







 本文介绍了如何使用Python3结合Selenium3和openpyxl库爬取2021年热门歌曲信息,并将其存储到Excel表格中。首先通过pip安装openpyxl,然后利用Selenium模拟浏览器滚动抓取网页内容,最后使用openpyxl处理数据并设置自适应列宽保存到Excel文件。文章还提供了正则表达式的使用说明,适合Python初学者参考。
本文介绍了如何使用Python3结合Selenium3和openpyxl库爬取2021年热门歌曲信息,并将其存储到Excel表格中。首先通过pip安装openpyxl,然后利用Selenium模拟浏览器滚动抓取网页内容,最后使用openpyxl处理数据并设置自适应列宽保存到Excel文件。文章还提供了正则表达式的使用说明,适合Python初学者参考。
Python3+Selenium3+openpyxl 爬取网站信息并保存到excel
前言
提示:以下是本人小白自行研究的成果,仅供参考
一、openpyxl安装
cmd 输入 pip3 install openpyxl
pip3 install openpyxl
这个可能慢点,也可以使用豆瓣源或者清华大学源下载
# 豆瓣
pip3 install openpyxl -i https://pypi.douban.com/simple
# 清华大学
pip3 install openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple
看到Successfully就表示成功了
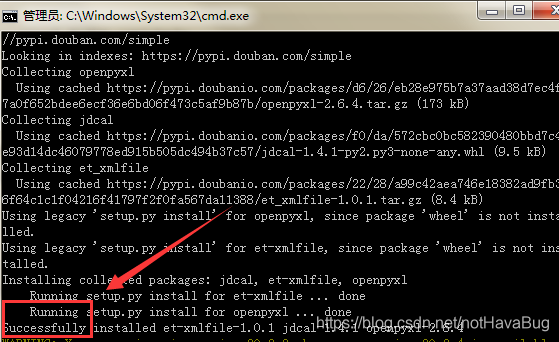
二、读取2021年最火歌曲并保存到excel
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import time
import re
from selenium import webdriver
from openpyxl import Workbook
from openpyxl.utils import get_column_letter
'''
读取2021年最火歌曲,并保存到excel
'''
num0 = 1
num1 = 1
maxlen1 = 1
maxlen2 = 1
workbook = Workbook()
sheetsh = workbook.active
sheetsh.title = '2021最火歌曲'
sheetsh.cell(row=1, column=1).value = '排名'
sheetsh.cell(row=1, column=2).value =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









