






在当今数字化时代,数据已经成为各个行业中不可或缺的重要资产。企业需要对数据进行收集、清洗和转换,以获得有用的信息和见解。而ETL(Extract-Transform-Load)是数据处理中常用的一种方式。

批处理ETL
传统的批处理ETL是一种离线处理方式,即将数据按照预设的时间间隔进行定期批量处理。
这种方式的优点是能够处理大量的数据,并且处理过程通常是稳定可控的。
然而,批处理ETL的缺点也显而易见,主要体现在两个方面:实时性和灵活性。
1、 实时性
批处理ETL无法满足对数据实时性的需求。在某些应用场景下,对数据的实时处理是至关重要的,例如金融交易、在线广告投放等领域,如果数据处理存在延迟,将会导致严重的后果。因此,以秒级甚至毫秒级的实时性成为了数据处理的新要求。
2、 灵活性
批处理ETL对数据源和处理方式的变动不太容易适应。在现实应用中,数据源和数据的格式常常发生变化,而批处理ETL需要对整个数据集进行重新处理,导致处理过程的复杂性和耗时性增加。尤其是在大规模的数据处理任务中,这种重新处理可能会耗费大量的资源。

流式ETL
为了解决这些问题,流式ETL作为一种新兴的数据处理方式应运而生。流式ETL可以实时处理数据流,并以事件驱动的方式进行数据转换和加载。相比于批处理ETL,流式ETL具有以下优势:
1、实时性
流式ETL可以实现数据的实时处理。数据一旦产生,就可以立即进行处理和分析,极大地减少处理延迟,提高了数据的实时性。
2、 灵活性
流式ETL具备更强的灵活性。由于流式处理是以事件驱动的方式进行的,可以根据需求对数据进行动态的转换和加载。即使数据源或处理方式发生变化,只需要对新增数据进行处理,而不需要对整个数据集进行重新处理,大大提高了处理的效率和灵活性。
3、 容错性和可伸缩性
此外,流式ETL还具备更好的容错性和可伸缩性。流式处理的特性使其能够在出现故障或高负载时实现自我调整,保证处理的连续性和稳定性。
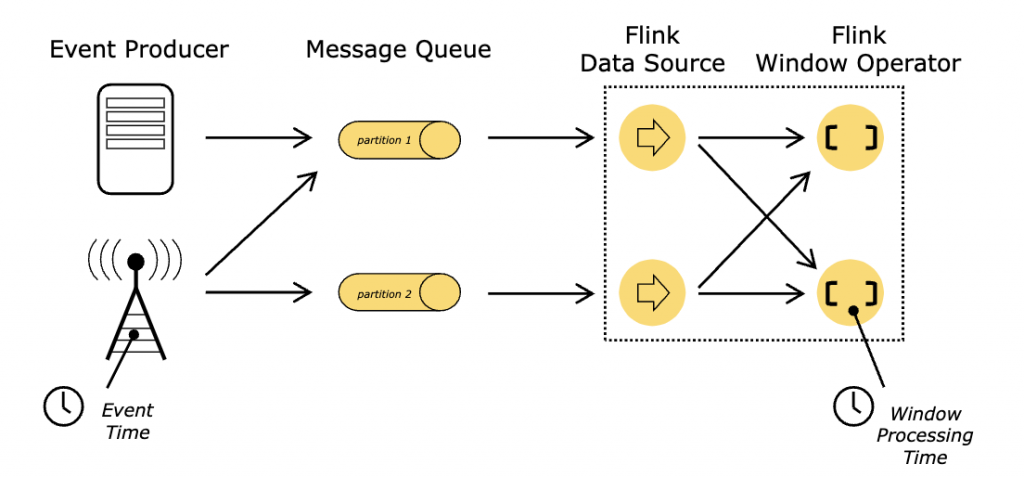
综上所述,流式ETL在数据处理中已经成为一种新的潮流,对于那些对实时性和灵活性有较高要求的应用场景来说,流式ETL是一种更好的选择。然而,批处理ETL仍然适用于某些传统的、对实时性要求不高的场景。在实际应用中,我们可以根据具体需求进行选择和组合使用,以最大程度地发挥数据处理的优势和效果。















 6022
6022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









