







并行与并发:
多个cpu同步处理各自的事情,就是并行。
只有一个cpu,执行到耗时的代码需要切换做另一个事情,这就是并发
1.普通版:
# 复制文件夹
# 1.创建一个文件夹
# 2. 要被复制的文件夹进行遍历
# 3. 循环复制到别一个文件夹中
import os
from shutil import rmtree
def copy_file(file_before, file_after):
"""复制文件"""
# 1.读取文件内容
with open(file_before, 'rb') as f:
content = f.read()
# 2.新文件中写入内容
with open(file_after, 'wb') as f:
f.write(content)
def main():
"""复制文件夹"""
# 创建文件 夹
# 创建文件 夹前判断是否存在,如果存在,那么删除
if os.path.exists("./python14_备份"): # 这个判断是否存在
# 删除夹文件夹
rmtree("./python14_备份") # 删除文件夹,是文件夹中有内容的
# 删除以后创建
os.mkdir("./python14_备份")
# 得到文件夹的内容
files_list = os.listdir("./python14")
# 循环复制到别一个文件
for file_name in files_list:
# 复制文件
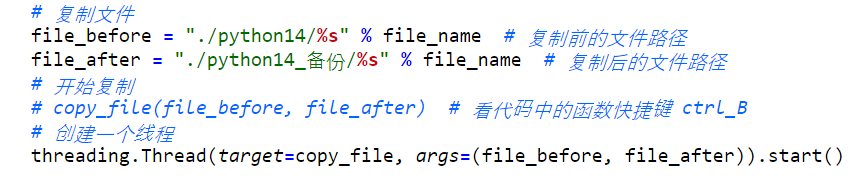
file_before = "./python14/%s" % file_name # 复制前的文件路径
file_after = "./python14_备份/%s" % file_name # 复制后的文件路径
# 开始复制
copy_file(file_before, file_after) # 看代码中的函数快捷键 ctrl_B
if __name__ == '__main__':
main()
2.多线程:
多进程:

3.多进程池:

进程池间的数据共享:
进程之间不共享内存,可以直接使用底层封装好的Manager来处理
import multiprocessing
# 创建进程池
pool = multiprocessing.pool(4)
#1.先创建一个对象
mgr = multiprocessing.Manager()
#2.创建一个用于进程池中各进程共享数据的list,当然这里可以是dict,Lock,Queue等等
data_list = mgr.list()
for i in range(4)
pool.apply_async(test_func,args=(arg1,arg2))
pool.close() # close就是说,不再添加循环了,就这些
pool.join() # join就是说,上面加的这些需要等到都处理完
协程的使用
协程是占用资源最少的,一般,一个进程开一个线程,一个线程里面开多个协程,go语音中的go关键字就是开协程。
import gevent # 协程库
# 一边唱歌,一边跳舞
def dance():
while True:
print("跳舞")
# 睡一会,但是一定要用协程的睡
gevent.sleep(1)
def song():
while True:
print("唱歌")
gevent.sleep(1)
def main():
"""使用协程去运行我们跳舞与唱歌"""
dance_spawn = gevent.spawn(dance)
song_spawn = gevent.spawn(song)
# join一定要写在我们全都添加完以后
dance_spawn.join() # 等一下,一定要处理
song_spawn.join() # 两个都等
if __name__ == '__main__':
main()
对上面进行升级一下,因为我们不能没开一个协程,就join一次,所以用另外一个api
gevent.joinall()
先,定义一个列表,然后把所有协程加入到列表中,最后使用geventjoinall(协程列表)

但是,如果我们只有一个任务呢,或者说,要用协程开启多个同一任务,也需要使用gevent.joinall(协程列表),例:
import gevent # 协程库
def copy():
while True:
print("复制")
gevent.sleep(1)
def main():
"""使用协程去运行我们跳舞与唱歌"""
# gevent.spawn # 我们循环一次用一个协程
# 定义一个列表
spawn_list = list()
for temp in range(10):
# 多协程执行copy
spawn = gevent.spawn(copy)
# 添加到协程列表,用来进行等待
spawn_list.append(spawn)
# 等一下
gevent.joinall(spawn_list)
if __name__ == '__main__':
main()
但是这样还不是最后的,因为我们这里的耗时是用的gevent.sleep()
正常我们程序自动在耗时长的地方进行cpu切换,我们是不知道哪里会耗时长的,所以需要使用:from gevent import monkey
并且,我们需要打个补丁:monkey.patch_all()
如下例:
import gevent # 协程库
import time
# 只要协程第一步就要请猴子
from gevent import monkey
# 打补丁
monkey.patch_all() # 会把当前程序中所有的耗时全转换成我们gevent中的耗时
# 一边read,一边copy
def read():
while True:
print("读取")
time.sleep(1) # 系统会自动将耗时内容转换成我们gevent.sleep(1)
def copy():
while True:
print("复制")
# gevent.sleep(1)
time.sleep(1)
def main():
"""使用协程去运行我们跳舞与唱歌"""
# gevent.spawn # 我们循环一次用一个协程
# 定义一个列表
spawn_list = list()
spawn = gevent.spawn(copy)
spawn_list.append(spawn)
read_spawn = gevent.spawn(read)
spawn_list.append(read_spawn)
# 等一下
gevent.joinall(spawn_list)
if __name__ == '__main__':
main()
总结,只要使用,协程,必须必须导入monkey ,并且需要打补丁
前段时间公司redis的迁移,其中一个redis由于数据量巨大,没有迁移成功,后面测试了好多方法,也都不行,后面用了多进程+协程,一样还是不行,极限速度也就一秒钟迁移1000个左右的key。
这里吧代码放在这里方便以后复习。
# coding=utf-8
from rediscluster import StrictRedisCluster
import os
import multiprocessing
import gevent
from gevent import monkey, pool
monkey.patch_all()
source_redis = [{"host": "172.16.14.198", "port": "7001"}, {"host": "172.16.14.199", "port": "7001"},
{"host": "172.16.14.200", "port": "7001"}, {"host": "172.16.14.201", "port": "7001"},
{"host": "172.16.14.202", "port": "7001"}, {"host": "172.16.14.203", "port": "7001"}, ]
target_redis = [{"host": "172.16.14.204", "port": "7001"}, {"host": "172.16.14.205", "port": "7001"},
{"host": "172.16.14.206", "port": "7001"}, {"host": "172.16.14.207", "port": "7001"},
{"host": "172.16.14.208", "port": "7001"}, {"host": "172.16.14.209", "port": "7001"}, ]
sour_ip = "172.16.14.198"
targ_ip = "172.16.14.204"
try:
source_redis_obj = StrictRedisCluster(startup_nodes=source_redis, decode_responses=True, password=None)
except Exception as e:
print("connect source redis failed,err:" + e)
exit(1)
try:
target_redis_obj = StrictRedisCluster(startup_nodes=target_redis, decode_responses=True, password=None)
except Exception as e:
print("connect target redis failed,err:" + e)
exit(1)
def write_key_to_file(key):
# 查看ttl时间,通过判断ttl时间确定key是否存储和如何存储
ttl = source_redis_obj.ttl(key)
# 已过期,不需要迁移
if ttl == -2:
print("key:" + key + "已过期")
return
# 没有过期时间
elif ttl == -1:
os_popen = os.popen(
"./redis-cli -c -p 7001 -h %s dump %s | head -c-1 |./redis-cli -c -h %s -p 7001 -x restore %s 0" % (
sour_ip, key, targ_ip, key))
for info in os_popen:
if "error" in info:
print(key + "--->" + info)
# 迁移,并同步过期时间
else:
os_popen = os.popen(
"./redis-cli -c -p 7001 -h %s dump %s |head -c-1 |./redis-cli -c -p 7001 -h %s -x restore %s 0 && ./redis-cli -c -p 7001 -h %s expire %s %d" % (
sour_ip, key, targ_ip, key, targ_ip, key, ttl))
for info in os_popen:
if "error" in info:
print(key + "--->" + info)
def open_gevent_pool(keys):
# 开一个协程池,用池子里的资源去处理所有的事情
# 不能开无限个携程,因为redis的连接数量是有限制的。否则连接会报错
gevent_pool = pool.Pool(20)
gevent_list = []
for key in keys:
gevent_list.append(gevent_pool.spawn(write_key_to_file, key))
gevent.joinall(gevent_list)
def get_all_keys():
# 这里获取所有的key,由于我们操作机有16个cpu,因此我们把数据分成16份,然后开启16个进程,每个进程单独处理他们自己对应的那部分数据。
all_keys = source_redis_obj.keys()
len_key = len(all_keys)
ave_key = len_key // 16
for i in range(16):
print(i)
if i != 15:
keys = all_keys[i * ave_key:(i + 1) * ave_key]
else:
keys = all_keys[15 * ave_key:]
multiprocessing.Process(target=open_gevent_pool, args=(keys,)).start()
def main():
get_all_keys()
if __name__ == '__main__':
main()















 1237
1237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









