






我们实现的每个模型都是根据某个预先指定的分布来初始化模型的参数。
初始化方案的选择在神经网络学习中起着举足轻重的作用, 它对保持数值稳定性至关重要。
1. 梯度消失和梯度爆炸
1.1. 梯度消失
曾经sigmoid函数1/(1+exp(−x))( 4.1节提到过)很流行, 因为它类似于阈值函数。 由于早期的人工神经网络受到生物神经网络的启发, 神经元要么完全激活要么完全不激活(就像生物神经元)的想法很有吸引力。 然而,它却是导致梯度消失问题的一个常见的原因,
让我们仔细看看sigmoid函数为什么会导致梯度消失?
%matplotlib inline
import torch
from d2l import torch as d2l
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.sigmoid(x)
y.backward(torch.ones_like(x))
d2l.plot(x.detach().numpy(), [y.detach().numpy(), x.grad.numpy()],
legend=['sigmoid', 'gradient'], figsize=(4.5, 2.5))
正如你所看到的,当sigmoid函数的输入很大或是很小时,它的梯度都会消失。
1.2. 梯度爆炸
相反,梯度爆炸可能同样令人烦恼。 为了更好地说明这一点,我们生成100个高斯随机矩阵,并将它们与某个初始矩阵相乘。 对于我们选择的尺度(方差σ2=1),矩阵乘积发生爆炸。 当这种情况是由于深度网络的初始化所导致时,我们没有机会让梯度下降优化器收敛。
M = torch.normal(0, 1, size=(4,4))
print('一个矩阵 \n',M)
for i in range(100):
M = torch.mm(M,torch.normal(0, 1, size=(4, 4)))
print('乘以100个矩阵后\n', M)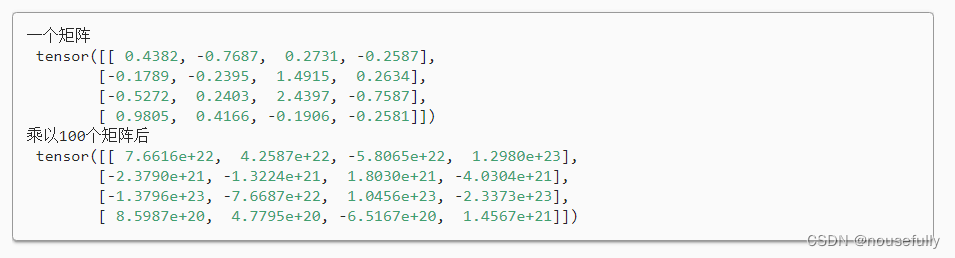
1.3. 打破对称性
神经网络设计中的另一个问题是其参数化所固有的对称性。 这样的迭代永远不会打破对称性,我们可能永远也无法实现网络的表达能力。 隐藏层的行为就好像只有一个单元。虽然小批量随机梯度下降不会打破这种对称性,但暂退法正则化可以。
2. 参数初始化
2.1. 默认初始化
我们使用正态分布来初始化权重值。如果我们不指定初始化方法, 框架将使用默认的随机初始化方法,对于中等难度的问题,这种方法通常很有效。
2.2. Xavier初始化
我们只需满足:

这就是现在标准且实用的Xavier初始化的基础,
Xavier初始化从均值为零,方差 σ2=2/nin+nout 的高斯分布中采样权重。 我们也可以利用Xavier的直觉来选择从均匀分布中抽取权重时的方差。
3. 小结
-
梯度消失和梯度爆炸是深度网络中常见的问题。在参数初始化时需要非常小心,以确保梯度和参数可以得到很好的控制。
-
需要用启发式的初始化方法来确保初始梯度既不太大也不太小。
-
ReLU激活函数缓解了梯度消失问题,这样可以加速收敛。
-
随机初始化是保证在进行优化前打破对称性的关键。
-
Xavier初始化表明,对于每一层,输出的方差不受输入数量的影响,任何梯度的方差不受输出数量的影响。















 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









