合体是否不存在。ROWCOL布隆过滤器的开销高于ROW布隆过滤器。
1.任何类型的get(基于rowkey和基于row+col)布隆过滤器都能生效,关键是get的类型要匹配过滤器的类型
2.基于row的scan是没办法优化的
scan是一个范围,如果是row的 过滤器不命中只能说明该rowkey不在此storefile中,但next rowkey可能在。
3.row+col+qualify的scan可以去掉不存在此qualify的storefile,也算是不错的优化了,而且指明qualify也能减少流量,因此scan尽量指明qualify。















 4108
4108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









