










目录
setConnectionTimeout & setConnectionRequestTimeout & setSocketTimeout
java原生java.net.HttpURLConnection
RestTemplate 与 Fegin 默认使用java原生HttpURLConnection
执行过程 CloseableHttpClient#execute
第一步:从PoolingHttpClientConnectionManager里拿连接对象
HttpClientConnection的底层实现org.apache.http.impl.conn.CPoolProxy内部核心CPoolEntry
总结
ps:
要注意的是:以下几个超时时间若没有设值,在某些框架的具体实现中表示无限制。在异常极端情况下会造成线程一直处于runnable 状态(通过 jstack 查看所线程的状态),但实际上却一直被卡在相关的IO阶段。
-
setConnectionRequestTimeout
Apache的http连接池才支持的写法。指从连接池内获取连接ConnectionRequest对象的timeout 。timeout > 0 表示有超时限制, 其他为无限制。
-
setConnectionTimeout
指客户端和服务器建立连接的timeout 。类似于http连接握手过程,超时后会ConnectionTimeOutException。
-
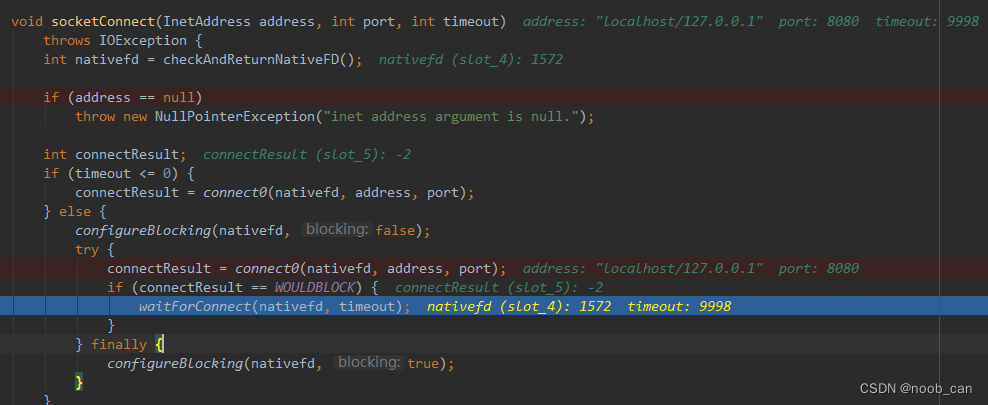
setSocketTimeout | setReadTimeout
底层就是Socket#setSoTimeout , 指客户端和服务连接建立后据传输过程中数据包之间间隔的最大时间,而不是整个交互的整体时间。
InputStream#read() 会阻塞超时,该选项必须在进入阻塞操作之前启用才能生效!应用在ServerSocket.accept()、SocketInputStream.read() 、DatagramSocket.receive()这几种阻塞场景。
// 底层代码
SocketInputStream: native int socketRead0(FileDescriptor fd, byte b[], int off, int len, int timeout)eg. 设置1秒超时,如果每隔0.8秒传输一次数据,传输10次,总共8秒,这样是不超时的。而如果任意两个数据包之间的时间超过了1秒,则超时SocketTimeoutException 。
- RestTemplate 与 Fegin :
默认都是使用java原生HttpURLConnection,每个URL都会创建一个HttpURLConnection实例。底层有HashMap + Stack 的结构(KeepAliveCache)缓存单个服务主机最大不超过maxConnections<5个>连接客户端HttpClient;优先取缓存中有效连接,若无直接创建,使用完后判定超过maxConnections直接关闭Socket,否则存入对应的栈里。
这也就是它的弊端: 创建上限只受限于机器性能, 极端情况下开启过多线程反而还影响处理效能!
它们都可以扩展使用Apache的http连接池化客户端CloseableHttpClient,连接池PoolingHttpClientConnectionManager内维护:总计不超过MaxTotal ,单个服务主机客户端不超过defaultMaxPerRoute的连接。创建并开启一个守护线程IdleConnectionEvictor循环关闭连接池里失效和超时空闲的链接。
要注意的是:一定要指定连接的keepAlive有效时间!否则默认是永久不过期, 程序没有关闭它的机会。
eg. 通常情况下,如果客户端在一次http请求完成后没有及时关闭流,那么超时后服务端就会主动发送关闭连接的FIN,客户端没有主动关闭,所以就停留在了CLOSE_WAIT状态,很快连接池中的连接就会被耗尽。
总结而言:都是以 URL的 protocol + host + port 做Key来缓存底层连接客户端的,底层最终还是Socket的同步阻塞式通信。
- tcpNoDelay :
开启后将禁用Nagle算法,数据包立刻发送出去。现代的 TCP/IP 协议栈默认是开启Nagle算法:在tcp报文传输过程中, 如果单个包大小满足最大报文段长度(MSS)将立即发送, 否则数据包会先缓存在缓冲区, 直到 已经发送的包都被ack了之后 或 数据积累到MSS后 才能继续发送;
- soKeepAlive:
- HTTP协议的Keep-Alive意图在于短时间内连接复用,短时间内在同一个连接上进行多次请求/响应, 需要服务端和客户端都同意才能使用长连接通信。
- TCP的KeepAlive机制意图在于保活、心跳,检测连接错误。太长时间没通讯发送1个无意义的字节探活报文,非正常关闭下需要尽快端口连接释放资源;但不能检测连接是否可用,所以应用层要自己实现心跳。
setConnectionTimeout & setConnectionRequestTimeout & setSocketTimeout
apache池化技术CloseableHttpClient支持的方法是:#setConnectionRequestTimeout、#setConnectTimeout、#setSocketTimeout;java原生HttpURLConnection 支持的方法 #setConnectTimeout、#setReadTimeout; #setReadTimeout与#setSocketTimeout作用一样。
在Spring提供的通信客户端创建工厂类org.springframework.http.client.HttpComponentsClientHttpRequestFactory源码注释里阐明它们的作用:



Socket#setSoTimeout
zookeeper的leader与learner的通讯Socket设置了该SoTimeout,以此来实现:心跳超时抛出异常后,socket关闭, 主线程break循环处理数据交互的广播模式并重新进入选主流程。
InputStream#read() 会阻塞超时。该选项必须在进入阻塞操作之前启用才能生效!

SocketOptions.SO_TIMEOUT 的源码注释里列出了几个阻塞超时场景:

SocksSocketImpl -> AbstractPlainSocketImpl#setOption


SocketInputStream#read:

如果报文传输超时,则会引发一个 java.net.SocketTimeoutException ,只要服务端不要在捕获该Exception后就直接关闭sokcet,依然可以拿socketInputStream处理 ,Socket仍然有效。
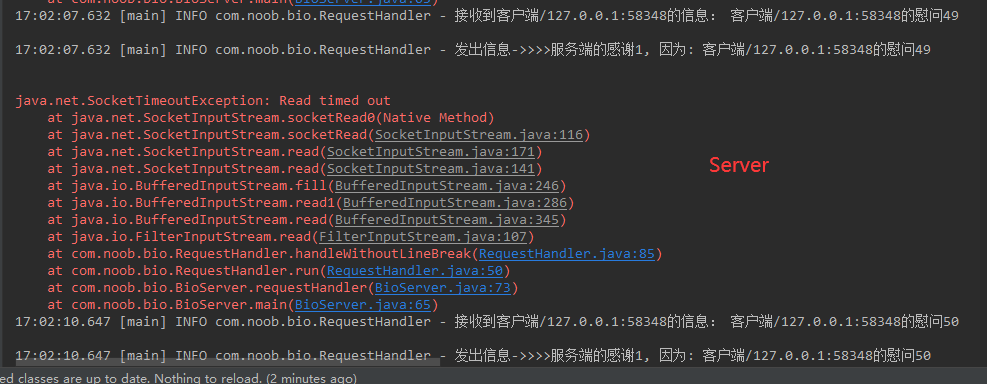
服务端主动关闭的语句:
clientSocket.shutdownInput();
clientSocket.shutdownOutput();
clientSocket.close();Socket#close()关闭之后再拿socket流读写时:

java原生java.net.HttpURLConnection
具体实现类: sun.net.www.protocol.http.HttpURLConnection,底层是sun.net.www.http.HttpClient 。HttpClient的构造函数里调用方法#openServer创建并开启与服务端的Socket。

- 每个new URL实例都会创建1个HttpURLConnection实例,它最底层HttpClient则是以 URL的 protocol + host + port 做key保存在 HashMap + Stack 的结构缓存KeepAliveCache里。
优先取缓存,没有就直接创建,这也就是说: 创建时无上限!用完了放入KeepAliveCache对应Key的栈ClientVector中,单个服务主机默认维持5个最大连接,多的会直接关闭。 见ClientVector#get()、#put() - HttpURLConnection的方法#getInputStream()、#getOutputStream() 和 HttpClient#getInputStream()、#openServer() 等方法 用synchronized修饰!意义在于:控制HttpURLConnection、HttpClient实例对象在多个syncronized修饰的方法里被同时使用;
- 要注意的是,HttpClient 本身默认是不支持维持活跃连接缓存的,但当方法执行到:HttpURLConnection#getInputStream -> HttpClient#parseHTTP(parseHTTPHeader) 时,会设置 keepAlive !
- KeepAliveCache内部有Timer每5s扫描关闭空闲超时的连接!见:keepAliveTimer;
protected HttpClient(URL var1, Proxy var2, int var3) throws IOException {
...
this.keepingAlive = false; // 不支持长连接
this.keepAliveConnections = -1; // 不维持活跃连接数 (适实际情况被更改)
this.keepAliveTimeout = 0;
...
this.host = var1.getHost();
this.url = var1;
this.port = var1.getPort();
if (this.port == -1) {
this.port = this.getDefaultPort();
}
this.setConnectTimeout(var3);
this.capture = HttpCapture.getCapture(var1);
this.openServer();
}更新 keepAliveConnections :
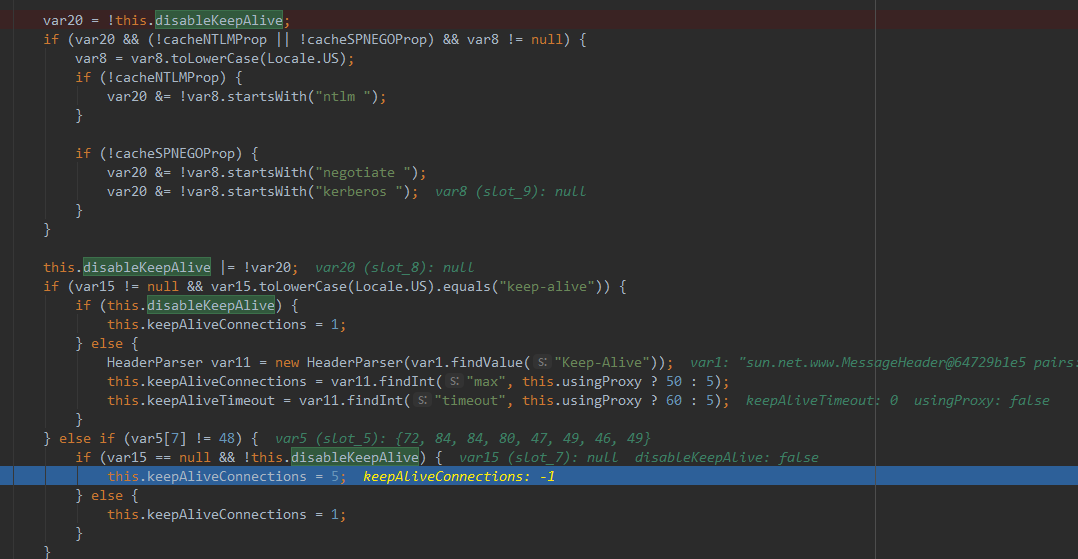
当HttpURLConnection完成了一次网络通信后 ( HttpURLConnection#getInputStream0:1852),向KeepAliveCache里保存使用的HttpClient, 再设置自己的HttpClient引用‘http’为空, 连接状态connected = false。

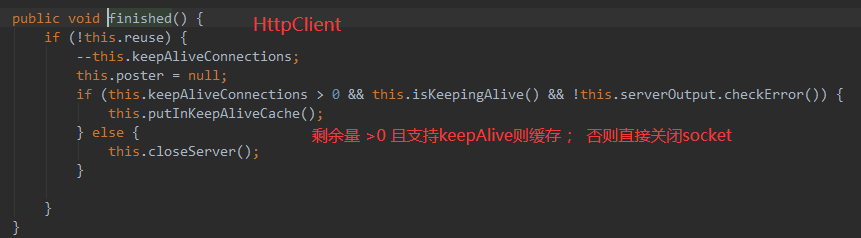
使用过程
- URL#openConnection:
每次new URL都会创建1个HttpURLConnection实例。这里只能给连接设置: #setConnectTimeout 、#setReadTimeout !
-
HttpURLConnection#connect() :
连接服务端时,执行HttpURLConnection#getNewHttpClient方法 :通过静态方法 HttpClient#New 来获取一个可用的HttpClient客户端实例。
优先将请求的URL解析为'KeepAliveKey'去静态hashMap缓存'KeepAliveCache'中获取到对应的存储栈ClientVector并弹出#pop(栈结构底层是Vector数组的LIFO:synchronized控制从队尾来添加和删除弹出,出栈时栈内将移出该对象KeepAliveEntry,内部封装的是HttpClient);KeepAliveKey则是以 [ URL的 protocol + host + port ] 作为唯一依据计算hashCode的。

// 重写了equals和hashCode 方法。 因为在构建时obj == null, 所以 url的 protocol + host + port 为唯一约束, 当做KeepAliveCache的key
class KeepAliveKey {
private String protocol = null;
private String host = null;
private int port = 0;
private Object obj = null;
// Object var2 参数值通常传入为null
public KeepAliveKey(URL var1, Object var2) {
this.protocol = var1.getProtocol();
this.host = var1.getHost();
this.port = var1.getPort();
this.obj = var2;
}
public boolean equals(Object var1) {
if (!(var1 instanceof KeepAliveKey)) {
return false;
} else {
KeepAliveKey var2 = (KeepAliveKey)var1;
return this.host.equals(var2.host) && this.port == var2.port && this.protocol.equals(var2.protocol) && this.obj == var2.obj;
}
}
public int hashCode() {
String var1 = this.protocol + this.host + this.port;
return this.obj == null ? var1.hashCode() : var1.hashCode() + this.obj.hashCode();
}
}
public class KeepAliveCache extends HashMap<KeepAliveKey, ClientVector> {
static final int MAX_CONNECTIONS = 5; // 最多保持活跃5个
...
class ClientVector extends Stack<KeepAliveEntry> {
private static final long serialVersionUID = -8680532108106489459L;
int nap;
synchronized HttpClient get() {
if (this.empty()) {
return null;
} else {
HttpClient var1 = null;
long var2 = System.currentTimeMillis();
do {
KeepAliveEntry var4 = (KeepAliveEntry)this.pop(); // 出栈后,栈内就无该实例了
if (var2 - var4.idleStartTime > (long)this.nap) { // 判定若空闲超时,则关闭该连接客户端
var4.hc.closeServer();
} else {
var1 = var4.hc;
}
} while(var1 == null && !this.empty());
return var1;
}
}
// 保存缓存时,判定如果超过了最大连接数就关闭, 默认是5
synchronized void put(HttpClient var1) {
if (this.size() >= KeepAliveCache.getMaxConnections()) {
var1.closeServer();
} else {
this.push(new KeepAliveEntry(var1, System.currentTimeMillis()));
}
}- 传输数据请求:HttpURLConnection#getOutputStream()输出流来输出二进制#writeRequests(),这里会补全在http的Header里设置 Connection:keep-alive 。需要在connect之前开启使用输出流:#setDoOutput ,默认false。
-
获取数据响应: HttpURLConnection#getResponseCode()、#getResponseMessage()、#getInputStream()等。默认是开启使用输入流。
http和https的客户端
![]()
对于Https协议,则是sun.net.www.protocol.https.HttpsURLConnectionImpl。 并维护了Https安全套接字协议的SSLSocketFactory、HostnameVerifier

RestTemplate 与 Fegin 默认使用java原生HttpURLConnection
- Spring提供的 org.springframework.web.client.RestTemplate 它的上层抽象父类HttpAccessor默认使用创建连接客户端工厂类方法SimpleClientHttpRequestFactory#createRequest 里指定使用了java原生的 java.net.HttpURLConnection。

- Fegin的具体实现ReflectiveFeign#invoke会根据传入的 接口+方法名 配置上具体的SynchronousMethodHandler#invoke,执行方法Client(Default)#execute,最终也是指定使用了java.net.HttpURLConnection。

池化客户端CloseableHttpClient
RestTemplate通过指定创建通信客户端工厂类HttpComponentsClientHttpRequestFactory 来使用apache的池化技术。
它底层是 org.apache.http.client.HttpClient,默认的实现类是org.apache.http.impl.client.CloseableHttpClient。CloseableHttpClient内部核心是org.apache.http.impl.conn.PoolingHttpClientConnectionManager,支持http和https。
// 管理连接池创建、访问入口
public class PoolingHttpClientConnectionManager
implements HttpClientConnectionManager, ConnPoolControl<HttpRoute>, Closeable {
private final Log log = LogFactory.getLog(getClass());
private final ConfigData configData; // HttpHost(网络Host) 与 SocketConfig 、 ConnectionConfig 的配置关系缓存
private final CPool pool; // 连接池真正的核心. 抽象父类AbstractConnPool里的Map<T, RouteSpecificPool<T, C, E>> routeToPool 保存了 HttpRoute与RouteSpecificPool 的关系,
// RouteSpecificPool标识一个服务端HttpRoute下最多不超过指定MaxPerRoute个的CPoolEntry
private final HttpClientConnectionOperator connectionOperator; // connect服务端过程处理操作
private final AtomicBoolean isShutDown;
private static Registry<ConnectionSocketFactory> getDefaultRegistry() {
return RegistryBuilder.<ConnectionSocketFactory>create()
.register("http", PlainConnectionSocketFactory.getSocketFactory())
.register("https", SSLConnectionSocketFactory.getSocketFactory())
.build();
}。PoolingHttpClientConnectionManager的核心是:org.apache.http.impl.conn.CPool 。
PoolingHttpClientConnectionManager是提供创建、操作的入口;CPool (准确的说是它的抽象父类AbstractConnPool)才是维护线程池所有连接, 而RouteSpecificPool 则是管理单个服务提供方对应的所有客户端。
CPool的抽象父类AbstractConnPool里分组保存了: 每一个服务提供方HttpRoute能保持最大不超过defaultMaxPerRoute个连接org.apache.http.impl.conn.CPoolEntry的集合RouteSpecificPool,整个连接池里连接总数不超过maxTotal。
- maxTotal: 连接池里总计最大连接数;
-
defaultMaxPerRoute: 与单个被访问的服务提供方同时保持连接的客户端最大个数。 一定要小于MaxTotal, 否则会出现:当总容量达到maxTotal时,后B服务连接创建时会导致删掉前A服务的有效连接。
// 线程池
public abstract class AbstractConnPool<T, C, E extends PoolEntry<T, C>> implements ConnPool<T, E>, ConnPoolControl<T> {
private final Lock lock; // ReentrantLock来控制获取、释放等操作并发
private final Condition condition;
private final ConnFactory<T, C> connFactory;
private final Map<T, RouteSpecificPool<T, C, E>> routeToPool;// 分组缓存每个服务主机对应的客户端CpoolEntry集合
private final Set<E> leased; // 正在使用中的连接 (不分服务主机)
private final LinkedList<E> available; // 所有有效可用的连接(不分服务主机)
private final LinkedList<Future<E>> pending;
private final Map<T, Integer> maxPerRoute;
...
//单个服务主机路由对应的客户端CpoolEntry集合
abstract class RouteSpecificPool<T, C, E extends PoolEntry<T, C>> {
private final T route; // HttpRoute 服务路由主机, 内部对应一个HttpHost
private final Set<E> leased; // 正在使用中的连接
private final LinkedList<E> available; // 所有有效可用的连接
private final LinkedList<Future<E>> pending;CloseableHttpClient的创建
// demo
public void init() {
PoolingHttpClientConnectionManager poolingConnectionManager = new PoolingHttpClientConnectionManager(2, TimeUnit.MINUTES); // 指定连接存活时长,如果未指定则是-1,表示Long.MAX_VALUE 基本可以说是永久有效了
int availableProcessors = Runtime.getRuntime().availableProcessors();
poolingConnectionManager.setMaxTotal(availableProcessors); // 连接池总计最大连接数
poolingConnectionManager.setDefaultMaxPerRoute(availableProcessors / 2); // 与单个被访问的服务主机同时保持连接的客户端最大个数。
// DefaultMaxPerRoute 一定要小于MaxTotal, 不然会出现:当总容量达到maxTotal时,后B服务连接创建时会删掉前A服务的有效连接。
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(poolingConnectionManager).disableAutomaticRetries()
.setDefaultRequestConfig(RequestConfig.custom().setConnectionRequestTimeout(10000)
.setConnectTimeout(10000).setSocketTimeout(30000).build()).build();
test(httpClient);
}
public static void test(CloseableHttpClient httpClient) {
for (int i = 0; i < 10; i++) {
HttpResponse response = null;
try {
// Post请求
HttpPost httppost = new HttpPost(i % 2 == 0 ? "http://www.baidu.com" : "http://www.360.com");
//设置post
httppost.getParams().setParameter("http.protocol.content-charset", HTTP.UTF_8);
httppost.getParams().setParameter(HTTP.CONTENT_ENCODING, HTTP.UTF_8);
httppost.getParams().setParameter(HTTP.CHARSET_PARAM, HTTP.UTF_8);
httppost.getParams().setParameter(HTTP.DEFAULT_PROTOCOL_CHARSET, HTTP.UTF_8);
//设置post编码
// 设置参数
List<NameValuePair> params = new ArrayList<NameValuePair>();
params.add(new BasicNameValuePair("appid", "xxxxx"));
httppost.setEntity(new UrlEncodedFormEntity(params, HTTP.UTF_8));
//设置报文头
httppost.setHeader("Content-Type", "application/x-www-form-urlencoded");
// 发送请求
response = httpClient.execute(httppost);
// 获取返回数据
HttpEntity entity = response.getEntity();
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
/**
* #writeTo在最后会做releaseConnection() 进入连接复用回收处理: 因为默认是keep-alive, 所以在MainClientExec#execute里拿到response后被reusable被设置为true了。 DefaultClientConnectionReuseStrategy 。
* 最终执行到 PoolingHttpClientConnectionManager#releaseConnection 将连接从leased置换入available集合里
*/
entity.writeTo(outputStream);
System.out.println(new String(outputStream.toByteArray(), "utf-8"));
} catch (IOException e) {
e.printStackTrace();
} finally {
if (response != null) {
try {
((CloseableHttpResponse) response).close(); // 这里从池化复用逻辑上来说是不需要了。 它会直接关闭掉该链接,不会连接池回收!!
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}HttpClientBuilder#build()创建 CloseableHttpClient 实例最终得到的对象是:org.apache.http.impl.client.InternalHttpClient, 它的核心是:org.apache.http.impl.execchain.ClientExecChain接口的实现类MainClientExec ,后续的执行都是由它来完成。
- 如果没有在外部指定PoolingHttpClientConnectionManager , 那么会自己内部创建一个该池化对象。
-
可以设置参数 RequestConfig: setConnectionRequestTimeout、 setConnectTimeout、 setSocketTimeout ... ; 直接针对于底层Socket的SocketConfig: soTimeout、 soKeepAlive、 tcpNoDelay... ; (不限于此)
-
创建并开启执行了一个守护进程IdleConnectionEvictor, 循环判定关闭连接池里失效和超时空闲的链接。 需要开启配置 :evictExpiredConnections evictIdleConnections (默认是false)
因为: 在MainClientExec#execute里执行完网络请求HttpRequestExecutor#execute拿到response后,
DefaultClientConnectionReuseStrategy判定HttpRequest默认是keep-alive, reusable被设置为true了 。如果response里有“timeout” 则会更新该连接的接下来的有效活跃时间:ConnectionHolder#setValidFor。

本例里 #writeTo方法内部最后将连接回收复用处理 -> 执行到 PoolingHttpClientConnectionManager#releaseConnection :
- 先通过ConnectionHolder的有效持续时间'validDuration' 来更新CPoolEntry的过期时间。PoolEntry#updateExpiry
- 将连接从leased置换入available集合里 AbstractConnPool#release -> RouteSpecificPool#free 。

所以 : 本例在最后finally里的 CloseableHttpResponse#close() 的执行是无效的,且也没必要: 它的逻辑是直接关闭掉连接,也不复用!
CloseableHttpClient(InternalHttpClient)#close() 方法默认是关闭 PoolingHttpClientConnectionManager 和 IdleConnectionEvictor, IdleConnectionEvictor线程每隔10s关闭过期和空闲的连接 HttpClientConnection#close。
public IdleConnectionEvictor(
final HttpClientConnectionManager connectionManager,
final ThreadFactory threadFactory,
final long sleepTime, final TimeUnit sleepTimeUnit,
final long maxIdleTime, final TimeUnit maxIdleTimeUnit) {
this.connectionManager = Args.notNull(connectionManager, "Connection manager");
this.threadFactory = threadFactory != null ? threadFactory : new DefaultThreadFactory();
this.sleepTimeMs = sleepTimeUnit != null ? sleepTimeUnit.toMillis(sleepTime) : sleepTime;
this.maxIdleTimeMs = maxIdleTimeUnit != null ? maxIdleTimeUnit.toMillis(maxIdleTime) : maxIdleTime;
this.thread = this.threadFactory.newThread(new Runnable() {
@Override
public void run() {
try {
while (!Thread.currentThread().isInterrupted()) {
Thread.sleep(sleepTimeMs);
connectionManager.closeExpiredConnections(); // 关闭过期连接
if (maxIdleTimeMs > 0) {
connectionManager.closeIdleConnections(maxIdleTimeMs, TimeUnit.MILLISECONDS); // 关闭空闲连接
}
}
} catch (final Exception ex) {
exception = ex;
}
}
});
}执行过程 CloseableHttpClient#execute
// InternalHttpClient extends CloseableHttpClient
public CloseableHttpResponse execute(
final HttpUriRequest request,
final HttpContext context) throws IOException, ClientProtocolException {
Args.notNull(request, "HTTP request");
return doExecute(determineTarget(request), request, context);
}CloseableHttpClient#determineTarget -> URIUtils#extractHost 根据Url创建HttpHost, 可以很明确的看出: 它的构造属性和HttpURLConnection的缓存键KeepAliveKey是一样的!

HttpRoute内部持有一个HttpHost,还有其他属性及判定逻辑,会复杂一些;但对于其他上下文一致的URL,基本可以认定HttpRoute就是HttpHost。
第一步:从PoolingHttpClientConnectionManager里拿连接对象

最终执行: org.apache.http.conn.ConnectionRequest#get 来获取HttpClientConnection。它的入参“timeout” 就是从RequestConfig里拿到的ConnectionRequestTimeout , 这个方法会被block直到有连接可用!

底层执行方法PoolingHttpClientConnectionManager#leaseConnection使用java.util.concurrent.Future#get(long timeout, TimeUnit unit) 阻塞获取方式,超时抛出异常TimeoutException: Timeout waiting for connection from pool
下面来看两种执行情况
- 首次创建连接:

- 获取历史有效连接:


HttpClientConnection的底层实现org.apache.http.impl.conn.CPoolProxy内部核心CPoolEntry
在AbstractConnPool#getPoolEntryBlocking 过程里:(通过ReentrantLock来控制整个从池里拿连接的过程)
#getPool : 根据HttpRoute拿缓存里的CPoolEntry!如果没拿到空闲状态下的CPoolEntry, 会新增创建并缓存在RouteSpecificPool里。

缓存本质上是HashMap,所以缓存key就是HttpRoute#hashCode()。

这里要重点说明的是:
1、配置时: defaultMaxPerRoute 一定要小于MaxTotal, 不然会出现:当总容量达到maxTotal时,后B服务连接创建时会导致删掉前A服务的有效连接。见下图二部分
(在下图代码片段之前逻辑里, 优先是: 依据HttpRoute从#getPool方法获取到单个服务主机对应的连接池,再从池子里拿可用连接!)
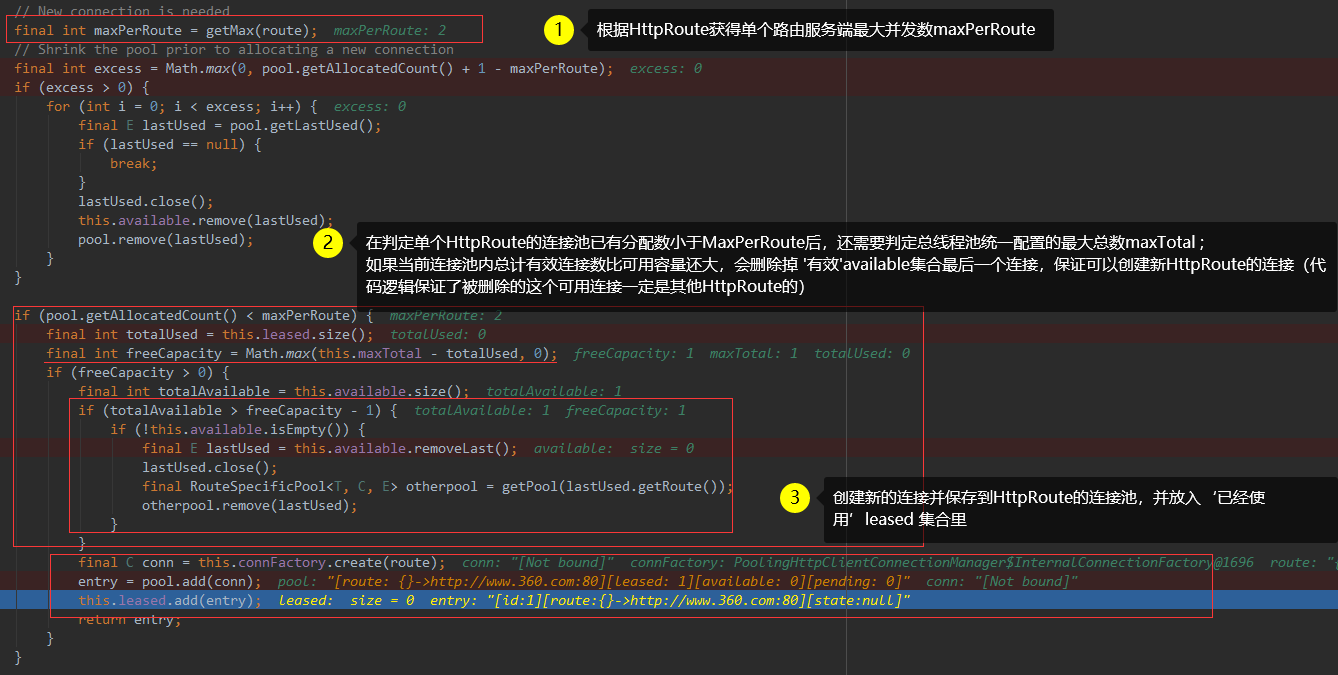
2、 如果没有指定连接的存活时间,默认是永久有效!

第二步: 给连接设置Socket,连接远端服务发送请求
- 如果是新的Connection,拿获取到的连接实例HttpClientConnection,创建新的Socket并与连接绑定,再与远端服务发起握手指令。
MainClientExec#establishRoute -> DefaultHttpClientConnectionOperator#connect -> HttpRequestExecutor#execute - 如果不是新的Connection,不会执行MainClientExec#establishRoute, 直接执行HttpRequestExecutor#execute发起请求。

















 938
938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









