







原文地址:http://blog.csdn.net/steveyinger/article/details/51115731
1. 根据输出集合
- 二分类
根据输出空间,二分类的输出结果只有两种,即y={-1,1},具体的应用包括:
*信用卡申请问题:Client Data=>Accept or Deny
邮件分类问题:Email Text=>Rubbish or Not
病人生病问题:Patients Data=>Sick or Not*
还有一些其他的应用,例如广告是否盈利、答题系统对错等。 - 多元分类
多元分类的输出结果包括多种,例如饮料售卖机识别硬币问题,根据尺寸和重量可以将硬币分为四类,即最终的输出空间为y={1c,5c,10c,25c}(这里是用美金来举例,单位为美分)。二分类是特殊的多元分类问题,多元分类问题的输出空间可以扩展到y={1,2,3,……..k}。
多元分类主要应用在识别问题上。例如数字识别问题,即可以根据输入的数字1~9的特征(对称性、密度)可以将数字分为9类,最终的结果为y={1,2,….,9}。还有包括图片区分、邮件多分类问题以及其它辨识(声音、视觉)等应用。 - 回归
回归主要是用来解决预测问题。例如预测病人的病情多久可以恢复、预测股票的价格变动趋势、预测天气的变化等。其输出空间为y=R or y={lower,upper}。 - 结构学习
结构学习其实可以看作一个大的多元分类问题,只不过由于最终的分类结果太多而无法穷举。例如自然语言的识别问题,拿一句话作为示例,“I(P) love(V) ML(N)”,如果是逐词输入到分类器,自然可以根据一些特征判断出该词的词性。而如果是将整个句子扔到分类器,则最终输出的结果空间可能为{PVN,PVP,NVN……}。结构学习是有趣而复杂的。
2.根据数据标记分类
- 监督学习(Supervised Learning)
监督学习就是将所有的数据进行标记,即对每个有效的输入,都会有一个明确的输出与之对应(x(i)->y(i))。例如上述提到的硬币识别问题,监督学习类似于老师教学生根据这些硬币的特征去给出没个硬币是什么,通过这些标记的数据给出目标函数g,并根据g去标记未标记的数据。监督学习是最常见的学习方式。 - 非监督学习(Unsupervised Learning)
与监督学习恰恰相反,非监督学习的所有输入都没有标记,都是依靠机器自己想办法,又被称为聚类问题。例如根据文章去划分主题(articles=>topics)、根据客户文件划分客户群(consumer profiles=>consumer groups)等都是在未给出输入标记的情况下进行类别划分。
上图描述的是硬币分类问题,第一张图表示的是已经分好类的硬币,即属于监督学习的范畴,第二张图表示的是机器自动进行分类的结果,也就是利用的非监督学习算法。我们可以看到,非监督式的分类明显是有错误的,所以非监督学习目标分散、难以衡量。我们将非监督学习类问题定位为有挑战但是非常有用的问题。
非监督学习主要应用在分群问题,密度估算,异常探测等问题上.
分群问题:clustering{x(n)} -> cluster(x)。例如输入文章内容划分文章主题。
密度估算:traffic recording{x(n)} -> density(x)。例如输入交通肇事记录,确定事故高发地。
异常探测:network log{x(n)} -> unusual(x)。例如输入网络日志,找到系统异常。 - 半监督式学习(Semi-supervised Learning)
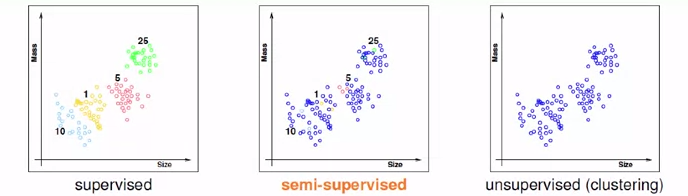
如上图,半监督式学习就是给出一部分数据进行标记,而另外的数据需要机器来完成分类。例如根据一些有标记的照片以及无标记的照片来进行面部识别,再比如根据一部分有标记的药品数据来进行药效测试。半监督式学习的特点就是由于找到标记很贵,所以采用大量的非标记的数据避免这些贵的标记。 - 增强式学习(Reinforcement Learning)
类似于(x,y’,goodness)的形式,对于输入x,没有明确的标记y与之对应,取而代之的是辅助式的y’,即根据x所做出的反应,如果反应正确,则会给出奖励,反应错误则会给出惩罚。这就像是在训练一只狗,如果狗的动作达到主人的要求,则给予奖励,如果未达到,则给予惩罚。再举两个例子:
(consumer,ad choice,ad click earning)=>ad system:在广告系统中,根据客户的数据和广告选择以及最终的点击率来进行学习。
(cards,strategy,winning amount)=>black jack agent:在21点游戏中,根据纸牌点数和相关的策略以及赢得的奖励来进行学习。


3根据学习算法分类
- 批量学习(Batch Learning)
即对大量的有标记的数据进行分类的问题。 - 有序学习(Sequence Learning)
与批量学习不同,有序学习是将数据按顺序逐一放入机器,例如垃圾邮件过滤器,首先需要观察该邮件X(i),然后使用目标函数g来预测该邮件是否为垃圾邮件,最后受到用户反馈,利用(X(i),Y(i))来更新g。 - 主动学习(Active Learning)
即通过有策略的提问进行学习以改善目标函数g,例如选择一个X(i),然后提问监督者对应的Y(i)。
4根据输入集合
- 具体的特征(concrete feature)
例如输入集合为银行客户的年龄、性别、年收入等可以具体识别的特征。 - 原始特征(raw feature)
即机器所能够识别的最原始的特征,例如输入图像数据,机器只能识别图像每个像素点的灰色值,这就是图像所包含的最原始的特征。所以我们需要将这些原始特征转化为具有实际意义的特征。 - 抽象特征(abstract feature)
例如在线评论系统的学生ID,可以根据该ID搜寻到该学生的年龄、性别等其它大量的信息,当然前提是有数据库完备的数据可以支撑。
参考资料:
Coursera台大机器学习基石














 2551
2551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









