







参考代码下载github:https://github.com/changwensir/java-ee/tree/master/hibernate4

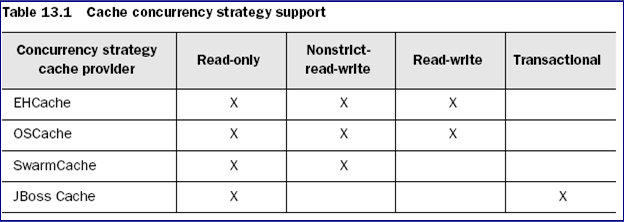
二级缓存的并发访问策略
管理 Hibernate的二级缓存
1、类级别的二级缓存
需要添加ehcache.jar包,加入ehcache.xml默认配置文件到当前 WEB 应用的类路径下
在cfg.xml里配置
<!-- 启用二级缓存 -->
<property name="cache.use_second_level_cache">true</property>
<!-- 配置使用的二级缓存的产品 -->
<property name="hibernate.cache.region.factory_class">org.hibernate.cache.ehcache.EhCacheRegionFactory</property>
<!--配置对哪些类使用 hibernate 的二级缓存-->
<class-cache usage="read-write" class="com.atguigu.hibernate.entities.Employee"/>
@Test
public void testHibernateSecondLevelCache(){
Employee employee = (Employee) session.get(Employee.class, 100);
System.out.println(employee.getName());
transaction.commit();
session.close();
session = sessionFactory.openSession();
transaction = session.beginTransaction();
Employee employee2 = (Employee) session.get(Employee.class, 100);
System.out.println(employee2.getName());
}2、集合级别的二级缓存
cfg.xml配置如下<class-cache usage="read-write" class="com.atguigu.hibernate.entities.Employee"/>
<class-cache usage="read-write" class="com.atguigu.hibernate.entities.Department"/>
<!--departmet里的集合也要设置-->
<collection-cache usage="read-write" collection="com.atguigu.hibernate.entities.Department.emps"/><!--在类下面配置是对类设置二级缓存-->
<cache usage="read-write"/>
<!--在这里设置是对类里的集合设置二级缓存-->
<set name="emps" table="GG_EMPLOYEE" inverse="true" lazy="true">
<cache usage="read-write"/>
<key>
<column name="DEPT_ID" />
</key>
<one-to-many class="com.atguigu.hibernate.entities.Employee" />
</set> @Test
public void testCollectionSecondLevelCache(){
Department dept = (Department) session.get(Department.class, 80);
System.out.println(dept.getName());
System.out.println(dept.getEmps().size());
transaction.commit();
session.close();
session = sessionFactory.openSession();
transaction = session.beginTransaction();
Department dept2 = (Department) session.get(Department.class, 80);
System.out.println(dept2.getName());
System.out.println(dept2.getEmps().size());
}3、ehcache.xml与查询缓存
<ehcache>
<!-- Sets the path to the directory where cache .data files are created.
If the path is a Java System Property it is replaced by
its value in the running VM.
The following properties are translated:
user.home - User's home directory
user.dir - User's current working directory
java.io.tmpdir - Default temp file path -->
<!--
指定一个目录:当 EHCache 把数据写到硬盘上时, 将把数据写到这个目录下.
-->
<diskStore path="d:\\tempDirectory"/>
<!--Default Cache configuration. These will applied to caches programmatically created through
the CacheManager.
The following attributes are required for defaultCache:
maxInMemory - Sets the maximum number of objects that will be created in memory
eternal - Sets whether elements are eternal. If eternal, timeouts are ignored and the element
is never expired.
timeToIdleSeconds - Sets the time to idle for an element before it expires. Is only used
if the element is not eternal. Idle time is now - last accessed time
timeToLiveSeconds - Sets the time to live for an element before it expires. Is only used
if the element is not eternal. TTL is now - creation time
overflowToDisk - Sets whether elements can overflow to disk when the in-memory cache
has reached the maxInMemory limit.
-->
<!--
设置缓存的默认数据过期策略
-->
<defaultCache
maxElementsInMemory="10000"
eternal="false"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
overflowToDisk="true"
/>
<!--<cache>
设定具体的命名缓存的数据过期策略。每个命名缓存代表一个缓存区域
缓存区域(region):一个具有名称的缓存块,可以给每一个缓存块设置不同的缓存策略。
如果没有设置任何的缓存区域,则所有被缓存的对象,都将使用默认的缓存策略。即:<defaultCache.../>
Hibernate 在不同的缓存区域保存不同的类/集合。
对于类而言,区域的名称是类名。如:com.atguigu.domain.Customer
对于集合而言,区域的名称是类名加属性名。如com.atguigu.domain.Customer.orders
-->
<!--
name: 设置缓存的名字,它的取值为类的全限定名或类的集合的名字
maxElementsInMemory: 设置基于内存的缓存中可存放的对象最大数目
eternal: 设置对象是否为永久的, true表示永不过期,
此时将忽略timeToIdleSeconds 和 timeToLiveSeconds属性; 默认值是false
timeToIdleSeconds:设置对象空闲最长时间,以秒为单位, 超过这个时间,对象过期。
当对象过期时,EHCache会把它从缓存中清除。如果此值为0,表示对象可以无限期地处于空闲状态。
timeToLiveSeconds:设置对象生存最长时间,超过这个时间,对象过期。
如果此值为0,表示对象可以无限期地存在于缓存中. 该属性值必须大于或等于 timeToIdleSeconds 属性值
overflowToDisk:设置基于内存的缓存中的对象数目达到上限后,是否把溢出的对象写到基于硬盘的缓存中
-->
<cache name="com.atguigu.hibernate.entities.Employee"
maxElementsInMemory="1"
eternal="false"
timeToIdleSeconds="300"
timeToLiveSeconds="600"
overflowToDisk="true"
/>
<cache name="com.changwen.hibernate.entities.Department.emps"
maxElementsInMemory="1000"
eternal="true"
timeToIdleSeconds="0"
timeToLiveSeconds="0"
overflowToDisk="false"
/>
</ehcache><!-- 配置启用查询缓存 -->
<property name="cache.use_query_cache">true</property> @Test
public void testQueryCache(){
Query query = session.createQuery("FROM Employee");
query.setCacheable(true); // 设置query为可缓存的
List<Employee> emps = query.list();
System.out.println(emps.size());
emps = query.list();
System.out.println(emps.size());
Criteria criteria = session.createCriteria(Employee.class);
criteria.setCacheable(true);
}查询缓存: 默认情况下, 设置的缓存对 HQL 及 QBC 查询时无效的, 但可以通过以下方式使其是有效的
I. 在 hibernate 配置文件中声明开启查询缓存
<property name="cache.use_query_cache">true</property>
II. 调用 Query 或 Criteria 的 setCacheable(true) 方法
III. 查询缓存依赖于二级缓存
2).查询缓存
对于经常使用的查询语句, 如果启用了查询缓存, 当第一次执行查询语句时, Hibernate 会把查询结果存放在查询缓存中. 以后再次执行该查询语句时, 只需从缓存中获得查询结果, 从而提高查询性能
查询缓存使用于如下场合:
- 应用程序运行时经常使用查询语句
- 很少对与查询语句检索到的数据进行插入, 删除和更新操作
启用查询缓存的步骤
- 配置二级缓存, 因为查询缓存依赖于二级缓存
- 在 hibernate 配置文件中启用查询缓存
- 对于希望启用查询缓存的查询语句, 调用 Query 的 setCacheable() 方法
1-3.时间戳缓存区域
时间戳缓存区域存放了对于查询结果相关的表进行插入, 更新或删除操作的时间戳. Hibernate 通过时间戳缓存区域来判断被缓存的查询结果是否过期, 其运行过程如下:
- T1 时刻执行查询操作, 把查询结果存放在 QueryCache 区域, 记录该区域的时间戳为 T1
- T2 时刻对查询结果相关的表进行更新操作, Hibernate 把 T2 时刻存放在 UpdateTimestampCache 区域.
- T3 时刻执行查询结果前, 先比较 QueryCache 区域的时间戳和 UpdateTimestampCache 区域的时间戳, 若 T2 >T1, 那么就丢弃原先存放在 QueryCache 区域的查询结果, 重新到数据库中查询数据, 再把结果存放到 QueryCache 区域; 若 T2 < T1, 直接从 QueryCache 中获得查询结果
@Test
public void testUpdateTimeStampCache(){
Query query = session.createQuery("FROM Employee");
query.setCacheable(true);
List<Employee> emps = query.list();
System.out.println(emps.size());
Employee employee = (Employee) session.get(Employee.class, 100);
employee.setSalary(30000);
emps = query.list();
System.out.println(emps.size());
}1-4.Query 接口的 iterate() 方法
Query 接口的 iterator() 方法,跟二级缓存紧密些
- 同 list() 一样也能执行查询操作
- list() 方法执行的 SQL 语句包含实体类对应的数据表的所有字段
- Iterator() 方法执行的SQL 语句中仅包含实体类对应的数据表的 ID 字段
- 当遍历访问结果集时, 该方法先到 Session 缓存及二级缓存中查看是否存在特定 OID 的对象, 如果存在, 就直接返回该对象, 如果不存在该对象就通过相应的 SQL Select 语句到数据库中加载特定的实体对象
大多数情况下, 应考虑使用 list() 方法执行查询操作. iterator() 方法仅在满足以下条件的场合, 可以稍微提高查询性能:
- 要查询的数据表中包含大量字段
- 启用了二级缓存, 且二级缓存中可能已经包含了待查询的对象
@Test
public void testQueryIterate(){
Department dept = (Department) session.get(Department.class, 70);
System.out.println(dept.getName());
System.out.println(dept.getEmps().size());
Query query = session.createQuery("FROM Employee e WHERE e.dept.id = 80");
// List<Employee> emps = query.list();
// System.out.println(emps.size());
Iterator<Employee> empIt = query.iterate();
while(empIt.hasNext()){
System.out.println(empIt.next().getName());
}
}














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









