






在此记录一下对6.824的学习过程
课程地址:6.5840 Schedule: Spring 2024
个人实现参考:https://github.com/NieYFeng/Mit-6.824-lab1-MapReduce![]() https://github.com/NieYFeng/Mit-6.824-lab1-MapReduce
https://github.com/NieYFeng/Mit-6.824-lab1-MapReduce
概述:
什么是分布式系统:多个计算机节点通过网络连接在一起,协同工作共同的任务,每个节点可以是物理上独立的计算机,但它们一起表现得像一个单一的系统
为什么要构建分布式系统:
-
可靠性:单一节点崩溃不影响全部系统
-
提高性能和处理能力:
-
负载均衡:大量请求分发
-
地理性:部署全球节点
Lab1:实现一个MapReduce分布式系统
MapReduce论文:https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/mapreduce-osdi04.pdf
初始代码仓库:
git clone git://g.csail.mit.edu/6.5840-golabs-2024
任务要求和提示都可以在课程地址中找到。
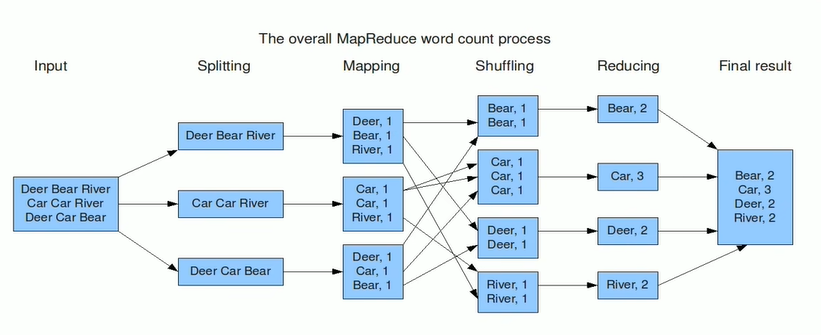
论文中提供的思路:
-
输入数据分片与程序启动:
-
将输入数据按块划分成 M 片(通常 16MB 到 64MB 每片,用户可调整),然后在集群上启动多个程序副本,其中一个是主节点,负责调度任务,其他是工作节点。
-
-
主节点分配任务:
-
主节点(Master)负责分配任务。集群中有 M 个 Map 任务和 R 个 Reduce 任务。主节点选择空闲的工作节点,分配给它们 Map 或 Reduce 任务。
-
-
Map 任务执行:
-
被分配到 Map 任务的工作节点读取输入数据块,将其解析为键/值对,然后将其传递给用户定义的 Map 函数。产生的中间键/值对会暂时缓存在内存中。
-
-
中间数据的分区与存储:
-
缓存的中间数据定期写入本地磁盘,并按 R 个分区函数进行划分。中间数据的存储位置会报告给主节点,主节点再将这些位置通知给 Reduce 任务。
-
-
Reduce 任务读取中间数据:
-
Reduce 工作节点接到主节点通知后,通过远程过程调用(RPC)从 Map 工作节点的本地磁盘读取中间数据。读取完毕后,按照中间键对数据进行排序,确保相同键的所有数据分组到一起。如果数据过大,使用外部排序。
-
-
Reduce 任务处理与输出:
-
Reduce 工作节点遍历排序后的中间数据,针对每个唯一的中间键,调用用户定义的 Reduce 函数,处理结果将追加到对应分区的最终输出文件中。
-
-
任务完成与程序返回:
-
当所有 Map 和 Reduce 任务完成后,主节点通知用户程序任务已结束,MapReduce 调用返回结果。
-
记录一下完成实验中产生的问题和思考:
实现思路:
-
1、worker中根据mrsequential和课程hints来完成map和reduce操作
-
func Worker(mapf func(string, string) []KeyValue, reducef func(string, []string) string) { for { workerId := registerWorker() go sendHeartbeat(workerId) args := TaskRequest{WorkerState: Idle, WorkerId: workerId} reply := TaskResponse{} call("Coordinator.AllocateTasks", &args, &reply) // 如果任务类型为 idle,休眠一段时间,避免频繁请求 if reply.TaskType == "idle" { time.Sleep(3 * time.Second) continue } if reply.TaskType == "map" { doMapWork(reply.FileName, mapf, reply.MapId, reply.NReduce) args = TaskRequest{WorkerState: MapFinished, WorkerId: workerId, FileName: reply.FileName} call("Coordinator.AllocateTasks", &args, &reply) } else { doReduceWork(reply.ReduceId, reducef, reply.MapCounter) args = TaskRequest{WorkerState: ReduceFinished, WorkerId: workerId, ReduceId: reply.ReduceId} call("Coordinator.AllocateTasks", &args, &reply) } } }func doMapWork(filename string, mapf func(string, string) []KeyValue, mapId int, n int) { file, err := os.Open(filename) if err != nil { log.Fatalf("cannot open %v", filename) } content, err := ioutil.ReadAll(file) if err != nil { log.Fatalf("cannot read %v", filename) } file.Close() kvs := mapf(filename, string(content)) intermediateFiles := make([]*os.File, n) encoders := make([]*json.Encoder, n) for i := 0; i < n; i++ { name := fmt.Sprintf("mr-%d-%d", mapId, i) intermediateFiles[i], err = os.Create(name) if err != nil { log.Fatalf("cannot create file %v", name) } encoders[i] = json.NewEncoder(intermediateFiles[i]) defer intermediateFiles[i].Close() } for _, kv := range kvs { reduceId := ihash(kv.Key) % n err := encoders[reduceId].Encode(&kv) if err != nil { log.Fatalf("cannot encode kv pair: %v", err) } } }func doReduceWork(reduceId int, reducef func(string, []string) string, n int) { intermediate := []KeyValue{} for i := 0; i < n; i++ { name := fmt.Sprintf("mr-%d-%d", i, reduceId) file, err := os.Open(name) if err != nil { log.Fatalf("cannot open file %v", name) } dec := json.NewDecoder(file) for { var kv KeyValue if err := dec.Decode(&kv); err != nil { if err == io.EOF { break } else { log.Fatalf("Decode error: %v", err) } } intermediate = append(intermediate, kv) } file.Close() } sort.Sort(ByKey(intermediate)) oname := fmt.Sprintf("mr-out-%d.txt", reduceId) ofile, _ := os.Create(oname) i := 0 for i < len(intermediate) { j := i + 1 for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key { j++ } values := []string{} for k := i; k < j; k++ { values = append(values, intermediate[k].Value) } output := reducef(intermediate[i].Key, values) fmt.Fprintf(ofile, "%v %v\n", intermediate[i].Key, output) i = j } } -
2、coordinator负责分发任务,主要是根据worker状态和管道任务数量分发
-
func (c *Coordinator) AllocateTasks(args *TaskRequest, reply *TaskResponse) error { workerId := args.WorkerId reply.NReduce = c.taskReduce c.mutex.Lock() defer c.mutex.Unlock() if args.WorkerState == Idle { if len(c.mapCh) > 0 { task := <-c.mapCh filename := task.FileName c.mapState[filename] = Allocated reply.TaskType = "map" reply.FileName = filename reply.MapId = task.MapId c.workerTasks[workerId] = TaskInfo{"map", filename, task.MapId} c.checkHeartBeat(workerId) return nil } else if len(c.reduceCh) != 0 && c.mapFinished == true { reduceId := <-c.reduceCh c.reduceState[reduceId] = Allocated reply.TaskType = "reduce" reply.ReduceId = reduceId reply.MapCounter = c.mapCounter c.workerTasks[workerId] = TaskInfo{"reduce", strconv.Itoa(reduceId), -1} c.checkHeartBeat(workerId) return nil } } else if args.WorkerState == MapFinished { c.mapState[args.FileName] = Finished if checkMapTask(c) { c.mapFinished = true } } else if args.WorkerState == ReduceFinished { c.reduceState[args.ReduceId] = Finished if checkReduceTask(c) { c.reduceFinished = true } } reply.TaskType = "idle" return nil } -
3、通过心跳机制检查worker是否崩溃,包括重新分发任务给管道
-
func (c *Coordinator) checkHeartBeat(workerId int) { go func() { for { time.Sleep(5 * time.Second) c.mutex.Lock() now := time.Now() if lastHeartbeat, ok := c.workerHeartbeats[workerId]; ok { // 检查心跳超时 if now.Sub(lastHeartbeat) > 10*time.Second { delete(c.workerHeartbeats, workerId) // 任务重新分配 if taskInfo, ok := c.workerTasks[workerId]; ok { value, _ := strconv.Atoi(taskInfo.Value) if taskInfo.TaskType == "map" && c.mapState[taskInfo.Value] != Finished { c.mapCh <- MapTask{taskInfo.MapId, taskInfo.Value} // 将 map 任务重新放回队列 c.mapState[taskInfo.Value] = UnAllocated } else if taskInfo.TaskType == "reduce" && c.reduceState[value] != Finished { id, err := strconv.Atoi(taskInfo.Value) if err != nil { log.Printf("Failed to convert value to int: %v", err) continue } c.reduceCh <- id // 将 reduce 任务重新放回队列 c.reduceState[id] = UnAllocated } delete(c.workerTasks, workerId) // 移除该 worker 的任务记录 } } } c.mutex.Unlock() } }() } -
4、RPC中定义coordinator和worker的交互参数
-
const ( MapFinished = iota ReduceFinished Idle ) type RegisterArgs struct { WorkerId int } type RegisterReply struct { WorkerId int } type HeartRequest struct { WorkerId int } type HeartReply struct { } type TaskRequest struct { WorkerState int WorkerId int FileName string ReduceId int } type TaskResponse struct { TaskType string FileName string ReduceId int MapId int MapCounter int NReduce int }
中间文件:
("hello", "1")
("world", "1")
("hello", "1")
("foo", "1")
("bar", "1")
("foo", "1")
处理后:
kvs = {
"hello": ["1", "1"],
"world": ["1"],
"foo": ["1", "1"],
"bar": ["1"]
}
reducef:
result = {
"hello": "2",
"world": "1",
"foo": "2",
"bar": "1"
}
问题1:管道缓冲问题,对go中的管道特性不了解导致的
问题2:dialing:dial unix /var/tmp/5840-mr-1000: connect: connection refused(这应该是访问coordinator时没反应挂起,提示里写到出现少量的这样的报错是正常的,包括我最后的结果里也有这样的报错)
问题3: crash-test中fail,原因:
if args.WorkerState == Idle {
if len(c.mapCh) > 0 {
filename := <-c.mapCh
c.mapState[filename] = Allocated
reply.TaskType = "map"
reply.FileName = filename
reply.MapId = c.generateMapId()
c.workerTasks[workerId] = TaskInfo{"map", filename}
log.Printf("mapCh length: %d", len(c.mapCh))
c.checkHeartBeat(workerId)
return nil
}
func (c *Coordinator) generateMapId() int {
c.mapCounter++
return c.mapCounter
}如果worker崩溃,mapId会被重新生成,生成的中间文件名称就会出现问题,如,原本的mr-1-0,因为worker中途崩溃导致文件没有生成,因为重新添加至队列,当再取出该任务时,重新赋值id导致中间文件名称变为mr-9-0,reduce找不到对应文件。
考虑2种解决方案:
1、原先map管道中存储的是filename,维护一个哈希表,保证filename对应正确的mapId使中间文件生成的更加正确
2、将管道中的任务换成存储一个含MapId的结构,当worker崩溃时,将该任务重新添加进管道保证正确性
最后选择第二种

实验的总结和反思:
经过多次调试之后终于将lab1结束了,在写这个lab中我认识到自己缺乏对项目总体的设计,当时的我希望赶紧上手,没有都想清楚再开始写,遇到什么问题属于是现加现解决,导致一部分代码看起来比较臃肿。















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









