









实验环境:
Hadoop 1.0.4
Ubuntu 12.04 RTS – amd64
Java-7-openjdk
Master:
Lenovo Y480n-i5-3210
Slave:
I5 750 + 4g RAM
安装单节点Hadoop
如要安装Hadoop集群,请在安装前先安装个必须软件:
$sudo apt-get install ssh假设你已经下好了Hadoop的安装包,解压缩。
注意,如果是需要在后面继续安装hadoop集群,所有节点的hadoop安装路径必须完全一致,这里我使用的是/home/hadoop。/home/hadoop这个路径默认情况下必须要有sudo权限才能做出修改,故后面的文件操作指令前都会加入sudo指令。
然后安装JDK
Java6:
$sudo apt-get install openjdk-6-jdk$sudo apt-get install openjdk-7-jdk注:如果需要继续安装集群,各结点所使用的Java版本必须一致
然后
$cd /usr/lib/jvm
$ls

应该就会看到刚刚所安装的jdk文件夹,如java-7-openjdk-amd64,其中amd64意味着这个是64位版本,如果本机使用的是32位的Linux,此后缀将变为i386。部分用户的jvm文件夹下可能不止一个jdk文件夹,最好点进去看一下里面的内容齐不齐全,以此来判断这个是不是刚刚安装的jdk。现在先记住这个路径/usr/lib/jvm/java-7-openjdk-amd64,后面会用到。
现在进入刚刚解压的hadoop文件夹
$cd /home/hadoop需要首先编辑一下conf/hadoop-env.sh
$sudo vim hadoop-env.sh可以看到文件内部有大量的注释,其中有一行是JAVA_HOME的设置代码,取消注释,写下如下代码
Export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
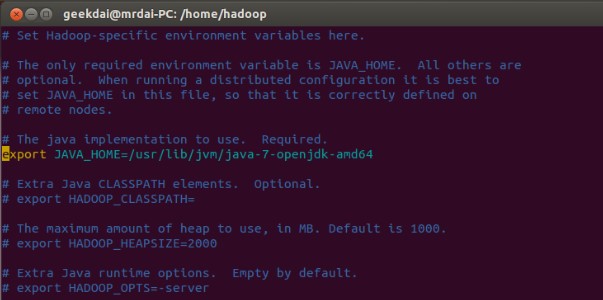
这里是将环境变量$JAVA_HOME设置为刚刚安装的jdk文件夹
然后打开终端输入如下代码
$export HADOOP_INSTALL=/home/Hadoop
$export PATH=$PATH:$HADOOP_INSTALL/bin
这里是设置了Hadoop安装路径的环境变量,同时将其加入PATH,这样就可以运行hadoop了,可在任意路径下输入以下代码验证Hadoop的安装
$hadoop version

至此,hadoop单节点模式安装完毕,可以跑跑Hadoop自带的wordcount案例来测试一下,具体的测试步骤将在本教程最后一部分里详细介绍
配置Hadoop集群
假设要架设的Hadoop集群包含以下两个节点:
Mrdai-Laptop IP:192.168.1.105
Mrdai-PC IP:192.168.1.104
其中Mrdai-Laptop为master,Mrdai-PC为slave。同时假设这两台计算机均已安装好相同的hadoop,JDK与ssh。
配置Hosts
首先修改每台计算机的Hosts文件
$sudo vim /etc/hosts192.168.1.105 mrdai-Laptop
192.168.1.104 mrdai-PC注意,修改hosts时,IP段的IP别名(即上面的mrdai-Laptop和mrdai-PC)必须与该机的机器名一致。如果不记得机器名可以先打开终端,看到

其中@号前的mrdai为当前用户名,@号后的mrdai-Laptop为当前机器名。
同时,最好把所有节点hosts内localhost一项删去,以免以后发生一些错误
创建Hadoop用户
要让master能够连接上slave,首先每台slave内必须先新建一个用户名与master机root用户用户名一致的用户
首先先创建一个hadoop用户组
$sudo addgroup hadoop然后创建一个名为hadoop-master的用户,归于hadoop用户组下。注意该用户名必须与master机root用户的用户名一致。
$sudo adduser --ingroup hadoop mrdai创建新用户时会需要输入新用户密码及用户信息。用户密码不需要与本机root用户密码一致,只要确保master知道就好。用户信息可以为空白。

然后再给该用户组增添sudo权限
$sudo vim /etc/sudoers在%admin ALL=(ALL) ALL下面添加一行
%hadoop ALL=(ALL) ALL
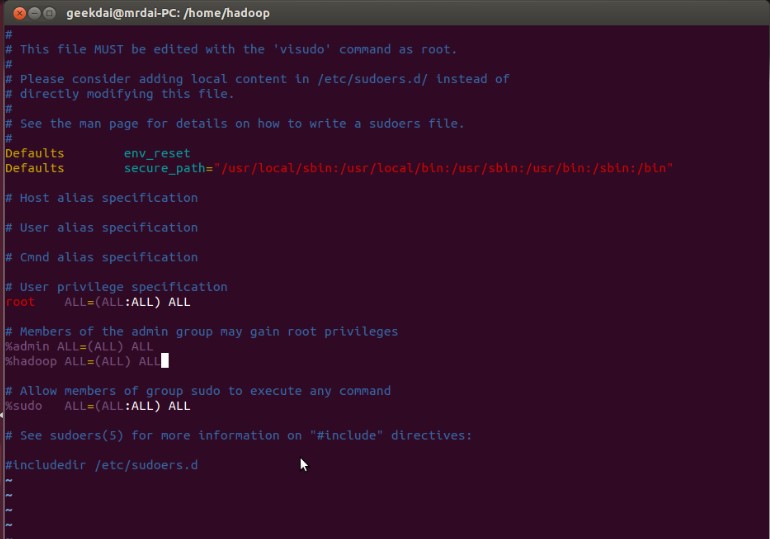
OK,Hadoop用户创建完毕
然后需要将slave机上的hadoop文件夹的所有者设置为这个新用户,输入以下指令
$sudo chown –R mrdai:hadoop /home/hadoop
$sudo chmod –R 755 /home/hadoop然后输入$ls –l,在出现的表格的第三列可以看到文件所有者已被修改为新用户mrdai
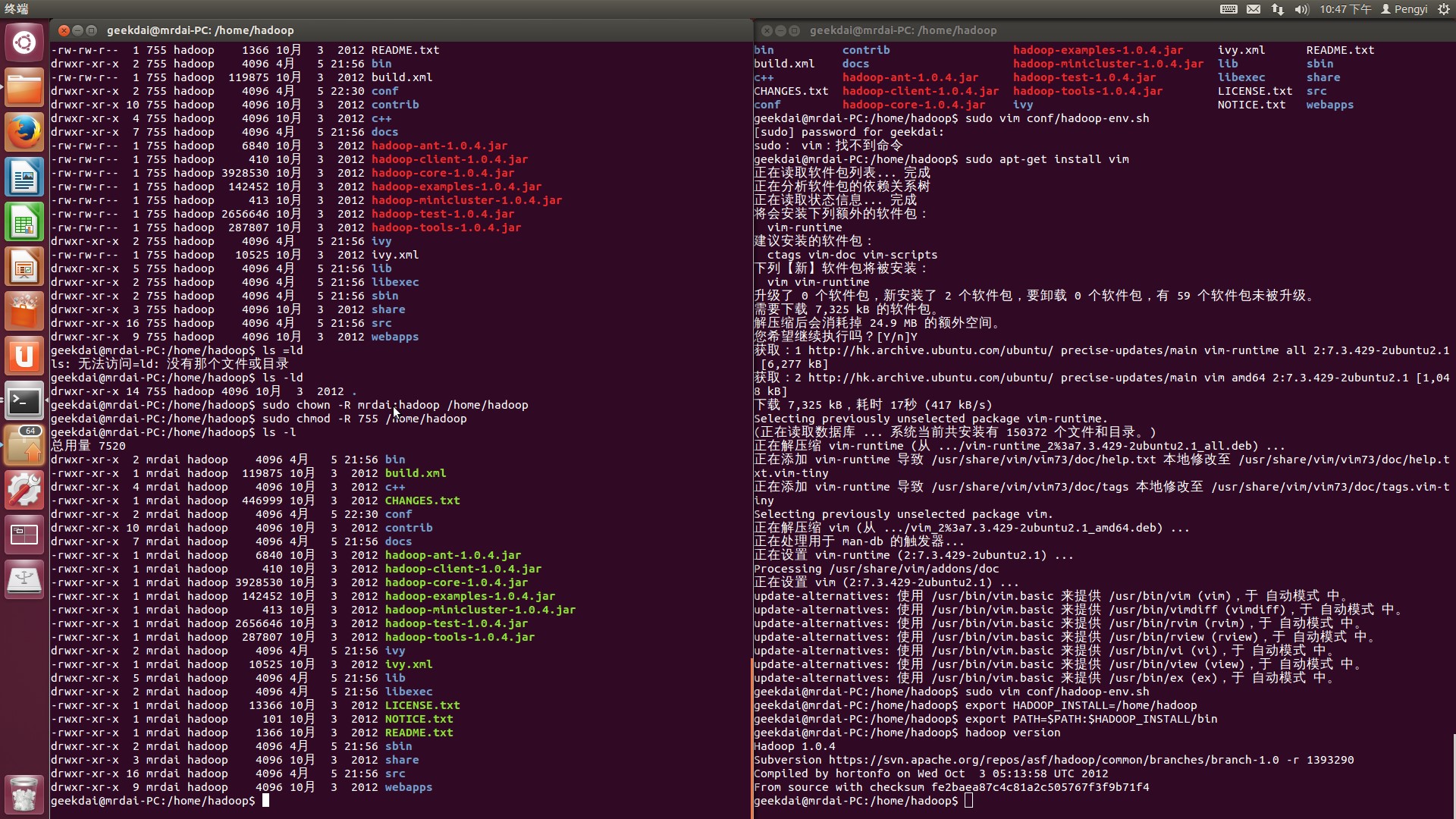
配置SSH
在完成上面两步后,master机应该是可以通过ssh连接到任意slave机了,在ssh前不妨可以见ping一下,看看有没有问题。然后在master机打开终端输入如下指令进入mrdai-PC机:
$ssh mrdai-PC然后会提示输入密码,输入的即为刚刚在mrdai-PC机新创建的用户的密码,验证通过后便可以由master机控制mrdai-PC机。
我们在两台机器内输入以下指令生成各自的SSH密钥
$ssh-keygen –t rsa –f ~/.ssh/id_rsa密钥将位于路径 ~/.ssh下
然后将密钥复制
$cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
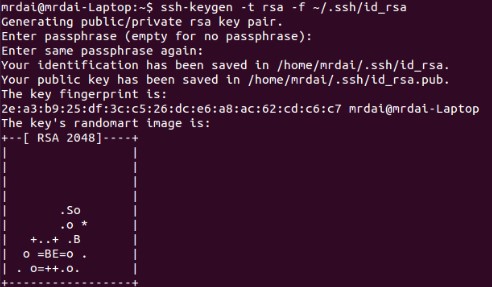
然后回到master机,输入以下指令
$ssh-copy-id –i $HOME/.ssh/id_rsa.pub mrdai@mrdai-PC执行完毕后在master机上输入
$ssh mrdai-PC如果不再提示输入密码,则设置成功。
在master机内设置集群成员名单
进入master机的/home/hadoop,更新conf/masters文件如下
mrdai-Laptop更新conf/slaves文件如下:
mrdai-Laptop
mrdai-PC
配置各机XML相关属性
进入各节点机内,更新下列三个xml文件的configuration标签内的值:
<!-- In: conf/core-site.xml -->
<property>
<name>fs.default.name</name>
<value>hdfs://mrdai-Laptop:9000</value> ------定位文件系统的NameNode
</property>
<!-- In: conf/mapred-site.xml -->
<property>
<name>mapred.job.tracker</name>
<value>mrdai-Laptop:9001</value> --------定位JobTrecker所在主节点
</property>
<!-- In: conf/hdfs-site.xml -->
<property>
<name>dfs.replication</name>
<value>2</value> -----------增大HDFS备份参数
</property>
注意这里dfs.replication的值即为文件在hdfs内所做副本数,像图中设置为2,那么每次上传新文件就会在hdfs上产生两个副本数据块(尽管使用ls指令只会显示一个)
至此,集群各节点间的准备工作全部完成
开始运行集群
第一次运行集群时,必须先对master机的namenode进行格式化,格式化之前最好现在所有机器上清空hdfs/data和hdfs/name以及/tmp下与hadoop有关的所有文件,以免造成冲突
在master机上运行:
$bin/Hadoop namenode –format$bin/start-all.sh可在master和slave机上使用jps命令,查看开启的daemons进程,如果能看到Hadoop的相关进程,代表Hadoop集群构建成功。
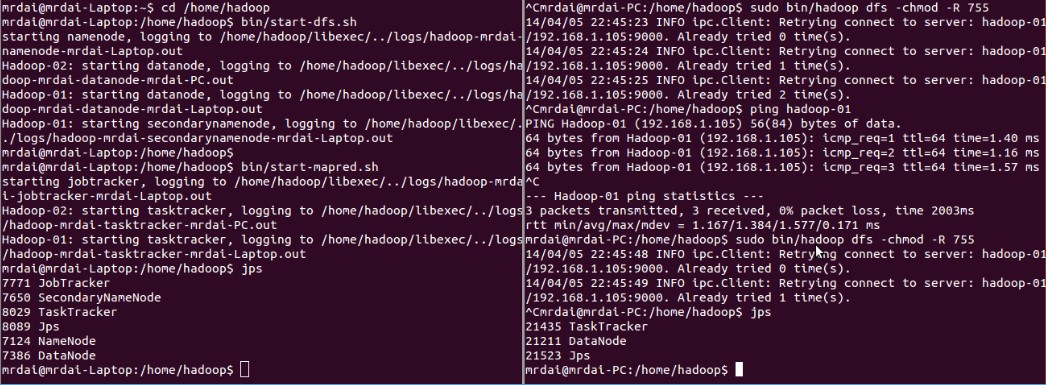
注:开启daemons时,master机可能收到各种错误报告。仔细阅读错误报告,便能大致确定是哪台机出了什么问题。如果是频繁提示需要输入密码,那就说明SSH设置有问题,Hadoop本身问题不大。Bin文件夹下除了启动daemons的脚本,也有关闭daemons的脚本,只需要在master机执行对应的脚本便能在整个集群内关闭指定的功能。
测试集群
这里利用的是Hadoop自带的wordcount方法来测试一下Hadoop系统的安装情况,任何模式下的hadoop均可使用该测试方法,指令完全相同
首先在dfs中创建input目录:
$bin/Hadoop dfs –mkdir input将conf中的文件拷贝到dfs中的input,作为后面执行wordcount的输入:
$bin/hadboop dfs –copyFromLocal conf/* input$bin/hadoop jar hadoop-examples-1.0.4.jar wordcount input output注:此处的hadoop-examples-1.0.4.jar在不同版本的hadoop里名字可能不完全相似,最好先在hadoop安装文件夹下看一下,或者直接用hadoop-examples*.jar代替

右侧可以看到,Slave机mrdai-PC也受到master机控制正在进行运算。
显示输出结果文件:
$bin/hadoop dfs –cat output/*如果能完整跑下来,那说明Hadoop已经成功安装,可以开始各位的开发之旅了。祝好运!















 3028
3028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









