







Python 之 解析xml
前言
小白个人研究成果,仅供参考
这里介绍解析xml的两种方式
一、xml文档
以下是我需要解析的demo.xml文档
<collection shelf="New Arrivals">
<class className="一年级(1)班">
<code>20210001</code>
<number>30</number>
<teacher>张秀梅</teacher>
</class>
<class className="一年级(2)班">
<code>20210002</code>
<number>31</number>
<teacher>吴启秀</teacher>
</class>
<class className="一年级(3)班">
<code>20210003</code>
<number>29</number>
<teacher>杜飞飞</teacher>
</class>
</collection>
二、SAX解析
import xml.sax
import xml.dom.minidom
class ClassHealder(xml.sax.ContentHandler):
# 重写init函数
def __init__(self):
# 设置一个通用变量
self.CurrentData = ''
self.code = ''
self.number = ''
self.teacher = ''
# 重写元素开始事件
def startElement(self, tag, attributes):
# 将变量赋值给tag
self.CurrentData = tag
if tag == 'class':
print('-----------class标签-----------')
className = attributes['className']
print('movie标签的className是:%s' % className)
# 重写元素结束事件
def endElement(self, tag):
if tag == 'code':
print('班级编号:', self.code)
if tag == 'number':
print('班级人数:', self.number)
if tag == 'teacher':
print('班主任:', self.teacher)
self.CurrentData = ''
# 重写内容处理事件
def characters(self, content):
if self.CurrentData == 'code':
self.code = content
if self.CurrentData == 'number':
self.number = content
if self.CurrentData == 'teacher':
self.teacher = content
if __name__ == '__main__':
# 创建一个新的解析器对象并返回
parser = xml.sax.make_parser()
# 关闭命名空间
parser.setFeature(xml.sax.handler.feature_namespaces, 0)
# 重写 ContextHandler
Handle = ClassHealder()
parser.setContentHandler(Handle)
# 设置xml文件读取路径
parser.parse('C:\\Users\\yzzn\\Desktop\\demo.xml')
运行结果如下:

三、minidom解析
if __name__ == '__main__':
# 第二种方式,用minidom解析xml
domTree = xml.dom.minidom.parse('C:\\Users\\yzzn\\Desktop\\demo.xml')
# 获取所有元素
eles = domTree.documentElement
# 获取class元素
classTag = eles.getElementsByTagName('class')
# 遍历classTag元素
for c in classTag:
# 判断并获取属性值className
if c.hasAttribute('className'):
print('班级是:%s' % c.getAttribute('className'))
# 获取class标签里的子标签
code = c.getElementsByTagName('code')[0].childNodes[0].data
number = c.getElementsByTagName('number')[0].childNodes[0].data
teacher = c.getElementsByTagName('teacher')[0].childNodes[0].data
print('班级编号:%s,班级人数:%s,班主任:%s' % (code, number, teacher))
pass
运行结果如下:
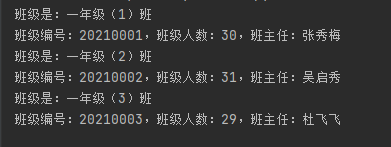
总结
又是努力向上的一天。有啥不足之处欢迎指出
本文参考自:https://www.runoob.com/python/python-xml.html















 1244
1244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









