







爬虫是什么:一段自动抓取互联网信息的程序
爬虫价值:互联网数据,为我所用
一、简单爬虫架构
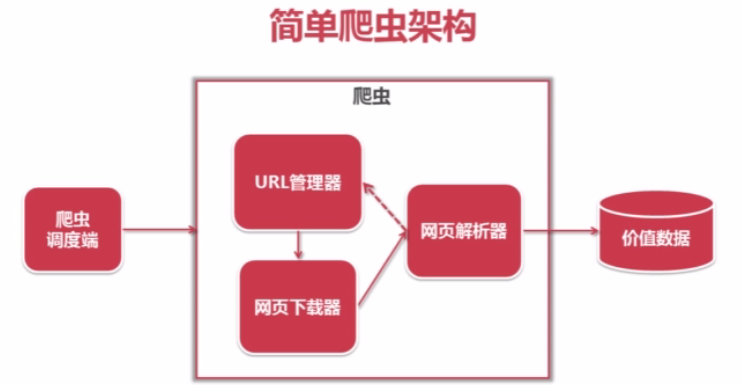
爬虫调度端:用来启动、执行、停止爬虫,或者监视爬虫中的运行情况
在爬虫程序中有三个模块URL管理器:对将要爬取的URL和已经爬取过的URL这两个数据的管理
网页下载器:将URL管理器里提供的一个URL对应的网页下载下来,存储为一个字符串,这个字符串会传送给网页解析器进行解析
网页解析器:一方面会解析出有价值的数据,另一方面,由于每一个页面都有很多指向其它页面的网页,这些URL被解析出来之后,可以补充进URL管理器
这三部门就组成了一个简单的爬虫架构,这个架构就能将互联网中所有的网页抓取下来
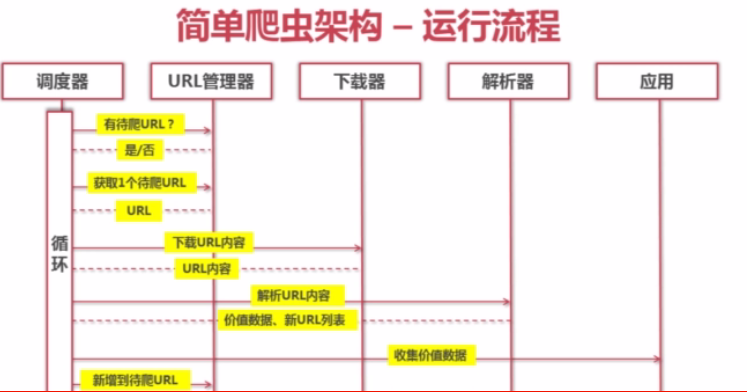
这个简单爬虫架构是怎样运行的了?
看看运行流程
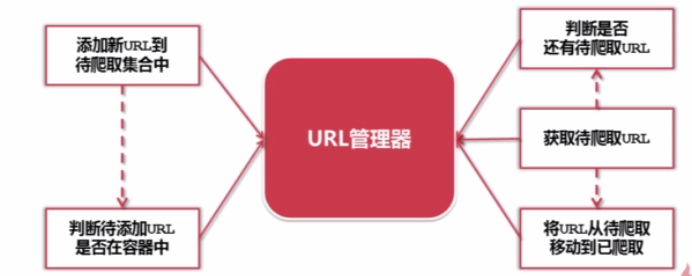
二、URL管理器和实现方法
2.1.URL管理器:管理待抓取URL集合和已抓取URL集合。
其意义是:防止重复抓取、防止循环抓取(如两个网页相互引用而形成死循环)
需要有如下最基本的功能
2.2.URL管理器实现方式:
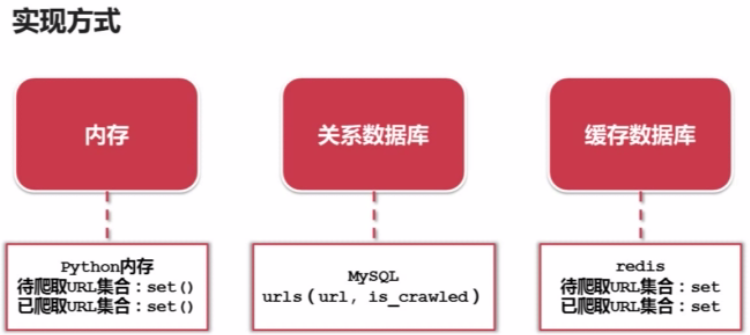
注意:set可以去除重复的URL。目前大部分公司选择缓存数据库存储抓取到 数据,因为快















 5592
5592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









