






了解memcached
1、memcached是什么
Memcached 常被用来加速应用程序的处理,在这里,我们将着重于介绍将它部署于应用程序和环境中的最佳实践。这包括应该存储或不应存储哪些、如何处理数据的灵活分布以 及如何调节用来更新 memcached 和所存储数据的方法。所有的应用程序,特别是很多 web 应用程序都需要优化它们访问客户机和将信息返回至客户机的速度。可是,通常,返回的都是相同的信息。从数据源(数据库或文件系统)加载数据十分低效,若是每次想要访问该信息时都运行相同的查询,就尤显低效。要是能从内存中直接加载这些信息,可想而知速度会快多少倍。
虽然很多 web 服务器都可被配置成使用缓存发回信息,但那与大多数应用程序的动态特性无法相适。而这正是 memcached 的用武之地。它提供了一个通用的内存存储器,可保存任何东西,包括本地语言的对象,这就让您可以存储各种各样的信息并可以从诸多的应用程序和环境访问这些 信息。
memcached存储的是key/value的键值对,但是值必须是可序列化的对象(这里我说的java),还可以是json,xml,html等,这里要说明memcached集群,server端之间并不会进行相互的通信,通信完全由你的客户端来完成,你只需在客户端规定好你的key值,然后set进行,此时会有一个散列算法,来决定你key会存放在哪台server上。
最后要注意一点,memcached主要使用于存储实时性要求不是很高的信息。
2、使用memcached的场景
想象有这么一个场景,一个电子商务网站,在网站的左侧会是商品的分类,中间是商品搜索结果的列表,可以查看商品信息和商家的基本信息和相关商家的信誉度信息。
在这个场景下,因为一个商场的类别不会经常改变的。实时性不是很高,这样应该放到缓存中取的。
一般时候做法:
执行一次或者多次sql从数据库中查询全站的商品分类---->>递归形成你所需的分类tree------>>进入处理数据------->>显示到页面上。
在使用 memcached做法:
第一次显示的时候:判断memcached缓存中是否有该分类----没有----->执行一次或者多次sql从数据库中查询全站的商品分类----->放到memcached中------->>进入处理数据------->>显示到页面
第二次显示的判断memcached缓存中是否有该分类----有--->>-从memcached中取出数据-------->>进入处理数据------->>显示到页面
当这个过程首次发生时,数据将正常地从数据库或其他数据源加载,然后再存储到 memcached 内。当下一次访问此信息时,它就会从 memcached 中取出,而不是从数据库加载,节省了时间和 CPU 循环。
但是要是数据中的数据改变怎么来更新memcached中的数据呢
过程为:更新数据库中分类的信息------->找到memcached中key值,删除------>重新插入到你的memcached中就可以了
memcached 内的存储操作是原子的,所以信息的更新不会让客户机只获得部分数据;它们获得的或者是老版本,或者是新版本。
3、在使用memcached中key的约定和命名规范
这里给大家做一下总结:
第一种:一般都是公司的项目名称+字符常量+返回PO的id(或者唯一标示都可以)
第二种:可以用spring aop来拦截你要缓存的service,通过类名+方法名+参数名,来做到key值得唯一
第三种:用你的sql语句+id(或者查询条件)
其中第一种比较灵活你可以嵌入到你service的代码中,下面写一段伪代码:
- String key = "taobao"+"cat"+catAll
- Object o = getKey(key);
- if(o==null){
- //查询你的数据库操作
- cat c = catService.findAll();
- setKey(key,c);//set到memcached中
- return c;//返回结果
- }else{
- return (Cat)c;//返回结果
- }
第二种适用于分模块开发 ,因为调用的都是同一个类中的方法,但是拦截器也是回影响性能的,但是开发效率会提高的,还有就是不会破坏你的service的业务逻辑。
第三种 个人觉得不是很好 ,因为sql语句要是很长得话,也是会占用一部分内存的。
客户端语言包括 Java、Perl、PHP 等,都能串行化语言对象以便存储在 memcached 内,大家可以google一下他的客户端来做自己的实验。
4、怎么有规则弹性的使用memcached(多服务器使用)
提一个问题 ,当memcached的服务器宕掉怎么办呢?
这里要说明的一点就是缓存不是你信息的唯一来源,你不能把memcached当做你的数据库来使用,他仅仅是一个缓存,一旦宕掉,信息全无,很是可怕。此时你必须保证能从别的地方加载到你数据(如你的mysql数据库),有人可能会想到,我可以使用多台server,相互复制彼此的信息,一台宕掉 ,其他的还可以接着使用,我觉得这样的想法是很糟糕的,假设你使用了三台server 都是1g的内存,你们把信息复制到这三台上,但是你仔细想想,实际上你只拥有1g的内存可用,而你却浪费了2台server ,这似乎代价很大。
此时你可以这样解决 ,还是有3台server ,但是这三台server不会拥有相同的信息 ,也就是不会复制信息到对方的server上去,其中一台宕掉的时候,当你在次加载信息的时候,会从数据库查询,而这个信息会存储在其他两台中的任意一台server上,这样使用的好处为:同样式三台server,但是你却不像第一种那样,只拥有1g的可用内存,你现在而是3g可用,何乐而不为呢 ,只是宕掉的时候多查一次库而已,后面还是会从缓存中获取。
,只是宕掉的时候多查一次库而已,后面还是会从缓存中获取。
5、总结
到这里我想你对memcached也有了些了解,
记住memcached不是一个数据库,他只是内存,
不是信息的唯一来源,来辅助数据库操作的,来提升信息的查询速度。
在开发中怎么样规定key,这点很重要,方便以后进行维护。
以及多台server的使用中怎么才能更有效的利用你的RAM。
一、linux安装memcached
1.memcached安装需要依赖libevent ,安装版本如下:
libevent-2.0.22
memcached-1.4.25
2.使用flashFxp工具将文件上传到linux服务器,我这里上传到/usr/local目录下
3.安装libevent
首先检查libevent是否存在

表明已经存在了libevent ,将其卸载后安装我们自己的libevent,卸载命令
rpm -e --nodeps libevent-2.0.21-4.el7.x86_64
卸载成功之后,解压libevent到目录,解压命令
tar -zxvf libevent-2.0.22-stable.tar.gz
解压完成之后删除安装包,删除命令
rm -rf libevent-2.0.22-stable.tar.gz
进入libevent目录
cd /usr/local/libevent-2.0.22-stable/
./configure --prefix=/usr/libevent
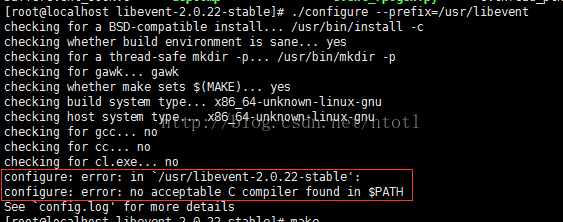
安装gcc编译器,如果没报上图所示的错误跳过,安装命令
yum -y install gcc
安装成功之后,继续执行刚才出现错误的操作,如果没有出错跳过该步骤
./configure --prefix=/usr/libevent
编译和安装
make && make install
4.安装memcached
解压安装包到目录
tar -zxvf memcached-1.4.25.tar.gz
删除安装包
rm -rf memcached-1.4.25.tar.gz
进入memcached解压目录
cd /usr/local/memcached-1.4.25/
指定memcached安装目录,并且指定libevent的安装路径
./configure --prefix=/usr/memcached --with-libevent=/usr/libevent
编译和安装
make && make install
5.安装成功
二、防火墙开放memcached的默认端口11211
编辑防火墙配置文件
vi /etc/sysconfig/iptables
然后按i键进入编辑模式 ,在文件上面添加下面代码
-A INPUT -p tcp -m state --state NEW -m tcp --dport 11211 -j ACCEPT
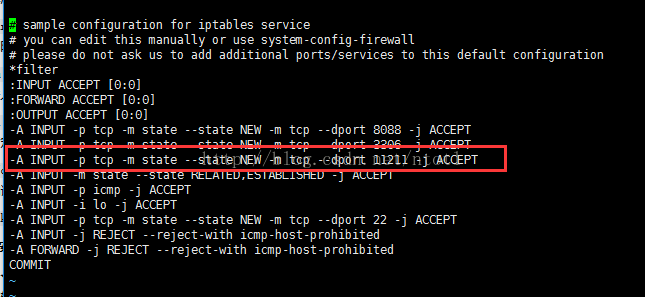
保存并退出
按下esc键,然后输入:wq 回车保存
重启防火墙
systemctl restart iptables.service
三、memcached启动和停止
我们上面指定了memcached的安装目录为/usr/memcached ,进入到这个目录去
cd /usr/memcached/bin
启动memcached
./memcached -d -m 900 -u root -l 192.168.100.186 -p 11211 -c 256 -P /tmp/memcached.pid
启动参数说明:
-d 选项是启动一个守护进程,
-m 是分配给Memcache使用的内存数量,单位是MB,默认64MB
-M return error on memory exhausted (rather than removing items)
-u 是运行Memcache的用户,如果当前为root 的话,需要使用此参数指定用户。
-l 是监听的服务器IP地址,默认为所有网卡。
-p 是设置Memcache的TCP监听的端口,最好是1024以上的端口
-c 选项是最大运行的并发连接数,默认是1024
-P 是设置保存Memcache的pid文件
-f <factor> chunk size growth factor (default: 1.25)
-I Override the size of each slab page. Adjusts max item size(1.4.2版本新增)
也可以启动多个守护进程,但是端口不能重复
kill `cat /tmp/memcached.pid`
四、linux操作memcached
4.1 连接memcached

出现这个说明需要重新安装一下telnet客户端,执行下面的安装命令
yum
yum
yum
安装完成后,再次执行连接命令
telnet 192.168.183.128 11211

这个提示的意思是按Ctrl + ] 会呼出telnet的命令行,出来telnet命令好之后就可以执行telnet命令,例如退出出telnet是quit.
常用的telnet描述
- close关闭当前连接
- logout强制退出远程用户并关闭连接
- display显示当前操作的参数
- mode试图进入命令行方式或字符方式
- open连接到某一站点
- quit退出
- telnetsend发送特殊字符
- set设置当前操作的参数
- unset复位当前操作参数
- status打印状态信息
- toggle对操作参数进行开关转换
- slc改变特殊字符的状态
- auth打开/关闭确认功能z挂起
- telnetenviron更改环境变量?显示帮助信息
4.2 memcached的一些操作命令:
存储命令
存储命令的格式:
<command name> <key> <flags> <exptime> <bytes> <data block>
参数说明:
| <command name> | 操作命令:set/add/replace |
| <key> | 缓存的键值 |
| <flags> | 客户机使用它存储关于键值对的额外信息 |
| <exptime> | 缓存过期时间 单位为秒 0 表示永远存储 |
| <bytes> | 缓存值的字节数 |
| <data block> | 数据块 |
1.添加值命令
(1) 无论如何都添加或更新的set 命令 (值不存在则添加 存在则更新) set 设置后可以用get命令获取值 也可以使用delete命令删除该值

[root@zhz jiehun]# telnet 127.0.0.1 11211
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
set test_key 0 0 3
100
STORED
get test_key
VALUE test_key 0 3
100
END
delete test_key
DELETED
get test_key
END
(2)只有数据不存在时添加值的add命令
[root@zhz jiehun]# telnet 127.0.0.1 11211 Trying 127.0.0.1... Connected to 127.0.0.1. Escape character is '^]'. add zhang 0 0 1 //第一次添加 成功 q STORED add zhang 0 0 1 //第二次添加 失败 q NOT_STORED
(3)只有数据存在时替换的replace命令
[root@zhz jiehun]# telnet 127.0.0.1 11211 Trying 127.0.0.1... Connected to 127.0.0.1. Escape character is '^]'. replace zhang_t 0 0 2 //replace 不存在的元素 失败 22 NOT_STORED add zhang_t 0 0 2 12 STORED get zhang_t VALUE zhang_t 0 2 12 END replace zhang_t 0 0 3 //replace 存在的值成功 200 STORED get zhang_t //值被替换 VALUE zhang_t 0 3 200 END
2.删除命令 delete
get zhang_t VALUE zhang_t 0 3 200 END delete zhang_t DELETED get zhang_t END
读取命令
1.get 命令 获取一个键或多个键的值 多个键以空格分开
get zhang_t zhang VALUE zhang 0 1 q END set zhang_t 0 0 3 100 STORED get zhang_t zhang VALUE zhang_t 0 3 100 VALUE zhang 0 1 q END
2 .gets 命令比get返回的值多一个数字 用来判断数据是否发生过改变
gets zhang_t zhang VALUE zhang_t 0 4 185 1000 VALUE zhang 0 1 181 q END set zhang_t 0 29 4 1000 STORED gets zhang_t zhang VALUE zhang_t 0 4 186 1000 VALUE zhang 0 1 181 q END
3. cas 的意思是 check and set 的意思,只有当最后一个参数鹤gets获取的那个用来判断数据发生改变的那个值相同时才会存储成功,否则返回 exists
gets zhang
VALUE zhang 0 3 188
dff
END
cas zhang 0 0 3 189
kjf
EXISTS
cas zhang 0 0 3 188
kjf
STORED
gets zhang
VALUE zhang 0 3 189
kjf
END
4. 自曾(incr) 自减(decr)命令
set age 0 0 2 10 STORED get age VALUE age 0 2 10 END incr age 2 12 incr age 2 14 get age VALUE age 0 2 14 END decr age 1 13 get age VALUE age 0 2 13 END
状态命令
1.stats 显示memcachd状态
stats STAT pid 1532 //进程id STAT uptime 348167 //服务运行秒数 STAT time 1372215144 //当前unix时间戳 STAT version 1.4.14 //服务器版本 STAT libevent 2.0.10-stable STAT pointer_size 32 //操作系统字大小 STAT rusage_user 3.997392 //进程累计用户时间 STAT rusage_system 2.258656 //进程累计系统时间 STAT curr_connections 5 //当前打开连接数 STAT total_connections 265 //链接总数 STAT connection_structures 7 //服务器分配的链接结构数 STAT reserved_fds 20 // STAT cmd_get 1911 //执行get命令次数 STAT cmd_set 195 //执行set命令次数 STAT cmd_flush 3 //执行flush命令次数 STAT cmd_touch 0 STAT get_hits 1708 //get命中次数 STAT get_misses 203 //get未命中次数 STAT delete_misses 11 //delete 未命中次数 STAT delete_hits 14 //delete命中次数 STAT incr_misses 0 //incr 自增命令 未命中次数 STAT incr_hits 0 //incr 命中次数 STAT decr_misses 0 //decr 自减 未命中次数 STAT decr_hits 0 //decr 命中次数 STAT cas_misses 0 //cas 未命中次数 STAT cas_hits 2 //case 命中次数 STAT cas_badval 1 //使用擦拭次数 STAT touch_hits 0 STAT touch_misses 0 STAT auth_cmds 0 STAT auth_errors 0 STAT bytes_read 164108 //读取字节数 STAT bytes_written 1520916 //写入字节书 STAT limit_maxbytes 67108864 //分配的内存数 STAT accepting_conns 1 //目前接受的连接数 STAT listen_disabled_num 0 STAT threads 4 //线程数 STAT conn_yields 0 STAT hash_power_level 16 STAT hash_bytes 262144 STAT hash_is_expanding 0 STAT expired_unfetched 4 STAT evicted_unfetched 0 STAT bytes 23995 //存储字节数 STAT curr_items 31 //item个数 STAT total_items 189 //item总数 STAT evictions 0 //为获取空间删除的item个数 STAT reclaimed 17 END
2.flush_all 清空所有项目
flush_all
OK
3.后续追加append和prepend前面插入命令
get age VALUE age 0 2 13 END append age 0 3 ERROR append age 0 0 6 111111 STORED get age VALUE age 0 8 13111111 END prepend age 0 0 6 111111 STORED get age VALUE age 0 14 11111113111111 END
该命令有一个可选的数字参数。它总是执行成功,服务器会发送 “OK\r\n” 回应。它的效果是使已经存在的项目立即失效(缺省),或在指定的时间后。此后执行取回命令,将不会有任何内容返回(除非重新存储同样的键名)。 flush_all 实际上没有立即释放项目所占用的内存,而是在随后陆续有新的项目被储存时执行(这是由memcached的懒惰检测和删除机制决定的)。
flush_all 效果是它导致所有更新时间早于 flush_all 所设定时间的项目,在被执行取回命令时命令被忽略。
memecached还有其他命令 ,这里只是平时我们工作中经常用到的一些,以此文章记录备用五、java测试
引入maven依赖
<dependency>
<groupId>com.danga</groupId>
<artifactId>java-memcached</artifactId>
<version>2.6.6</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>commons-pool</groupId>
<artifactId>commons-pool</artifactId>
<version>1.5.6</version>
</dependency>
com.danga,会无法下载对应jar,主要是由于maven repository中没有,我们需要从
https://github.com/gwhalin/Memcached-Java-Client/downloads
中下载对应版本,手动导入本地maven仓库
手动导入maven仓库的命令
mvn install:install-file -Dfile=D:/java_memcached-release_2.6.6.jar -DgroupId=com.danga
-DartifactId=java-memcached -Dversion=2.6.6 -Dpackaging=jar
这样我们仓库中就有这个jar包了
测试代码
import java.io.IOException;
import java.net.InetSocketAddress;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.danga.MemCached.MemCachedClient;
import com.danga.MemCached.SockIOPool;
public class MemcachedTest {
static{
/*
* 初始化SockIOPool,管理memcached的连接池
*/
String servers[] = {"192.168.183.128:11211"};
Integer[] weights = {3};
//获取sock连接池的实例对象
SockIOPool pool = SockIOPool.getInstance();
//设置服务器信息
pool.setServers(servers);
pool.setWeights(weights);
//设置初始连接数、最小最大连接数、最大处理时间
pool.setInitConn(5);
pool.setMinConn(5);
pool.setMaxConn(250);
pool.setMaxIdle(1000*60*60*6);
//设置主线程的睡眠时间
pool.setMaintSleep(30);
pool.setNagle(false);
pool.setSocketTO(30);
pool.setSocketConnectTO(0);
//设置Tcp的参数,连接超时等
pool.initialize();
}
public static void main(String[] args) {
MemCachedClient cache = new MemCachedClient();
//key为 "test" 永久存放值为 "123456"
cache.set("test","123456");
//获取
System.out.println(cache.get("test"));
//删除
cache.delete("test");
System.out.println(cache.get("test"));
List<Map> list = new ArrayList<Map>();
Map params1 = new HashMap();
params1.put("name", "张三");
params1.put("age", "20");
list.add(params1);
Map params2 = new HashMap();
params2.put("name", "李四");
params2.put("age", "30");
list.add(params2);
cache.set("list",list);
List<Map> result = (List<Map>) cache.get("list");
System.out.println(result);
}
}
输出结果如下:

六、知识扩展
memcached客户端如何把缓存数据分布到多台服务器上面:
Memcached客户端可以设多个memcached服务器,它是如何把数据分发到各个服务器上,而使各个服务器负载平衡的呢?
可以看看.net版中的客户端中的源码,就可以知道先看代码:
public SockIO GetSock(string key, object hashCode)
{
string hashCodeString = "<null>";
if(hashCode != null)
hashCodeString = hashCode.ToString();
if(Log.IsDebugEnabled)
{
Log.Debug(GetLocalizedString("cache socket pick").Replace("$$Key$$", key).Replace("$$HashCode$$", hashCodeString));
}
if (key == null || key.Length == 0)
{
if(Log.IsDebugEnabled)
{
Log.Debug(GetLocalizedString("null key"));
}
return null;
}
if(!_initialized)
{
if(Log.IsErrorEnabled)
{
Log.Error(GetLocalizedString("get socket from uninitialized pool"));
}
return null;
}
// if no servers return null
if(_buckets.Count == 0)
return null;
// if only one server, return it
if(_buckets.Count == 1)
return GetConnection((string)_buckets[0]);
int tries = 0;
// generate hashcode
int hv;
if(hashCode != null)
{
hv = (int)hashCode;
}
else
{
// NATIVE_HASH = 0
// OLD_COMPAT_HASH = 1
// NEW_COMPAT_HASH = 2
switch(_hashingAlgorithm)
{
case HashingAlgorithm.Native:
hv = key.GetHashCode();
break;
case HashingAlgorithm.OldCompatibleHash:
hv = OriginalHashingAlgorithm(key);
break;
case HashingAlgorithm.NewCompatibleHash:
hv = NewHashingAlgorithm(key);
break;
default:
// use the native hash as a default
hv = key.GetHashCode();
_hashingAlgorithm = HashingAlgorithm.Native;
break;
}
}
// keep trying different servers until we find one
while(tries++ <= _buckets.Count)
{
// get bucket using hashcode
// get one from factory
int bucket = hv % _buckets.Count;
if(bucket < 0)
bucket += _buckets.Count;
SockIO sock = GetConnection((string)_buckets[bucket]);
if(Log.IsDebugEnabled)
{
Log.Debug(GetLocalizedString("cache choose").Replace("$$Bucket$$", _buckets[bucket].ToString()).Replace("$$Key$$", key));
}
if(sock != null)
return sock;
// if we do not want to failover, then bail here
if(!_failover)
return null;
// if we failed to get a socket from this server
// then we try again by adding an incrementer to the
// current key and then rehashing
switch(_hashingAlgorithm)
{
case HashingAlgorithm.Native:
hv += ((string)("" + tries + key)).GetHashCode();
break;
case HashingAlgorithm.OldCompatibleHash:
hv += OriginalHashingAlgorithm("" + tries + key);
break;
case HashingAlgorithm.NewCompatibleHash:
hv += NewHashingAlgorithm("" + tries + key);
break;
default:
// use the native hash as a default
hv += ((string)("" + tries + key)).GetHashCode();
_hashingAlgorithm = HashingAlgorithm.Native;
break;
}
}
return null;
}
上面代码是代码文件SockIOPool.cs中的一个方法,从方法签名上可以看出,获取一个socket连接是根据需要缓存数据的唯一键和它的哈希值,因为缓存的数据的键值是唯一的,所以它的哈希代码也是唯一的;
再看看上面方法中的以下代码:
int bucket = hv % _buckets.Count;
if(bucket < 0)
bucket += _buckets.Count;
SockIO sock = GetConnection((string)_buckets[bucket]);
具体的选择服务器的算法是:唯一键值的哈希值与存放服务器列表中服务器(服务器地址记录不是唯一的)的数量进行模数运算来选择服务器的地址的。所以数据缓存在那台服务器取决于缓存数据的唯一键值所产生的哈希值和存放服务器列表中服务器的数量值,所以访问memcached服务的所有客户端操作数据时都必须使用同一种哈希算法和相同的服务器列表配置,否则就会或取不到数据或者重复存取数据。由于不同数据的唯一键所对应的哈希值不同,所以不同的数据就有可能分散到不同的服务器上,达到多个服务器负载平衡的目的。
如果几台服务器当中,负载能力各不同,想根据具体情况来配置各个服务器负载作用,也是可以做到的。看上面代码,可以知道程序是从_buckets中获取得服务器地址的,_buckets存放着服务器的地址信息,服务器地址在_bucket列表中并不是唯一的,它是可以有重复记录的。相同的服务器地址在_bucket重复记录越多,它被选中的机率就越大,相应负载作用也就越大。
怎么设置服务器让它发挥更大的负载作用,如下面代码:
String[] serverlist = {"192.168.1.2:11211", "192.168.1.3:11211"};
int[] weights = new int[]{5, 2};
SockIOPool pool = SockIOPool.GetInstance();
pool.SetServers(serverlist);
pool.SetWeights(weights);
pool.Initialize();
pool.SetWeights(weights)方法就是设配各个服务器负载作用的系数,系数值越大,其负载作用也就越大。如上面的例子,就设服务器192.168.1.2的负载系数为5,服务器192.168.1.3的负载系数为2,也就说服务器192.168.1.2比192.168.1.3的负载作用大。
程序中根据缓存数据中的唯一键标识的哈希值跟服务器列表中服务器记录数量求模运算来确定数据的缓存的位置的方法,算法的优点:能够把数据匀均的分散到各个服务器上数据服务器负载平衡,当然也可以通过配置使不同服务器有不同的负载作用。但也有缺点:使同类的数据过于分散,同个模块的数据都分散到不同的数据,不好统一管理和唯护;比如:现在有A、B、C、D四台服务器一起来做缓存服务器,数月后C台服务器突然死掉不可用啦,那么按算法缓存在C台服务器的数据都不可用啦,但客户端还是按原来的四台服务器的算法来取操作数据,所以分布在C服务上的数据在C服务器恢复可用之前都不可用,都必须从数据库中读取数据,并且不能添加到缓存中,因为只要缓存数据的Key不变,它还是会被计算分配到C服务器上。如果想把分配到C服务器就必须全部初始化A、B、D三台服务器上的所有数据,并把C服务器从服务器列表中移除。
如果我们能够把数据分类分布到各个服务器中,同类型的数据分布到相同的服务器;比如说,A服务器存放用户日志模块信息,B服务器存放用户相册模块信息,C服务器存放音乐模块信息,D服务器存放用户基础信息。如果C服务器不可用后,就可以更改下配置使它存放在其它服务器当中,而且并不影响其它服务器的缓存信息。
解决方法1:不同的模块使用不同memcached客户端实例,这样不同模块就可以配置不同的服务器列表,这样不同模块的数据就缓存到了不同的服务器中。这样,当某台服务器不可用后,只会影响到相应memcached客户端实例的数据,而不会影响到其它客户端实例的数据。
解决方法2:修改或添加新的算法,并在数据唯一键中添加命名空间,算法根据配置和数据唯一键中命名空间来选择不同的Socket连接,也就是服务器啦。
数据项唯一键(key)的定义:命名空间.数据项ID,就跟编程中的”命名空间”一样,经如说用户有一篇日志的ID是”999999”,那么这条篇日志的唯一键就是:Sns.UserLogs.Log.999999,当然我们存贮的时候考虑性能问题,可以用一个短的数值来代替命名空间。这样在选择Socket的时候就可以根据数据项中的唯一键来选择啦。















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









