






 本文介绍了如何使用axios和cheerio库从豆瓣读书网站抓取书籍信息,包括书名、图片、出版时间等,并将数据保存到数据库,强调用于学术研究,非商业用途。
本文介绍了如何使用axios和cheerio库从豆瓣读书网站抓取书籍信息,包括书名、图片、出版时间等,并将数据保存到数据库,强调用于学术研究,非商业用途。
我们使用axios和cheerio 来抓取豆瓣读书网页的书籍的详细信息,我们可以将这些数据保存到自己的数据库来进行使用,爬取的数据仅供学术研究,禁止商用!
代码如下:
const axios = require('axios').default
const cheerio = require('cheerio')
//获取玩也源代码
const getBookHtml = async () => {
const resp = await axios.get('https://book.douban.com/latest')
//data里面就是网页的源代码
return resp.data
}
/**
* 得到网页的源代码 并进行解析出需要的部分
* 我们要多使用 async 和 await 进行修饰创建函数 因为这样的函数 就是一个promise对象
*/
const getBookLinks = async () => {
const html = await getBookHtml()
//将整个网页写入进去 然后 对齐进行选中需要的标签内容部分
const $ = cheerio.load(html)
//通过分析网页 我们得到书籍都是存储在 li标签里面 然后进行跳转拿到详情页的信息
const aElements = $('.article .chart-dashed-list li a.fleft')
//遍历拿到每一个 a 标签里面的链接
const links = aElements.map((i, ele) => {
const href = ele.attribs["href"]
return href;
}).get();
return links
}
/**
* 根据书籍的详情页地址 得到详情页的信息
* @param {*} detailUrl
*/
const getBookDetail = async (detailUrl) => {
const resp = await axios.get(detailUrl)
const $ = cheerio.load(resp.data)
//获取书名
const name = $('h1').text().trim()
//获取书籍图片
const image = $('#mainpic img').attr('src')
//获取出版时间 页数 定价
const content = $('#info .pl')
const data = content.map((i, ele) => {
if (i === 5 || i === 6 || i === 7) {
console.log(ele.next.data);
return ele.next.data
}
})
const [date, y, price] = data
return {
name,
image,
date,
y,
price
}
}
/**
* 获取所有的详情信息
*/
async function fetchAll() {
//获取每一个书籍的详情页
const links = await getBookLinks()
//遍历每一个详情页 拿到里面的详细信息
const proms = links.map((link) => {
return getBookDetail(link)
})
//因为返回的都是promise对象 这时候 我们可以使用all方法进行等待 等到所有的都返回
return Promise.all(proms)
}
fetchAll().then((books) => {
console.log(books);
})
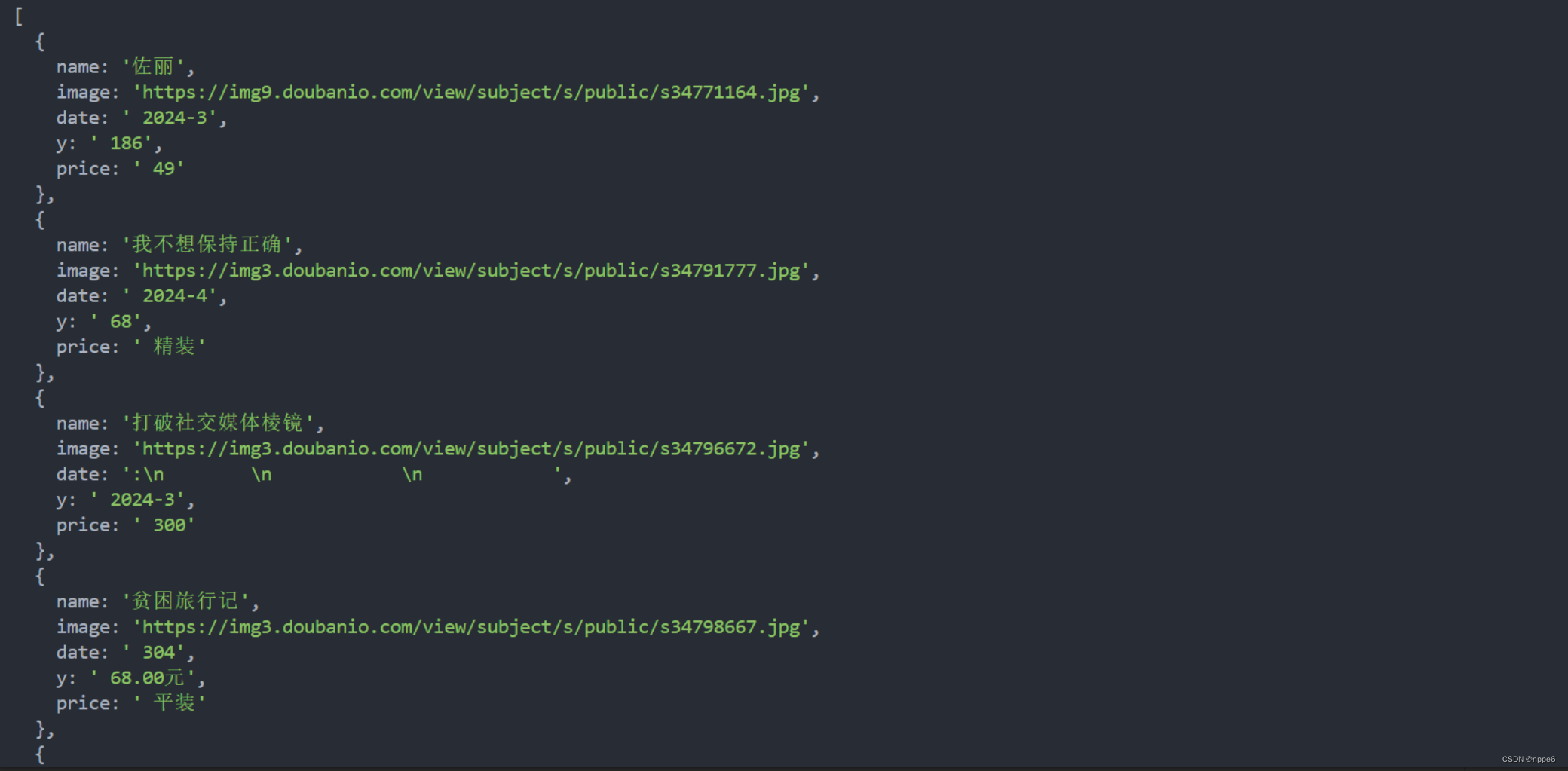
当然爬取的数据是有一些问题的,具体的完善可以根据网页自行调整啦!
















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









