






前言
在上一节我们介绍完最基本的一些WinAPI函数之后,这一节来讲解一下正常我们该如何处理字符串
无论是什么程序,我们在使用的时候都绕不开文字这一环节,无论是给他人看或者是给自己看,都需要使用文字来使他人/自己看懂。因此,我们应该学习一下该如何处理代码以及程序中显示出来的字符。
毫无疑问,这将是一个枯燥无味的过程,但以后我们又有很大可能用到这些函数,所以便单独写了这一节。当然,这一节涉及到WinAPI的知识会比较少
下面来介绍一些用于处理字符串的函数
1.获取字符串长度
这个函数我们在学C语言的时刻肯定也接触过,主要是strlen和wcslen
用代码形式表示就是
size_t strlen (const char* str);//char类型字符串指针
size_t wcslen (const wcahr_t* str);//wcahr_t类型字符串指针
其中wcslen是strlen的宽字符版本,wcslen的参数是宽字符串,返回值是宽字符串个数。这两个函数的返回值都不包括字符串结尾的0,示例如下:
#include<Windows.h>
#include<tchar.h>
#include<stdio.h>
int main() {
CHAR str[] = "C语言";
WCHAR wstr[] = L"C语言";
//_tprintf是printf、wprintf的通用版本,稍后介绍_tprintf函数
_tprintf(TEXT("strlen(str)=%d,wcslen(wstr)=%d\n"), strlen(str), wcslen(wstr));
return 0;
}
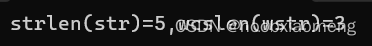
此外,这两个函数还有一个通用版本——_tsclen,我们可以看一下它的定义:
#ifdef _UNICODE
#define _tcslen wcslen
#else
#define _tcslen strlen
#endif
也就是说,_tsclen在我们使用UNICODE字符集的时候就为wcslen,否则为strlen,请看下面这段代码
#include<Windows.h>
#include<tchar.h>
#include<stdio.h>
int main() {
TCHAR szStr[] = TEXT("C语言");//3 or 5
_tprintf(TEXT("_tcslen(szStr)=%d\n"), _tcslen(szStr));
}
如果将项目属性设置为Unicode字符集,则输出结果为3;如果将项目属性设置为多字节字符集,则输出结果为5,我们可以右击项目
点击属性
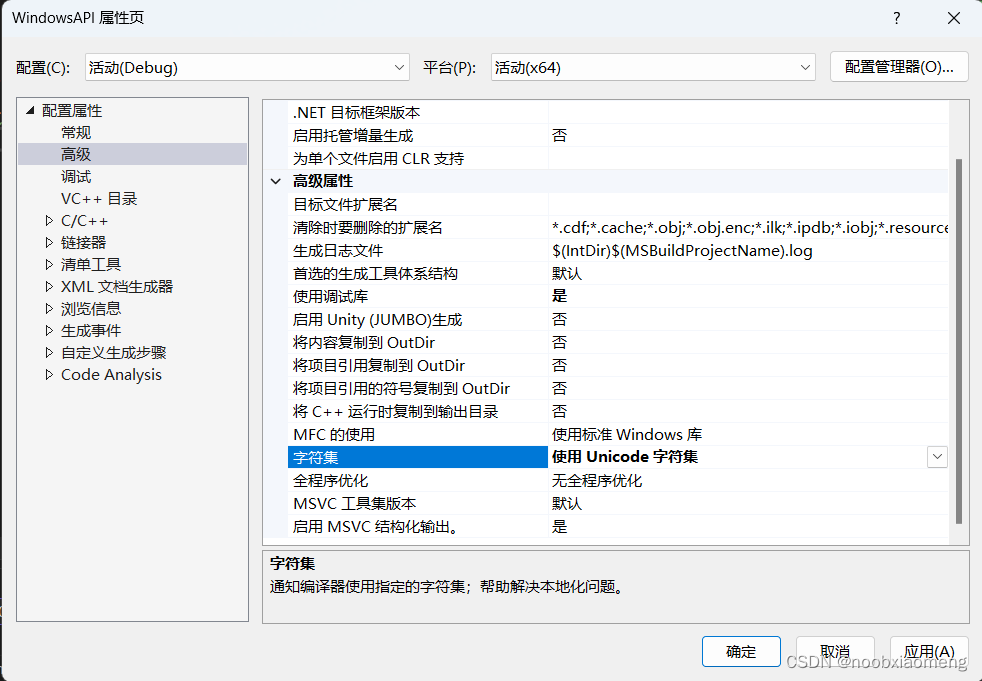
在字符集中可以更改选项,从而使用不同的字符集
2.查找一个字符串中出现的指定字符
我们通常使用strchr和strrchr分别查找一个字符串中首次出现的指定字符和一个字符串中最后出现的指定字符,它们的返回值为该字符出现的地址。这两个函数的通用版本分别是_tcschr和_tcsrchr,若没有找到指定的字符或函数执行失败,则返回值为NULL。这两个函数的用法为_tcschr(<被查找的字符串>,<你想要查找的字符>),函数声明就不再列出了,下面是一个示例:
#include<Windows.h>
#include<tchar.h>
#include<stdio.h>
#include<locale.h>
int main() {
TCHAR szStr[] = TEXT("C++是世界上最好的编程语言!.py");
LPTSTR lp = _tcschr(szStr, TEXT('最'));
setlocale(LC_ALL, "chs"); //用_tprintf函数输出中文字符的时候,需要调用本函数设置区域,设置区域为chs
_tprintf(TEXT("szStr的地址:%p\nlp的地址:%p\n"), szStr, lp);
_tprintf(TEXT("szStr = %s\nlp = %s\n"), szStr, lp);
}
下面分别是该段代码在Unicode字符集和多字节字符集运行的结果
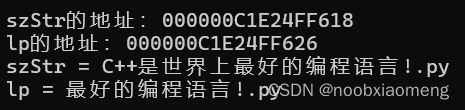
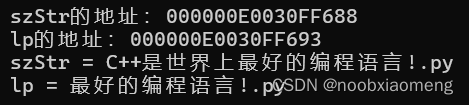
我们将这两个结果的地址分别相减:
0xC1E24FF626 - 0xC1E24FF618=14(十进制)
0xE0030FF693 - 0xE0030FF688=11(十进制)
发现两者的差值是3,造成结果不同的原因是,在Unicode字符集中,“C++”中的每一个字符都占用两个字节,而在多字节字符集中,”C++“中的每一个字符仅占用一个字节,因此两种运行结果中lp都是正确的
3.在一个字符串中查找另一个字符串
在一个字符串中查找另一个字符串首次出现的位置使用strstr和wcsstr函数,它们的通用版本是_tcsstr:
char *strstr(
const char *str, //在这个字符串中搜索
const char *strSearch //要搜索的字符串
);
wchar_t *wcsstr(
const wchar_t *str,
const wchar_t *strSearch
);
与查找指定字符的函数相同,这两个函数返回strSearch在str中首次出现的地址;若strSearch不是str的子串,则返回值为NULL
下面是一个示例代码:
#include<Windows.h>
#include<tchar.h>
#include<stdio.h>
#include<locale.h>
int main() {
TCHAR szStr[] = TEXT("Hello,Windows,this is a Windows API program!");
TCHAR szStrSearch[] = TEXT("Windows");
_tprintf(TEXT("%s\n"), _tcsstr(szStr, szStrSearch));
}

4.从一个字符串中查找另一个字符串中的任何一个字符
从一个字符串中查找另一个字符串的任何一个字符首次出现的位置使用strpbrk和wcspbrk函数,通用版本是_tcspbrk:
char *strpbrk(
const char *str,
const char *strCharSet);
char *wcspbrk(
const wchar_t *str,
const wchar_t *strCharSet);
函数在源字符串str中找到最先含有搜索字符串strCharSet中任一字符的位置并返回,下面是一个示例
#include<Windows.h>
#include<tchar.h>
#include<stdio.h>
#include<locale.h>
int main() {
TCHAR szStr[] = TEXT("The 3 men and 2 boys ate 5 pigs");
TCHAR szStrCharSet[] = TEXT("0123456789");
LPTSTR lpSearch = NULL;
_tprintf(TEXT("1:%s\n"), szStr);
lpSearch = _tcspbrk(szStr, szStrCharSet);
_tprintf(TEXT("2:%s\n"), lpSearch);
lpSearch++;
lpSearch = _tcspbrk(lpSearch, szStrCharSet);
_tprintf(TEXT("3:%s\n"), lpSearch);
}

5.转换字符串中的大小写
将小写字母转大写:
char *_strupr(char *str);
wchar_t *_wcsupr(wchar_t *str);
这两个函数将str字符串中的小写字母转为大写形式,其他字符不受影响,返回修改后的字符串指针,它们的通用版本是_tcsupr
将大写字母转小写:
char *_strlwr(char *str);
char *_wcslwr(wchar_t *str);
这两个函数将str字符串中的大写字母转为小写形式,其他字符不受影响,返回修改后的字符串指针,它们的通用版本是_tcslwr
下面是一个有关大小写转换的示例:
#include <Windows.h>
#include <tchar.h>
#include <stdio.h>
#include <locale.h>
int main() {
// 设置本地化环境为 UTF-8
_tsetlocale(LC_ALL, TEXT(".UTF8"));
TCHAR szStr[] = TEXT("我正在学习WindowsAPI编程");
_tcslwr_s(szStr, _countof(szStr));
_tprintf(TEXT("%s\n"), szStr);
_tcsupr_s(szStr, _countof(szStr));
_tprintf(TEXT("%s\n"), szStr);
return 0;
}

此外,还有将单个字符进行大小写转换的函数:小写转大写的函数是toupper和towupper,通用版本是_totupper;大写转小写的函数是tolower和towlower,通用版本是_totlpwer。同样,非字母字符不做任何处理
6.字符串拼接
先看一下函数的定义:
char* strcat(
char* strDestination, //目标字符串
const char* strSource);//源字符串
wchar_t* wcscat(
wchar_t* strDestination,
const wchar_t* strSource);
这两个函数的通用版本是_tcscat,函数的用法是将源字符串strSource附加到目标字符串strDestination后面,返回指向目标字符串的指针,在VS2022中,我们大概率需要使用安全版本的_tcscat_s函数,其函数定义多了一条参数:
errno_t strcat_s(
char* strDestination,
size_t numberOfElements, //目标字符串缓冲区的大小,字符单位
const char* strSource);
errno_t wcscat_s(
wchar_t* strDestination,
size_t numberOfElements, //目标字符串缓冲区的大小,字符单位
const wchar_t* strSource);
下面是一个示例代码:
#include<Windows.h>
#include<tchar.h>
#include<stdio.h>
#include<locale.h>
int main() {
// 设置本地化环境为 UTF-8
_tsetlocale(LC_ALL, TEXT(".UTF8"));
TCHAR szStrDest[64] = TEXT("WindowsAPI");
TCHAR szStrSour[] = TEXT("好多,好难..");
_tcscat_s(szStrDest, _countof(szStrDest), szStrSour);
_tprintf(TEXT("%s\n"), szStrDest);
}
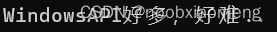
我们可以看见,szStrSour会被拼接在szStrDest后面
不难发现,我们在转换字符串大小写的时候和这里一样,都使用了_countof宏,这个宏用于获取有关数组中的元素个数(即数组大小),本例中_countof(szStrDest)返回值是64,此外,我们通常还会使用sizeof,在本段代码使用sizeof时,若设置为Unicode字符集,则会返回128,多字节字符集则返回64
7.字符串复制
我想大部分人都用过字符串复制函数strcpy和wcscpy,这里就不过多介绍用法了,其通用版本为_tcscpy_s,这次仅给出示例代码:
#include<Windows.h>
#include<tchar.h>
#include<stdio.h>
#include<locale.h>
int main() {
// 设置本地化环境为 UTF-8
_tsetlocale(LC_ALL, TEXT(".UTF8"));
TCHAR szStrDest[64];
TCHAR szStrSour[] = TEXT("WindowsAPI好多,好难..");
_tcscpy_s(szStrDest, _countof(szStrDest), szStrSour);
_tprintf(TEXT("%s\n"), szStrDest);
_tprintf(TEXT("%s\n"), szStrSour);
}

可以看见我们没有初始化szStrDest但是通过复制函数使其能够有效输出
然后再额外讲一下_tcscpy_s的缺点以及解决的方法。为我们在调用_tcscpy_s函数时,目标字符串缓冲区不仅需要足够大以保存源字符串的,而且还需要注意到其结尾的"\0"。但是,有时候某些字符串并不一定是以0结尾,当字符串指针指向一块很大的数据且不以0结尾时,若有一个0字符,这时候调用_tcscpy_s函数就会出现目标缓冲区太小的错误提示
若出现上述情况,我们可以使用后面要介绍的StringCchCopy函数。StringCchCopy函数只会从字符串指针指向的字符串中复制5-1个字符,并把目标数组的缓冲区的第5个字符设置为0,要想得到5个字符的以0结尾的字符串,可以把StringCchCopy函数的第二个参数设置为5+1
此外,我们不仅可以使用_tcscpy_s函数于用来代替它的StringCchCopy函数,还可以使用内存复制函数memcpy_s(后面会详细介绍),该函数可以指定目标缓冲区和源缓冲区的字节数,不会出现缓冲区溢出
同样,上文介绍的字符串拼接函数亦可以使用StringCchCat函数代替,理由同上
8.字符串比较
比较两个字符串大小关系的函数是strcmp和wcscmp,通用版本是_tcscmp:
int strcmp(
const char *string1,
const char *string2);
int wcscmp(
const wchar_t *string1,
const wchar_t *string2);
函数对string1与string2的ASCII码值比较并返回一个指示它们关系的值。返回值能够指明这两个字符串的大小关系。根据第一个参数大于、小于或等于第二个参数分别返回大于、小于或等于0
接下来介绍两个字符串比较的规则:
逐个比较两个字符串中对应的字符,字符大小按照ASCII码的值确定,从左至右开始比较,若字符相同则逐步右移,当字符不同时则开始比较大小,从而确定字符串大小;若未遇到不相同的个字符而某个字符串先结束,那么先结束的字符串是较小的;否则两个字符串相等。例如:
#include<Windows.h>
#include<tchar.h>
#include<stdio.h>
#include<locale.h>
int main() {
// 设置本地化环境为 UTF-8
_tsetlocale(LC_ALL, TEXT(".UTF8"));
TCHAR szStr1 [] = TEXT("ABCDE");//E的ASCII码值为0x45
TCHAR szStr2 [] = TEXT("ABCDe");//e的ASCII码值为0x65
int n = _tcscmp(szStr1, szStr2);
if (n > 0)
_tprintf(TEXT("szStr1 大于 szStr2\n"));
if (n < 0)
_tprintf(TEXT("szStr1 小于 szStr2\n"));
else
_tprintf(TEXT("szStr1 等于 szStr2\n"));
}

我们可以通过更改字符串实现不同的输出
_tcscmp按照ACSII值比较大小,因此字符需要区分大小写。若不想区分大小写,我们可以使用_tcsicmp函数进行比较,其在比较之前会将字符串转化为小写形式,从而适用于不区分大小写的字符串比较
当然,作为中国公民,在编程程序的时候应当考虑中文字符串比较的问题,当我们使用Unicode字符集时,由于Unicode字符集是国际化编码,用一套字符集表示所有国家的字符。我们同样可以调用代码行setlocale(LC_ALL,"chs")来进行中文区域设置。这时,我们可以通过_tcscoll函数进行比较,至于比较的规则,由于我未详细了解过,这里就不方便过多介绍了,否则容易误导他人,还请各位自行查询
9.分割字符串
用于分割字符串的函数是strtok、wcstok和_tcstok,我们通常使用它们的安全版本。函数声明如下:
char* strtok_s(
char* strToken, //要分割的字符串
const char* strDelimit,//分割符字符串,即碰见这个字符串中的任何一个字符就会进行分割
char** context); //返回原字符串剩余未被分割的部分,提供一个字符串
char* wcstok_s(
char* strToken,
const char* strDelimit,
char** context);
当函数在参数strToken字符串中发现其包含分割符的时候,会将该字符修改为字符0。若strToken不包含分割符,则直接返回字符串本身。可能用文字无法直观并且详细的描述,通过示例代码也许能够对字符串分割函数有更加明显的特征,请看下面这段示例代码:
#include<Windows.h>
#include<tchar.h>
#include<stdio.h>
#include<locale.h>
int main() {
// 设置本地化环境为 UTF-8
_tsetlocale(LC_ALL, TEXT(".UTF8"));
TCHAR strToken[] = TEXT("Just tell you the string do want,my friend");
TCHAR strDelimit[] = TEXT(", \t");
LPTSTR lpToken = NULL;
LPTSTR lpTokenNext = NULL;
lpToken = _tcstok_s(strToken, strDelimit, &lpTokenNext);
while (lpToken != NULL) {
_tprintf(TEXT("%s\n"), lpToken);
lpToken = _tcstok_s(NULL, strDelimit, &lpTokenNext);
}
}
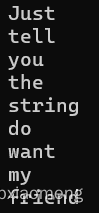
不难看出,当字符串遇见空格和逗号时都进行了分割
10.字符串快速排序
进行字符串快速排序的函数是qsort,这个函数我也不太明白,先看示例:
#include<Windows.h>
#include<tchar.h>
#include<stdio.h>
#include<locale.h>
//回调函数声明
int compare(const void* arg1, const void* arg2) {
return _tcscoll(*(LPTSTR*)arg1, *(LPTSTR*)arg2 );
}
int main() {
// 设置本地化环境为 UTF-8
_tsetlocale(LC_ALL, TEXT(".UTF8"));
/*
LPCTSTR arrStr[] = {
TEXT("我超,原!"),
TEXT("第五人格,启动!"),
TEXT("逃到这里应该就没有村里人了吧。。"),
TEXT("死农p"),
TEXT("原来你也玩崩铁"),
TEXT("将军既食汉禄,何为汉贼?")
};
*/
LPCTSTR arrStr[] = {
TEXT("5"),
TEXT("3"),
TEXT("9"),
TEXT("6"),
TEXT("8"),
TEXT("1")
};
qsort(arrStr, _countof(arrStr), sizeof(LPTSTR), compare);
for (int i = 0; i < _countof(arrStr); i++) {
_tprintf(TEXT("%s "), arrStr[i]);
}
return 0;
}
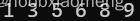
本来这一段想用汉字或者英文来作为示例的,但想了想觉得数字更能直观表示排序。其中_tcscoll函数在字符串比较那一段中提起过,忘记了的话可以回去查看一下其作用
此外,上述代码涉及回调函数,仅查看示例代码可能对qsort函数的用法不太清晰,这里给出函数的声明:
void qsort(
void* base, //待排序的字符串数组
size_t num, //待排序字符串数组的元素个数
size_t width, //以字节为单位,各元素占用空间大小
int(__cdecl* compare)(const void*,const void*));//对字符串进行比较的回调函数
void qsort_s(
void* base,
size_t num,
size_t width,
int(__cdecl* compare)(const void*,const void*),
void context); //上面回调函数的参数
qsort_s是qsort的安全版本,这两个函数用于对指定数组中的元素进行排列。当然,数组元素也可以是其他类型,比如int型。当我们进行排序的时候,qsort函数会调用compare回调函数对两个数组元素进行比较(比较的规则根据函数决定)这就是回调函数,回调函数由qsort函数负责调用,我们只会还会遇到由操作系统调用的回调函数。在本例中是升序排列,若需要降序排列,只需将_tcscoll函数的两个参数互换即可
在完成数组元素排序之后,我们二分查找应该数组元素就很快了,在这需要使用bsearch函数:
void* bsearch(
const void* key, //要查找的数据
const void* base, //要从中查找的数据
size_t num, //被查找数组中的数组元素个数
size_t width, //每个数组元素的长度,以字节为单位
int(__compare)(const void* key,const void* datum));//进行比较的回调函数
函数用二分查找法从数组元素base[0]~base[num-1]中查找参数key指向的数据。数组base中的元素应以升序排列,函数bsearch的返回值指向匹配项;若未发现匹配项,则返回NULL。次函数的用法与qsort函数类似,这里就不过多举例了
11.字符串与数值型的相互转换
说实话,这一块我在看书的时候有点懵逼。很多而且很长,抓不到重点,在这我会尽己所能将其既简略又完整的表述出来
- 将字符串转换为double型的函数是
atof和_wtof,通用版本是_ttof - 将字符串转换为int型的函数是
atoi和_wtoi,通用版本是_ttoi - 将字符串转换为int64型(long long型)可以使用
_atoi64和_wtoi64通用版本是_ttoi64(atoll和_wtoll通用版本是_ttoll)
这里转换的意思可能不太准确,应当是仅转换字符串中的数字部分等
上述函数并不要求字符串str必须是数值类型,在此以_ttof函数为例,假设字符串为"-3.1415926圆周率",调用_ttof(str)函数返回的结果为double型的-3.1415926。函数会跳过前面的空格字符,直到遇到数字或者正负符号才开始转换,直到出现非数字或字符串结束标志时结束转换,并将转换后的结果返回。若开头部分就是不可转换字符,例如"圆周率3.1415926",则会返回0.0
还有将数值型转换为字符串的相关通用函数,这里便不再列出了,各位自行查找
但是,当我们修改字符串缓冲区的函数都存在一个缓冲区溢出安全隐患,一般在VS2022中会有有关提示,因此建议使用这些函数的安全版本,也就是加上_s,而且函数的参数需要加上指定缓冲区的大小,数值转为字符串的话还需要加上你需要转换的进制数,可以选择2、8、10、16进制。如果函数返回成功,则返回0;如果函数执行失败,则返回相关示例代码
上文介绍过将字符串转换为双精度浮点型(double)、整型(int)、或64位整型(int64)的函数是_ttof、_ttoi、_ttoi64,与之类似的还有_tcstod、_tcstol、_tcstoi64等函数。这些函数多了两个参数,分别用于返回成功转换的最后一个字符之后的剩余字符串指针(即非数字部分)和指定转换数字的进制,同样可以指定为2、8、10、16。下面有一个示例函数:
#include<Windows.h>
#include<tchar.h>
#include<stdio.h>
#include<locale.h>
//回调函数声明
int compare(const void* arg1, const void* arg2) {
LPTSTR p1 = NULL;
LPTSTR p2 = NULL;
double d1 = _tcstod(*(LPTSTR*)arg1, &p1);
double d2 = _tcstod(*(LPTSTR*)arg2, &p2);
//相比较数字,若数字相同,则比较数字后面的字符串
if (d1 != d2) {
if (d1 > d2)
return 1;
else
return -1;
}
else {
return _tcscmp(p1, p2 );
}
}
int main() {
// 设置本地化环境为 UTF-8
_tsetlocale(LC_ALL, TEXT(".UTF8"));
LPCTSTR arrStr[] = {
TEXT("6、我超,原!"),
TEXT("4、第五人格,启动!"),
TEXT("2、逃到这里应该就没有村里人了吧。。"),
TEXT("5、死农p"),
TEXT("1、原来你也玩崩铁"),
TEXT("3、将军既食汉禄,何为汉贼?")
};
qsort(arrStr, _countof(arrStr), sizeof(LPTSTR), compare);
for (int i = 0; i < _countof(arrStr); i++) {
_tprintf(TEXT("%s\n"), arrStr[i]);
}
return 0;
}

本例模拟的是Windows资源管理器对文件进行排序的结果
12.格式化字符串
在C语言中,我们不得不提起printf函数,大部分人的第一个程序都使用了它,真令人怀念以前只用写简单程序的日子……
此外我们还有wprintf函数,与printf函数几乎一样。这两个函数的通用版本是_tprintf,我们在上文中没少使用它,如果我们定义了_UNICODE,则_tprintf会被转换为wprintf,否则为printf。输出中文时需要在本地设置中文环境
但是很多类似于printf的函数都会有缓冲区溢出安全隐患,因此我们可以寻找新的函数来代替它们。C/C++运行库提供了新增安全版本函数StringCbPrintf、StringCchPrintf等,但在目前阶段,我们的大多数程序都不需要考虑这些问题。这些函数包含在<strsafe.h>头文件中,使用时需要添加一个指定缓冲区大小的参数
同样,我们还可以使用限定最大长度的_sntprintf_s或_vsntprintf_s函数
下面以StringCchPrintf函数为例来说明格式化字符串函数的使用:
#include<Windows.h>
#include<strsafe.h>
#include<tchar.h>
#include<locale.h>
#include<stdio.h>
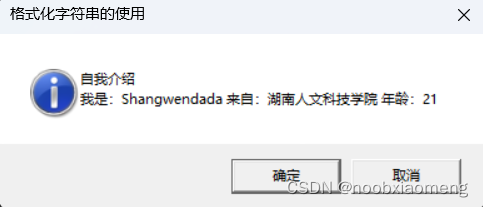
int WINAPI WinMain(_In_ HINSTANCE hInstance, _In_opt_ HINSTANCE hPrevInstance, _In_ LPSTR lpCmdLine, _In_ int nShowCmd) {
// 设置本地化环境为 UTF-8
_tsetlocale(LC_ALL, TEXT(".UTF8"));
TCHAR szName[] = TEXT("Shangwendada");
TCHAR szSchool[] = TEXT("湖南人文科技学院");
int age = 21;
TCHAR szBuf[128] = { 0 };
HRESULT hResult = E_FAIL; //设置返回值
hResult = StringCchPrintf(szBuf, _countof(szBuf),TEXT("自我介绍\n我是:%s 来自:%s 年龄:%d\n"),szName,szSchool,age);
if (SUCCEEDED(hResult))
MessageBox(NULL, szBuf, TEXT("格式化字符串的使用"), MB_OKCANCEL | MB_ICONINFORMATION);
else
MessageBox(NULL, TEXT("函数执行失败"), TEXT("错误提示"), MB_OKCANCEL | MB_ICONINFORMATION);
return 0;
}
13.字符串格式化为指定类型的数据
这个函数我看着也很迷惑。。
前面我们学习了一些格式化字符串函数,实际编程中可能还需要把字符串格式化为指定类型的数据。例如sscanf_s(多字节版本)和swscanf_s(宽字符版本)函数可以从字符串缓冲区将数据读取到每一个参数中。这两个函数与scanf函数的区别是,后者以标准输入设备为源,也就是大部分情况都在我们的键盘上获取数据,而前者以指定的字符串为输入源,也就是根据字符串指针或者指定的缓冲区中的字符串为输入源。下面是函数声明:
int sscanf_s(
const char* buffer, //字符串缓冲区
const char* format, //格式控制字符串,支持条件限定和通配符
[, arhumengt...]); //参数指针,返回数据到每个参数
int swscanf_s(
const wchar_t* buffer,
const wchar_t* format,
[, arhumengt...]);
下面是一个将16进制形式的字符串转为16进制数再以10进制输出的示例:
#include <Windows.h>
#include <tchar.h>
#include <stdio.h>
#include <locale.h>
int main() {
// 设置本地化环境为 UTF-8
_tsetlocale(LC_ALL, TEXT(".UTF8"));
DWORD dwTargetRVA;
TCHAR szBuf[32] = TEXT("1234ABCD");
// 将十六进制字符串转换为 DWORD 类型
_stscanf_s(szBuf, TEXT("%X"), &dwTargetRVA);
// 打印 DWORD 类型变量的值
_tprintf(TEXT("dwTargetRVA: %d\n"), dwTargetRVA); //以10进制输出16进制数
return 0;
}

根据输出我们可以判断字符串已经发生了类型转换
14.Windows中的一些字符串函数
Windows也提供了各种字符串处理函数,但大部分在VS2022中都会出现安全问题的警告,下面我们来认识一下这些函数。
-
(1) lstrlen
用于计算字符串长度,以字符为单位:
int WINAPI lstrlen(_In_ LPCTSTR lpString); -
(2) lstrcpy和StringCchCopy
用于字符串复制:
LPTSTR WINAPI lstrcpy(
_Out_ LPTSTR lpString1,
_In_ LPTSTR lpString2);
其中lstrcpy函数可能造成缓冲区溢出,会出现不安全警告,在最坏的情况下,如果lpstring1是基于堆栈的缓冲区,则缓冲区溢出可能会导致攻击者向进程中注入可执行代码
因此我们应尽可能使用更安全的函数,比如StringCchCopy函数,此函数在执行字符串处理的时候提供更多控制:
HRESULT StringCchCopy(
_Out_ LPTSTR pszDest, //目标缓冲区
_In_ size_t cchDest, //目标缓冲区的大小
_In_ LPCTSTR pszSrc); //源字符串
其中cchDest参数指定的大小必须大于或等于字符串pszSrc的长度加1,以容纳复制的源字符串和终止的空字符。cchDest参数允许的最大字符数为2147483647,即int型的最大数值。该函数需要包含<strsafe.h>头文件
不难注意到StringCchCopy函数的返回值类型为HRESULT类型,可以用于判断函数是否执行成功。这里就不过多介绍了,各位感兴趣的话可以自行查阅相关找资料
-
(3) lsrcat和StringCchCat
这两个函数与上面的lstrcpy和StringCchCopy用法类似,各位可以自行比较 -
(4) lstrcmp、lstrcmpi和CompareStringEx
这是字符串比较函数,前文中有提到过关于字符串比较的问题,这里就不再详细表述了,仅作为字符串比较函数拓展,感兴趣的话可以自行查阅
15.函数名、变量名命名规则
在这一节的很多示例代码中,我们对于变量的命名看起来十分奇怪,一会大写一会小写的,打起字来十分不方便。但事实上,这是以驼峰命名法来命名的,我们混合使用大小写字母来构成变量和函数的名字。而变量名是由多个单词组成时,第一个单词以小写字母开始,之后每一个单词的首字母都大写,例如myFirstProject,myRealName等,这样的变量名看上去就像骆驼峰一样此起彼伏,故得名
-
小驼峰法
变量名一般用小驼峰法标识,就是除第一个单词外,其他单词的首字母都大写:
string myRealName; //我真实的名字 -
大驼峰法
函数名、类名一般使用大驼峰法标识,就是每一个单词的首字母都大写:
void AddStudentScore(); //学生分数相加函数
尽管这些命名方法看起来很麻烦,且并没有实质性作用,但当我们以后开发大型项目涉及到诸多变量的时候,这些命名方法可以帮助我们记忆、区分和正确引用这些变量
结语
写这么一段长篇大论真是有点坐牢,耗费了我许多时间,很多地方修修又改改,对书上的内容更是精益求精,去其糟粕。很多段代码出现了不少的报错,但这在程序开发中是不可或缺的,于是我一边问chatgpt一边上网查阅资料,其中例如【VS】LNK2019 无法解析的外部符号 main,函数 “int __cdecl invoke_main(void)“ (? invoke_main@@YAHXZ) 中引用了该符号函数 “int __cdecl invoke_main(void)” (?invoke_main@@-CSDN博客
上述链接用于解决VS2022中的LNK2019报错。此外,还出现了很多数据类型的报错,有一次报错使我甚至将VS2022重装了一次,不过经过我的不懈努力,这些问题都得到了有效的解决
通过此次对于各种函数的学习,我对于字符串指针,缓冲区安全问题等都得到了更深更全面的领悟,同时也弥补了许多我之前因未好好学习所留下的短板,也距离编程实现完整的程序更进一步
同时,作为一名逆向工程爱好者,我将许多上述代码所编译出来的二进制可执行文件通过IDA静态分析了一遍,发现许多字符串在内存空间中的存放更加杂乱了,但却并不影响程序的正常运行。换句话说,程序的安全性确实得到了一定程度的提升,今后我会尽可能根据从各种地方学到的有关程序开发的知识融入CTF逆向工程的赛题之中,使赛题更加真实
作为一篇1.7w个字符左右的文章,我自己都没有什么耐心写下去,更别说将其读完了,这必定是一个枯燥无味的过程。但它可以为我在个人知识库中提供十分方便的查阅,学习新知识本该如此。
下一节开始我们将重回WindowsAPI的窗口编程实现,重新打开Windows程序设计之门!

















 4595
4595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









