






爬虫图片
本实验将利用python程序抓取网络图片,完成可以批量下载一个网站的照片。所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地。
原理
1、网络爬虫
即Web Spider,网络蜘蛛是通过网页的链接地址来寻找网页的。从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
网络爬虫的基本操作是抓取网页。
2、浏览网页过程
抓取网页的过程其实和读者平时使用浏览器浏览网页的道理是一样的。打开网页的过程其实就是浏览器作为一个浏览的“客户端”,向服务器端发送了
一次请求,把服务器端的文件“抓”到本地,再进行解释、展现。浏览器的功能是将获取到的HTML代码进行解析,然后将原始的代码转变成我们直接看到的网站页面。
URL的格式由三部分组成:
①
第一部分是协议(或称为服务方式)。
②
第二部分是存有该资源的主机IP地址(有时也包括端口号)。
③
第三部分是主机资源的具体地址,如目录和文件名等。
第一部分和第二部分用“😕/”符号隔开,
第二部分和第三部分用“/”符号隔开。
第一部分和第二部分是不可缺少的,第三部分有时可以省略。
爬虫最主要的处理对象就是URL,它根据URL地址取得所需要的文件内容,然后对它
进行进一步的处理。
因此,准确地理解URL对理解网络爬虫至关重要。
3、利用urllib2通过指定的URL抓取网页内容
在Python中,我们使用urllib2这个组件来抓取网页。
urllib2是Python的一个获取URLs(Uniform Resource Locators)的组件。
它以urlopen函数的形式提供了一个非常简单的接口。
4、HTTP的异常处理问题
当urlopen不能够处理一个response时,产生urlError。
不过通常的Python APIs异常如ValueError,TypeError等也会同时产生。
HTTPError是urlError的子类,通常在特定HTTP URLs中产生。
5、Timeout 设置(超时设置)
在Python2.6前,urllib2 的API 并没有暴露 Timeout 的设置,要设置
Timeout 值,只能更改 Socket 的全局Timeout 值。在 Python 2.6 以后,超时可以通过 urllib2.urlopen() 的 timeout 参数直接设置。
项目架构
项目包含两个文件,pet_spider.py和main_file.py。其中pet_spider.py文件定义了类PetSpider,包含3个方法分别是get_html_content下载网页源代码、get_urls获得网页图片urls、
download_images下载图片。main_file.py文件定义了主函数main,用于调用PetSpider类。
代码
根据给定的网址来获取网页详细信息,得到的html就是网页的源代码。
get_html_content函数主要功能是递归下载网页源代码。注意将byte类型转换成string类型,其中re.findall的含义是返回string中所有与pattern(正则表达式)相匹配的全部字串,返回形式为数组。
新建pet_spider.py。
首先实现获取网页源代码的函数:
#import libraries
import requests
import re
import os
#define class
class PetSpider():
def __init__(self, image_path, html_path, url_path):
self.image_path = image_path
self.html_path = html_path
self.url_path = url_path
#get webpages
def get_html_content(self, url, url_prefix):
r = requests.get(url, timeout=60)
page_content = r.content.decode('utf-8')
page_div = re.compile(r'<div class="page">(.*?)</div>', re.I|re.S|re.M).findall(page_content)
if page_div:
current_page = re.compile(r'<a class ="current" href="javascript:void\(0\);">(.*?)</a>',re.I|re.S|re.M).findall(page_div[0])
if current_page:
html_file_name = '%s/web_page_%s.txt' %(self.html_path, current_page[0])
print('downloading %s' %(html_file_name))
f = open(html_file_name, "wb")
f.write(r.content)
f.close()
else:
print('current_page not fount')
next_url = re.compile(r'<a class="next" href="(.*?)">»</a>',re.I|re.S|re.M).findall(page_div[0])
if next_url:
next_url = url_prefix + next_url[0]
self.get_html_content(next_url, url_prefix)
else:
if current_page:
print('download over')
else:
print('next_url not found')
else:
print('page_div not found')
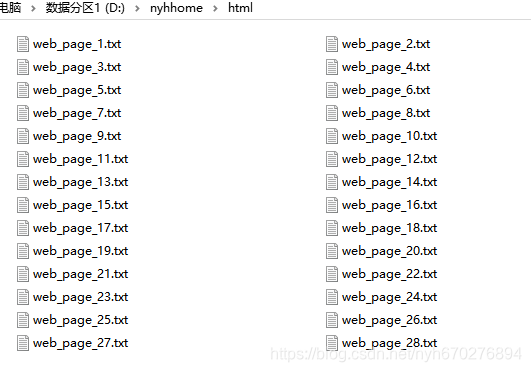
获取网页源代码后,从网页源代码中匹配过滤图片的urls,制作进度条,从文件中读出网页图片内容,最后将所有urls写入文件。
继续向pet_spider.py文件中添加如下代码:
#get urls from webpages
def get_urls(self):
url_content = ''
for _, _, file_list in os.walk(self.html_path):
pass
file_count = len(file_list)
counter = 1
for i in file_list:
file_name = '%s/%s' %(self.html_path, i)
print('extracting urls from %s. %d/%d' %(file_name, counter, file_count))
f = open(file_name, "rb")
page_content = f.read().decode('utf-8')
f.close()
urls = re.compile(r'<img src="(.*?)" />',re.I|re.S|re.M).findall(page_content)
if urls:
for i in urls:
if i.find('alt') >=0:
continue
url_content += i
url_content += '\n'
else:
print('url not found')
counter += 1
#write urls into file
f = open('%s/urls.txt' %(self.url_path), "wb")
f.write(bytes(url_content, encoding='utf8'))
f.close()
现将所有图片url过滤出来
将图片下载到本地,首先将urls字符串保存到列表中,遍历列表中的urls,将下载的图片保存在文件中。
继续向pet_spider.py文件中添加如下代码:
#download images
def download_images(self):
rows = open('%s/urls.txt' %(self.url_path)).read().split("\n")
current_image_number = 1
urls_count = len(rows)
for url in rows:
try:
#try to download the image
r = requests.get(url, timeout=60)
#save the image to disk
image_file = '%s/img_%d.jpg' %(self.image_path, current_image_number)
f = open(image_file, "wb")
f.write(r.content)
f.close()
print('download %s. %d/%d' %(image_file, current_image_number, urls_count))
current_image_number += 1
except:
print('%s has an exception. skip.' %(url))
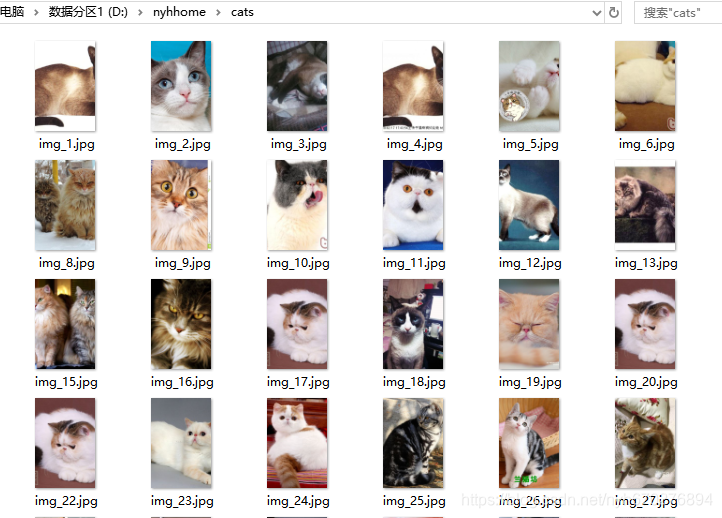
主函数
新建main_file.py文件。代码如下:
import os
from pet_spider import PetSpider
if __name__ == '__main__':
url = 'http://pet.lelezone.com/mao/'
url_prefix = 'http://pet.lelezone.com'
image_path = 'cats'
html_path = 'html'
url_path = 'url'
if not os.path.isdir(image_path):
os.makedirs(image_path)
if not os.path.isdir(url_path):
os.makedirs(html_path)
if not os.path.isdir(url_path):
os.makedirs(url_path)
pet_spider = PetSpider(image_path, html_path, url_path)
print('Download webpages.')
pet_spider.get_html_content(url,url_prefix)
print('Extract urls.')
pet_spider.get_urls()
print('Download images')
pet_spider.download_images()
最后运行主函数爬取图片。
(可以直接运行。如果无法爬取,请检查缩进,如果出现链接时间过长,可以更换以下网络,或者尝试更换源。如果还有问题,可以考虑更换一台电脑运行)

















 2637
2637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









