









文章目录
lambda表达式
lambda 表达式的语法格式如下:
(parameters) -> expression
或
(parameters) ->{ statements; }
以下是lambda表达式的重要特征:
- 可选类型声明:不需要声明参数类型,编译器可以统一识别参数值。
- 可选的参数圆括号:一个参数无需定义圆括号,但多个参数需要定义圆括号。
- 可选的大括号:如果主体包含了一个语句,就不需要使用大括号。
- 可选的返回关键字:如果主体只有一个表达式返回值则编译器会自动返回值,大括号需要指定明表达式返回了一个数值。
简答例子:
// 1. 不需要参数,返回值为 5
() -> 5
// 2. 接收一个参数(数字类型),返回其2倍的值
x -> 2 * x
// 3. 接受2个参数(数字),并返回他们的差值
(x, y) -> x – y
// 4. 接收2个int型整数,返回他们的和
(int x, int y) -> x + y
// 5. 接受一个 string 对象,并在控制台打印,不返回任何值(看起来像是返回void)
(String s) -> System.out.print(s)
参考:
http://www.runoob.com/java/java8-lambda-expressions.html
函数式接口
函数式接口(Functional Interface)就是一个有且仅有一个抽象方法,但是可以有多个非抽象方法的接口。
函数式接口可以被隐式转换为 lambda 表达式。
四种核心内置函数式接口
| 函数式接口 | 参数类型 | 返回类型 | 用途 |
|---|---|---|---|
| Consumer | T | 无 | 消费型接口,对类型T参数操作,无返回结果,包含方法 void accept(T t) |
| Supplier | 无 | T | 供给型接口,返回T类型参数,方法时 T get() |
| Function | T | R | 函数型接口,对类型T参数操作,返回R类型参数,包含方法 R apply(T t) |
| Predicate | T | boolean | 断言型接口,对类型T进行条件筛选操作,返回boolean,包含方法 boolean test(T t) |
所有的接口列举
| 接口 | 描述 |
|---|---|
| BiConsumer<T,U> | 代表了一个接受两个输入参数的操作,并且不返回任何结果 |
| BiFunction<T,U,R> | 代表了一个接受两个输入参数的方法,并且返回一个结果 |
| BinaryOperator | 代表了一个作用于于两个同类型操作符的操作,并且返回了操作符同类型的结果 |
| BiPredicate<T,U> | 代表了一个两个参数的boolean值方法 |
| BooleanSupplier | 代表了boolean值结果的提供方 |
| Consumer | 代表了接受一个输入参数并且无返回的操作 |
| DoubleBinaryOperator | 代表了作用于两个double值操作符的操作,并且返回了一个double值的结果。 |
| DoubleConsumer | 代表一个接受double值参数的操作,并且不返回结果。 |
| DoubleFunction | 代表接受一个double值参数的方法,并且返回结果 |
| DoublePredicate | 代表一个拥有double值参数的boolean值方法 |
| DoubleSupplier | 代表一个double值结构的提供方 |
| DoubleToIntFunction | 接受一个double类型输入,返回一个int类型结果。 |
| DoubleToLongFunction | 接受一个double类型输入,返回一个long类型结果 |
| DoubleUnaryOperator | 接受一个参数同为类型double,返回值类型也为double 。 |
| Function<T,R> | 接受一个输入参数,返回一个结果。 |
| IntBinaryOperator | 接受两个参数同为类型int,返回值类型也为int 。 |
| IntConsumer | 接受一个int类型的输入参数,无返回值 。 |
| IntFunction | 接受一个int类型输入参数,返回一个结果 。 |
| IntPredicate | 接受一个int输入参数,返回一个布尔值的结果。 |
| IntSupplier | 无参数,返回一个int类型结果。 |
| IntToDoubleFunction | 接受一个int类型输入,返回一个double类型结果 。 |
| IntToLongFunction | 接受一个int类型输入,返回一个long类型结果。 |
| IntUnaryOperator | 接受一个参数同为类型int,返回值类型也为int 。 |
| LongBinaryOperator | 接受两个参数同为类型long,返回值类型也为long。 |
| LongConsumer | 接受一个long类型的输入参数,无返回值。 |
| LongFunction | 接受一个long类型输入参数,返回一个结果。 |
| LongPredicateR | 接受一个long输入参数,返回一个布尔值类型结果。 |
| LongSupplier | 无参数,返回一个结果long类型的值。 |
| LongToDoubleFunction | 接受一个long类型输入,返回一个double类型结果。 |
| LongToIntFunction | 接受一个long类型输入,返回一个int类型结果。 |
| LongUnaryOperator | 接受一个参数同为类型long,返回值类型也为long。 |
| ObjDoubleConsumer | 接受一个object类型和一个double类型的输入参数,无返回值。 |
| ObjIntConsumer | 接受一个object类型和一个int类型的输入参数,无返回值。 |
| ObjLongConsumer | 接受一个object类型和一个long类型的输入参数,无返回值。 |
| Predicate | 接受一个输入参数,返回一个布尔值结果。 |
| Supplier | 无参数,返回一个结果。 |
| ToDoubleBiFunction<T,U> | 接受两个输入参数,返回一个double类型结果 |
| ToDoubleFunction | 接受一个输入参数,返回一个double类型结果 |
| ToIntBiFunction<T,U> | 接受两个输入参数,返回一个int类型结果。 |
| ToIntFunction | 接受一个输入参数,返回一个int类型结果。 |
| ToLongBiFunction<T,U> | 接受两个输入参数,返回一个long类型结果。 |
| ToLongFunction | 接受一个输入参数,返回一个long类型结果。 |
| UnaryOperator | 接受一个参数为类型T,返回值类型也为T。 |
参考:
https://blog.csdn.net/changyinling520/article/details/80570103
https://www.jianshu.com/p/8d7f98116693
http://www.runoob.com/java/java8-functional-interfaces.html
Stream
流是为了处理一串数据(sequence),而不需要多次循环的一种方式。
流在操作序列的时候,会将数据放在一个叫Stream Pipeline的地方,这个地方会有三部分
- 源(一般为集合)
- 0或多个中间操作 (一般为惰性操作,不会直接操作数据)
- 终止操作 (一般为求最终值,这时流的整个流程结束)
流支持并行操作,而迭代器,for循环都是串行操作,所以流在多核处理上有强大优势。
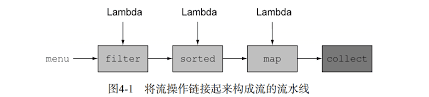
例如:

注:
- ①Stream 自己不会存储元素。
- ②Stream 不会改变源对象。相反,会返回一个持有结果的新Stream。
- ③Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。
1、Stream的创建
一般采用下列四种创建方式:
//1.第一种:通过collection集合提供的stream方法生成
List<String> list = Arrays.asList("1","2","3","4");
Stream<String> stream = list.stream();
stream.forEach(System.out::print);
//2.第二种:通过Arrays提供的stream方法生成
String[] s = new String[]{"1","2","3","4"};
Stream<String> stream2 = Arrays.stream(s);
stream2.forEach(System.out::print);
//3.第三种:利用steam的静态方法of
Stream<String> stream3 = Stream.of("1","2","3","4");
stream3.forEach(System.out::print);
//4.第四种:创建无限流
//选代流
Stream<Integer> stream4 = Stream.iterate(0,(x)->x+2);
stream4.forEach(System.out::print);
//生成
Stream<Double> stream5 = Stream.generate(Math::random);
stream5.limit(5).forEach(System.out::print);
2、Stream操作
(1)中间操作方法
filter
filter方法对原Stream按照指定条件过滤,在新建的Stream中,只包含满足条件的元素,将不满足条件的元素过滤掉。
Stream.of(1, 2, 3, 4, 5)
.filter(item -> item > 3)
.forEach(System.out::println);// 打印结果:4,5
注:filter传入的Lambda表达式必须是Predicate实例,参数可以为任意类型,而其返回值必须是boolean类型。
distinct
distinct方法以达到去除掉原Stream中重复的元素,生成的新Stream中没有没有重复的元素。
Stream.of(1,2,3,1,2,3)
.distinct()
.forEach(System.out::println); // 打印结果:1,2,3
注:distinct()方法是根据stream中元素equal()进行重复判断的
limit/skip
limit 返回 Stream 的前面 n 个元素;skip 则是扔掉前 n 个元素
Stream.of(9, 8, 7, 6, 5, 4, 3, 2, 1).skip(2).limit(3).collect(Collectors.toList());
map
map方法将对于Stream中包含的元素使用给定的转换函数进行转换操作,新生成的Stream只包含转换生成的元素。
Stream.of("a", "b", "hello")
.map(item-> item.toUpperCase())
.forEach(System.out::println);
// 打印结果
// A, B, HELLO
注:map传入的Lambda表达式必须是Function实例,参数可以为任意类型,而其返回值也是任性类型,javac会根据实际情景自行推断。
flatMap
flatMap方法与map方法类似,都是将原Stream中的每一个元素通过转换函数转换,不同的是,区别在于map操作为每个输入值生成一个输出值,而flatMap操作为每个输入值生成一个任意数字(零个或多个)值。
List<Integer> together = Stream.of(Arrays.asList(1,2,3), Arrays.asList(4,5,6), Arrays.asList(7,8,9))
.flatMap(numbers->numbers.stream())
.collect(Collectors.toList());
together.stream().forEach(System.out::println);
// 1 2 3 4 5 6 7 8 9
或
List<StoreSkuDto> storeSkuList = ......
List<PoBaseSkuDto> poBaseSkuList = storeSkuList.stream().flatMap(storeSku->{
List<PoBaseSkuDto> list = setSupplierInfo(storeSku);
return list.stream();
}).collect(Collectors.toList());
注:flatMap传入的Lambda表达式必须是Function实例,参数可以为任意类型,而其返回值类型必须是一个Stream。
concat
concat方法将两个Stream连接在一起,合成一个Stream。
Stream.concat(Stream.of(1, 2, 3), Stream.of(4, 5))
.forEach(integer -> System.out.print(integer + " "));
// 打印结果
// 1 2 3 4 5
peek
peek与map方法类似,预览、执行某个不返回的操作 每次返回新的stream 避免消耗stream,不同的是,区别在于map操作为每个输入值生成一个输出值,而peek操作只有输入没有输出。
sorted
sorted方法将对原Stream进行排序,返回一个有序列的新Stream。sorterd有两种变体sorted(),sorted(Comparator),前者将默认使用Object.equals(Object)进行排序,而后者接受一个自定义排序规则函数(Comparator),可按照意愿排序。
Stream.of(5, 4, 3, 2, 1)
.sorted()
.forEach(System.out::println;
// 打印结果
// 1,2,3,4,5
或
List<ReplenishTimeMessage> tempExecList = ......
tempExecList = tempExecList.stream().sorted((o1, o2) -> {
return o1.getId().compareTo(o2.getId());
}).collect(Collectors.toList());
(2)终端操作方法
forEach
forEach 接收一个 Consumer 接口,只接收不参数,没有返回值。然后在 Stream 的每一个元素上执行该表达式。
注:生成一个新的对象的时候,使用 map 会更好;只是操作 list 内部的对象时,用 forEach。
List<Person> intList = Arrays.asList(new Person(1,"person1"), new Person(2,"person2"), new Person(3,"person3"));
intList.stream().forEach(person->person.setId(10));
intList.stream().forEach(person-> System.out.println(person.getId()));
System.out.println(JSON.toJSON(intList));
allMatch/anyMatch/noneMatch
有的时候,我们只需要判断集合中是否全部满足条件,或者判断集合中是否有满足条件的元素,这时候就可以使用match方法:
- allMatch:Stream 中全部元素符合传入的 predicate,返回 true
- anyMatch:Stream 中只要有一个元素符合传入的 predicate,返回 true
- noneMatch:Stream 中没有一个元素符合传入的 predicate,返回 true
// 判断集合中没有有为6的元素:
boolean isExits =Stream.of(9, 8, 7, 6, 5, 4, 3, 2, 1).anyMatch(s -> s.equals(6));
boolean isNotEmpty = Stream.of("9", "8", "7", "6", "", "5", "4", "3", "2", "1").noneMatch(s -> s.isEmpty())
min/max/count
max,min可以寻找出流中最大或者最小的元素,count是用于统计数量
int maxLength = Stream.of("9", "8", "7", "6", "", "5", "4", "3", "2", "123432").mapToInt(s->s.length()).max().getAsInt();
System.out.println("字符串长度最长的长度为"+maxLength);
findFirst/findAny
findFirst() 返回第一个元素,findAny() 返回当前流中的任意元素
collect,将流转换为其他形式
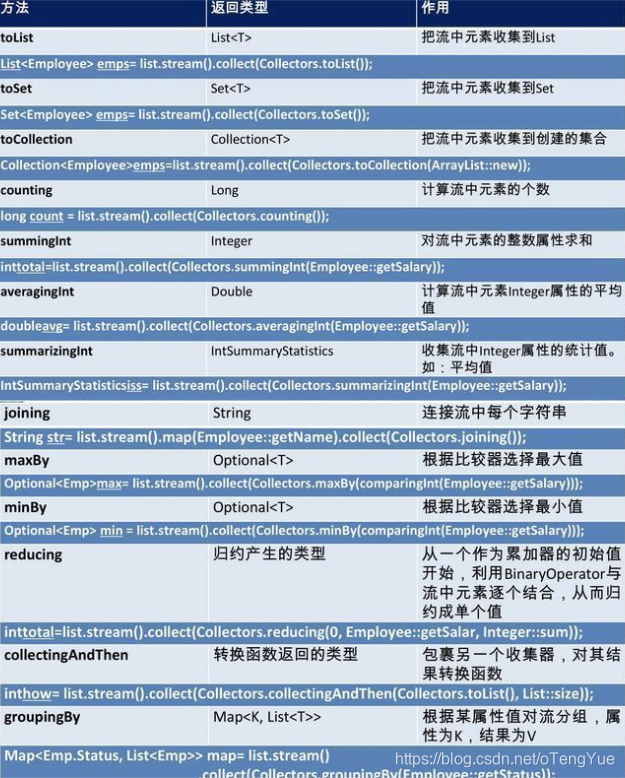
reduce
理解reduce的含义重点就在于理解"累 加 器" 的概念
例如:
reduce共有三种override方法
Optional<T> reduce(BinaryOperator<T> accumulator);
未定义初始值,从而第一次执行的时候第一个参数的值是Stream的第一个元素,第二个参数是Stream的第二个元素
例如:System.out.println(Arrays.asList(1,2,3,4,5).stream().reduce((a,b) -> a+b).get());T reduce(T identity, BinaryOperator<T> accumulator);
定义了初始值,从而第一次执行的时候第一个参数的值是初始值,第二个参数是Stream的第一个元素
例如:System.out.println(Arrays.asList(1,2,3,4,5).stream().reduce(0,(a,b) -> a+b));<U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner);
返回类型为U Stream类型为T 有了更大的发挥空间 T可能为U 也可能不是U ,在串行流和并行流的结果不一样,需慎用。详细用法可以点击下面的参考链接了解。
参考:
https://www.cnblogs.com/noteless/p/9511407.html
https://blog.csdn.net/IO_Field/article/details/54971679
3、stream和parallelStream
定义
- stream:串行流。在当前线程中按顺序执行操作(不开线程)。
- parallelStream:并行流。开启多个线程和当前线程一起执行操作,它通过默认的ForkJoinPool,可能提高你的多线程任务的速度.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.parallelStream().forEach(out::println);
numbers.stream().forEach(out::println);
如何从stream和parallelStream方法中进行选择:
- 1.是否需要并行?
当数据量不大时,顺序执行往往比并行执行更快。毕竟,准备线程池和其它相关资源也是需要时间的。但是,当任务涉及到I/O操作并且任务之间不互相依赖时,那么并行化就是一个不错的选择。通常而言,将这类程序并行化之后,执行速度会提升好几个等级。 - 2.任务之间是否是独立的?
如果任务之间是独立的,那么就表明代码是可以被并行化的。 - 3.结果是否取决于任务的调用顺序?
由于在并行环境中任务的执行顺序是不确定的,因此对于依赖于顺序的任务而言,并行化也许不能给出正确的结果。














 5457
5457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









