







Vertica 23.3.0-2
一、数据类型
| Vertica数据类型 | Mysql数据类型 | 描述 |
|---|---|---|
| BOOLEAN | TINYINT(1) | 存储布尔值(True或False) |
| BYTE | TINYINT | 8位有符号整数 |
| SMALLINT | SMALLINT | 16位有符号整数 |
| INT/INTEGER | INT | 32位有符号整数 |
| BIGINT | BIGINT | 64位有符号整数 |
| FLOAT | FLOAT | 单精度浮点数 |
| DOUBLE PRESICION | DOUBLE | 双精度浮点数 |
| NUMERIC(p,s) | DECIMAL(p,s) | 固定精度和小数位数的十进制树 |
| VARCHAR | VARCHAR | 可变长度字符串 |
| CHAR | CHAR | 定长字符串 |
| DATE | DATE | 日期(年、月、日) |
| TIMESTAMP | DATETIME | 日期(年、月、日、时、分、秒) |
| BINARY | BINARY | 二进制数据 |
| VARBINARY | VARBINARY | 可变长度的二进制数据 |
| LONG VARBINARY | LONGBLOB | 长二进制数据 |
| GEOMETRY | GEOMETRY | 空间数据类型 |
二、注释
- 建表时无法指定注释,需建表后写语句指定注释
字段:COMMENT ON COLUMN schema.table_name.column_name is 'xxx';
表:COMMENT ON TABLE table_name is 'xxx';
- NOT NULL可以在建表时指定
三、索引
不支持索引,可用primary key,order by,partition by优化性能
四、分区
create table if not exists schema.test(
id int,
name varchar(20),
age int,
birthday date
)
partition by year(birthday);
五、分段(片)
-
SEGMENTED BY HASH(column_name) [ALL NODES | K]:使用哈希分段将数据均匀地分布到各个节点或指定的 K 个节点上。column_name 是用于哈希分段的列名.可以选择将数据在所有节点上分段(ALL NODES),或者指定一个固定数量的节点(K)来进行分段。
-
SEGMENTED BY [UNSEGMENTED | ALL]:使用无分段(UNSEGMENTED)或全部分段(ALL)的方式存储数据。无分段意味着数据将在整个集群中复制,并在每个节点上都有一份完整的副本。全部分段将数据均匀地分布到各个节点上。
-
SEGMENTED BY [column_name | EXPRESSION]:使用特定的列或表达式来进行分段,以实现自定义的分段逻辑。可以根据特定的业务需求和数据模型选择适当的列或表达式来进行分段。
-
SEGMENTED BY [column_name] [ON [SUB]CLUSTER cluster_name]:在指定的子集群或特定的集群上进行分段。可以根据需要将数据分布在特定的子集群或集群中。
eg:
create table if not exists schema.test(
id int,
name varchar(20),
age int,
birthday date
)
segmented by hash(id) all nodes
- 用来做hash的列最好是主键,该列不重复的数据越多,越适合做hash
- segmented by的列不要用long varbinary and long varchar columns
六、Order by
1、order by 后面插入的数据是有序的,因此一般order by的列就源于where条件后的列,例如,如果子句查询中有where x = 1 and y = 2,那么使用order by (x,y)查询的时候就会迅速定位到符合条件的数据
2、group by后面的字段,出现在order by中也可以优化查询
3、order by也不要建立在long varbinary and long varchar columns
eg:
create table if not exists schema.test(
id int,
name varchar(20),
age int,
birthday date
)
order by age
若order by 后跟多个列,不需要加(),如order by name,age
七、PROJECTION
- 在vertica中,表只是一个逻辑上的概念,其真实数据实际上是存储在一个个的projection中
- 与物化视图类似,projection将结果集存储在磁盘上,而不是在每次查询时计算它们,可以使用新数据或更新数据刷新projections
八、DBeaver连接Vertica
1、安装DBeaver
DBeaver官网
2、安装驱动
Vertica驱动官网
3、配置流程
- 点击连接按钮,选择SQL,搜Vertica,选中点下一步
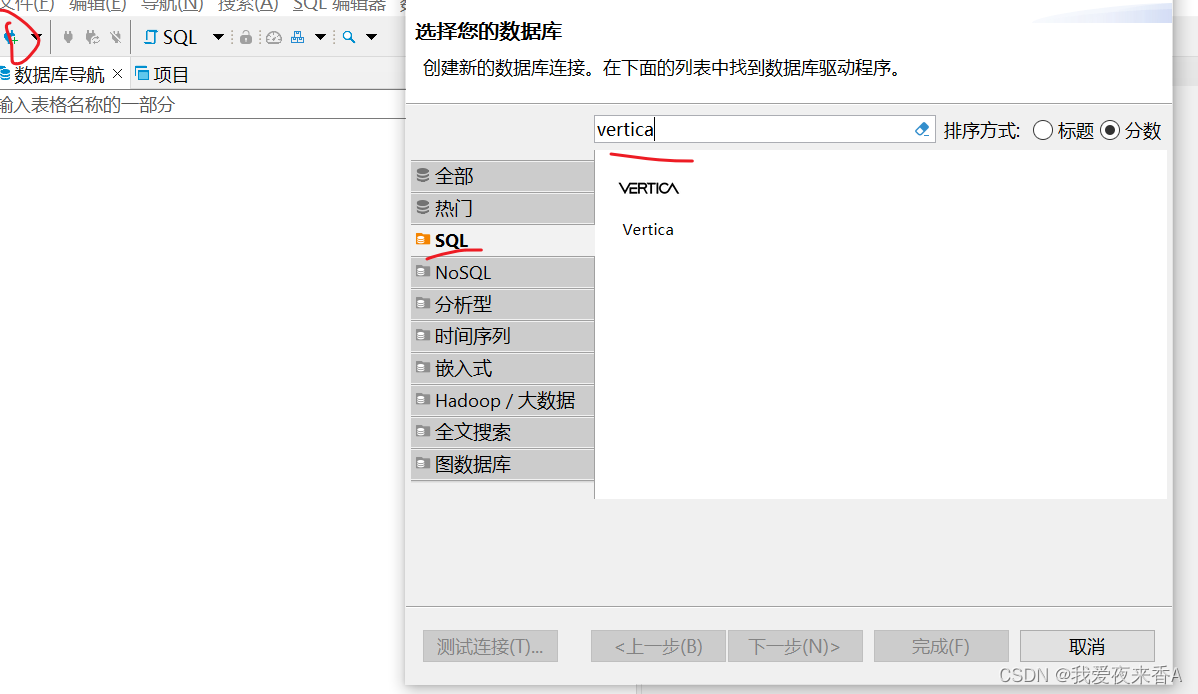
- 主机、用户名、密码、端口号等填好后,选择编辑驱动设置
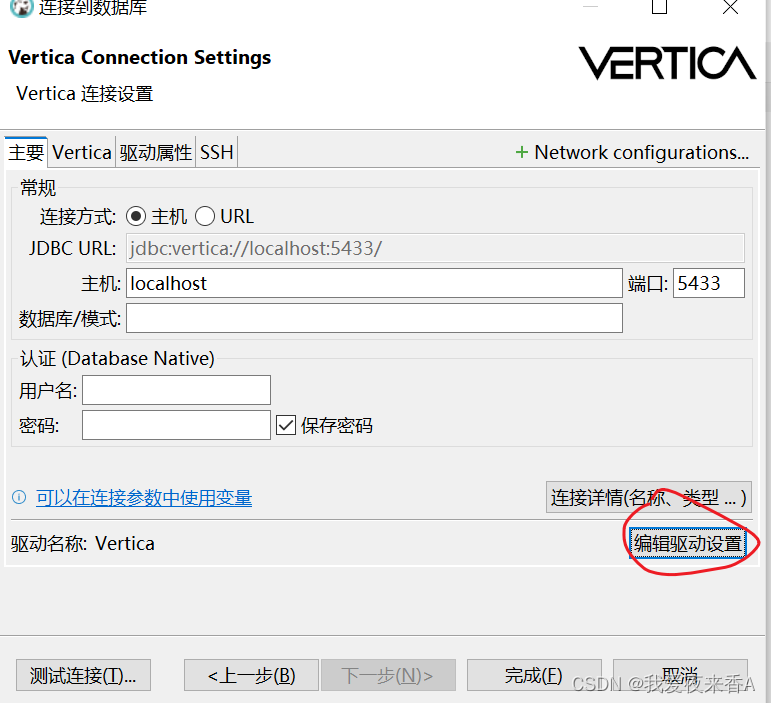
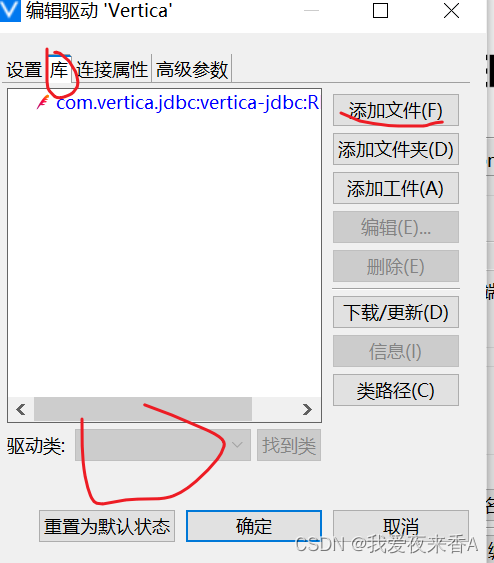
- 选择库,添加文件,找到对应的驱动jar包,点击找到类,会自动跳出刚才配置的Java类,点击确定就可以了

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











