






一、需求描述
在企业审计业务和公文业务中,需要实现对文档内容的对比,对比的结果供工作人员进行核查。主要实现以下功能:
1.对比的结果以富文本的样式导出到excel中
2.保留对比结果的新增、修改和删除效果
实现的最终效果图如下:
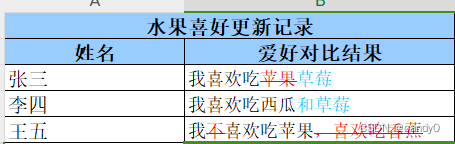
二、具体实现步骤
需求看似简单,但实现起来有以下几大难点:
- 文字内容比较的算法,如何快速找出并定位一段文本中的内容?
- 在比对出结果后需要采用富文本的样式进行展示,如何实现?
2.1 引入EasyExcel
主要实现Excel文件的处理,包含对比内容的生成等。
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<easyexcel.version>3.0.5</easyexcel.version>
</dependency>2.2 引入开源DiffMatchPatch
主要实现文本的比对,代码不算太多,重点需要知道如何使用即可。具体代码如下:
package com.demo.common.utils;
/*
* Diff Match and Patch
*
* Copyright 2006 Google Inc.
* http://code.google.com/p/google-diff-match-patch/
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
import java.io.UnsupportedEncodingException;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.util.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* Functions for diff, match and patch.
* Computes the difference between two texts to create a patch.
* Applies the patch onto another text, allowing for errors.
*
* @author fraser@google.com (Neil Fraser)
*/
/**
* Class containing the diff, match and patch methods.
* Also contains the behaviour settings.
*/
@SuppressWarnings("all")
public class DiffMatchPatch {
// Defaults.
// Set these on your diff_match_patch instance to override the defaults.
/**
* Number of seconds to map a diff before giving up (0 for infinity).
*/
public float Diff_Timeout = 1.0f;
/**
* Cost of an empty edit operation in terms of edit characters.
*/
public short Diff_EditCost = 4;
/**
* The size beyond which the double-ended diff activates.
* Double-ending is twice as fast, but less accurate.
*/
public short Diff_DualThreshold = 32;
/**
* At what point is no match declared (0.0 = perfection, 1.0 = very loose).
*/
public float Match_Threshold = 0.5f;
/**
* How far to search for a match (0 = exact location, 1000+ = broad match).
* A match this many characters away from the expected location will add
* 1.0 to the score (0.0 is a perfect match).
*/
public int Match_Distance = 1000;
/**
* When deleting a large block of text (over ~64 characters), how close does
* the contents have to match the expected contents. (0.0 = perfection,
* 1.0 = very loose). Note that Match_Threshold controls how closely the
* end points of a delete need to match.
*/
public float Patch_DeleteThreshold = 0.5f;
/**
* Chunk size for context length.
*/
public short Patch_Margin = 4;
/**
* The number of bits in an int.
*/
private int Match_MaxBits = 32;
/**
* Internal class for returning results from diff_linesToChars().
* Other less paranoid languages just use a three-element array.
*/
protected static class LinesToCharsResult {
protected String chars1;
protected String chars2;
protected List<String> lineArray;
protected LinesToCharsResult(String chars1, String chars2,
List<String> lineArray) {
this.chars1 = chars1;
this.chars2 = chars2;
this.lineArray = lineArray;
}
}
// DIFF FUNCTIONS
/**
* The data structure representing a diff is a Linked list of Diff objects:
* {Diff(Operation.DELETE, "Hello"), Diff(Operation.INSERT, "Goodbye"),
* Diff(Operation.EQUAL, " world.")}
* which means: delete "Hello", add "Goodbye" and keep " world."
*/
public enum Operation {
DELETE, INSERT, EQUAL
}
/**
* Find the differences between two texts.
* Run a faster slightly less optimal diff
* This method allows the 'checklines' of diff_main() to be optional.
* Most of the time checklines is wanted, so default to true.
* @param text1 Old string to be diffed.
* @param text2 New string to be diffed.
* @return Linked List of Diff objects.
*/
public LinkedList<Diff> diff_main(String text1, String text2) {
return diff_main(text1, text2, true);
}
/**
* Find the differences between two texts. Simplifies the problem by
* stripping any common prefix or suffix off the texts before diffing.
* @param text1 Old string to be diffed.
* @param text2 New string to be diffed.
* @param checklines Speedup flag. If false, then don't run a
* line-level diff first to identify the changed areas.
* If true, then run a faster slightly less optimal diff
* @return Linked List of Diff objects.
*/
public LinkedList<Diff> diff_main(String text1, String text2, boolean checklines) {
// Check for equality (speedup)
LinkedList<Diff> diffs;
if (text1.equals(text2)) {
diffs = new LinkedList<Diff>();
diffs.add(new Diff(Operation.EQUAL, text1));
return diffs;
}
// Trim off common prefix (speedup)
int commonlength = diff_commonPrefix(text1, text2);
String commonprefix = text1.substring(0, commonlength);
text1 = text1.substring(commonlength);
text2 = text2.substring(commonlength);
// Trim off common suffix (speedup)
commonlength = diff_commonSuffix(text1, text2);
String commonsuffix = text1.substring(text1.length() - commonlength);
text1 = text1.substring(0, text1.length() - commonlength);
text2 = text2.substring(0, text2.length() - commonlength);
// Compute the diff on the middle block
diffs = diff_compute(text1, text2, checklines);
// Restore the prefix and suffix
if (commonprefix.length() != 0) {
diffs.addFirst(new Diff(Operation.EQUAL, commonprefix));
}
if (commonsuffix.length() != 0) {
diffs.addLast(new Diff(Operation.EQUAL, commonsuffix));
}
diff_cleanupMerge(diffs);
return diffs;
}
/**
* Find the differences between two texts. Assumes that the texts do not
* have any common prefix or suffix.
* @param text1 Old string to be diffed.
* @param text2 New string to be diffed.
* @param checklines Speedup flag. If false, then don't run a
* line-level diff first to identify the changed areas.
* If true, then run a faster slightly less optimal diff
* @return Linked List of Diff objects.
*/
protected LinkedList<Diff> diff_compute(String text1, String text2,boolean checklines) {
LinkedList<Diff> diffs = new LinkedList<Diff>();
if (text1.length() == 0) {
// Just add some text (speedup)
diffs.add(new Diff(Operation.INSERT, text2));
return diffs;
}
if (text2.length() == 0) {
// Just delete some text (speedup)
diffs.add(new Diff(Operation.DELETE, text1));
return diffs;
}
String longtext = text1.length() > text2.length() ? text1 : text2;
String shorttext = text1.length() > text2.length() ? text2 : text1;
int i = longtext.indexOf(shorttext);
if (i != -1) {
// Shorter text is inside the longer text (speedup)
Operation op = (text1.length() > text2.length()) ?
Operation.DELETE : Operation.INSERT;
diffs.add(new Diff(op, longtext.substring(0, i)));
diffs.add(new Diff(Operation.EQUAL, shorttext));
diffs.add(new Diff(op, longtext.substring(i + shorttext.length())));
return diffs;
}
longtext = shorttext = null; // Garbage collect.
// Check to see if the problem can be split in two.
String[] hm = diff_halfMatch(text1, text2);
if (hm != null) {
// A half-match was found, sort out the return data.
String text1_a = hm[0];
String text1_b = hm[1];
String text2_a = hm[2];
String text2_b = hm[3];
String mid_common = hm[4];
// Send both pairs off for separate processing.
LinkedList<Diff> diffs_a = diff_main(text1_a, text2_a, checklines);
LinkedList<Diff> diffs_b = diff_main(text1_b, text2_b, checklines);
// Merge the results.
diffs = diffs_a;
diffs.add(new Diff(Operation.EQUAL, mid_common));
diffs.addAll(diffs_b);
return diffs;
}
// Perform a real diff.
if (checklines && (text1.length() < 100 || text2.length() < 100)) {
checklines = false; // Too trivial for the overhead.
}
List<String> linearray = null;
if (checklines) {
// Scan the text on a line-by-line basis first.
LinesToCharsResult b = diff_linesToChars(text1, text2);
text1 = b.chars1;
text2 = b.chars2;
linearray = b.lineArray;
}
diffs = diff_map(text1, text2);
if (diffs == null) {
// No acceptable result.
diffs = new LinkedList<Diff>();
diffs.add(new Diff(Operation.DELETE, text1));
diffs.add(new Diff(Operation.INSERT, text2));
}
if (checklines) {
// Convert the diff back to original text.
diff_charsToLines(diffs, linearray);
// Eliminate freak matches (e.g. blank lines)
diff_cleanupSemantic(diffs);
// Rediff any replacement blocks, this time character-by-character.
// Add a dummy entry at the end.
diffs.add(new Diff(Operation.EQUAL, ""));
int count_delete = 0;
int count_insert = 0;
String text_delete = "";
String text_insert = "";
ListIterator<Diff> pointer = diffs.listIterator();
Diff thisDiff = pointer.next();
while (thisDiff != null) {
switch (thisDiff.operation) {
case INSERT:
count_insert++;
text_insert += thisDiff.text;
break;
case DELETE:
count_delete++;
text_delete += thisDiff.text;
break;
case EQUAL:
// Upon reaching an equality, check for prior redundancies.
if (count_delete >= 1 && count_insert >= 1) {
// Delete the offending records and add the merged ones.
pointer.previous();
for (int j = 0; j < count_delete + count_insert; j++) {
pointer.previous();
pointer.remove();
}
for (Diff newDiff : diff_main(text_delete, text_insert, false)) {
pointer.add(newDiff);
}
}
count_insert = 0;
count_delete = 0;
text_delete = "";
text_insert = "";
break;
}
thisDiff = pointer.hasNext() ? pointer.next() : null;
}
diffs.removeLast(); // Remove the dummy entry at the end.
}
return diffs;
}
/**
* Split two texts into a list of strings. Reduce the texts to a string of
* hashes where each Unicode character represents one line.
* @param text1 First string.
* @param text2 Second string.
* @return An object containing the encoded text1, the encoded text2 and
* the List of unique strings. The zeroth element of the List of
* unique strings is intentionally blank.
*/
protected LinesToCharsResult diff_linesToChars(String text1, String text2) {
List<String> lineArray = new ArrayList<String>();
Map<String, Integer> lineHash = new HashMap<String, Integer>();
// e.g. linearray[4] == "Hello\n"
// e.g. linehash.get("Hello\n") == 4
// "\x00" is a valid character, but various debuggers don't like it.
// So we'll insert a junk entry to avoid generating a null character.
lineArray.add("");
String chars1 = diff_linesToCharsMunge(text1, lineArray, lineHash);
String chars2 = diff_linesToCharsMunge(text2, lineArray, lineHash);
return new LinesToCharsResult(chars1, chars2, lineArray);
}
/**
* Split a text into a list of strings. Reduce the texts to a string of
* hashes where each Unicode character represents one line.
* @param text String to encode.
* @param lineArray List of unique strings.
* @param lineHash Map of strings to indices.
* @return Encoded string.
*/
private String diff_linesToCharsMunge(String text, List<String> lineArray,
Map<String, Integer> lineHash) {
int lineStart = 0;
int lineEnd = -1;
String line;
StringBuilder chars = new StringBuilder();
// Walk the text, pulling out a substring for each line.
// text.split('\n') would would temporarily double our memory footprint.
// Modifying text would create many large strings to garbage collect.
while (lineEnd < text.length() - 1) {
lineEnd = text.indexOf('\n', lineStart);
if (lineEnd == -1) {
lineEnd = text.length() - 1;
}
line = text.substring(lineStart, lineEnd + 1);
lineStart = lineEnd + 1;
if (lineHash.containsKey(line)) {
chars.append(String.valueOf((char) (int) lineHash.get(line)));
} else {
lineArray.add(line);
lineHash.put(line, lineArray.size() - 1);
chars.append(String.valueOf((char) (lineArray.size() - 1)));
}
}
return chars.toString();
}
/**
* Rehydrate the text in a diff from a string of line hashes to real lines of
* text.
* @param diffs LinkedList of Diff objects.
* @param lineArray List of unique strings.
*/
protected void diff_charsToLines(LinkedList<Diff> diffs,
List<String> lineArray) {
StringBuilder text;
for (Diff diff : diffs) {
text = new StringBuilder();
for (int y = 0; y < diff.text.length(); y++) {
text.append(lineArray.get(diff.text.charAt(y)));
}
diff.text = text.toString();
}
}
/**
* Explore the intersection points between the two texts.
* @param text1 Old string to be diffed.
* @param text2 New string to be diffed.
* @return LinkedList of Diff objects or null if no diff available.
*/
protected LinkedList<Diff> diff_map(String text1, String text2) {
long ms_end = System.currentTimeMillis() + (long) (Diff_Timeout * 1000);
// Cache the text lengths to prevent multiple calls.
int text1_length = text1.length();
int text2_length = text2.length();
int max_d = text1_length + text2_length - 1;
boolean doubleEnd = Diff_DualThreshold * 2 < max_d;
List<Set<Long>> v_map1 = new ArrayList<Set<Long>>();
List<Set<Long>> v_map2 = new ArrayList<Set<Long>>();
Map<Integer, Integer> v1 = new HashMap<Integer, Integer>();
Map<Integer, Integer> v2 = new HashMap<Integer, Integer>();
v1.put(1, 0);
v2.put(1, 0);
int x, y;
Long footstep = 0L; // Used to track overlapping paths.
Map<Long, Integer> footsteps = new HashMap<Long, Integer>();
boolean done = false;
// If the total number of characters is odd, then the front path will
// collide with the reverse path.
boolean front = ((text1_length + text2_length) % 2 == 1);
for (int d = 0; d < max_d; d++) {
// Bail out if timeout reached.
if (Diff_Timeout > 0 && System.currentTimeMillis() > ms_end) {
return null;
}
// Walk the front path one step.
v_map1.add(new HashSet<Long>()); // Adds at index 'd'.
for (int k = -d; k <= d; k += 2) {
if (k == -d || k != d && v1.get(k - 1) < v1.get(k + 1)) {
x = v1.get(k + 1);
} else {
x = v1.get(k - 1) + 1;
}
y = x - k;
if (doubleEnd) {
footstep = diff_footprint(x, y);
if (front && (footsteps.containsKey(footstep))) {
done = true;
}
if (!front) {
footsteps.put(footstep, d);
}
}
while (!done && x < text1_length && y < text2_length
&& text1.charAt(x) == text2.charAt(y)) {
x++;
y++;
if (doubleEnd) {
footstep = diff_footprint(x, y);
if (front && (footsteps.containsKey(footstep))) {
done = true;
}
if (!front) {
footsteps.put(footstep, d);
}
}
}
v1.put(k, x);
v_map1.get(d).add(diff_footprint(x, y));
if (x == text1_length && y == text2_length) {
// Reached the end in single-path mode.
return diff_path1(v_map1, text1, text2);
} else if (done) {
// Front path ran over reverse path.
v_map2 = v_map2.subList(0, footsteps.get(footstep) + 1);
LinkedList<Diff> a = diff_path1(v_map1, text1.substring(0, x),
text2.substring(0, y));
a.addAll(diff_path2(v_map2, text1.substring(x), text2.substring(y)));
return a;
}
}
if (doubleEnd) {
// Walk the reverse path one step.
v_map2.add(new HashSet<Long>()); // Adds at index 'd'.
for (int k = -d; k <= d; k += 2) {
if (k == -d || k != d && v2.get(k - 1) < v2.get(k + 1)) {
x = v2.get(k + 1);
} else {
x = v2.get(k - 1) + 1;
}
y = x - k;
footstep = diff_footprint(text1_length - x, text2_length - y);
if (!front && (footsteps.containsKey(footstep))) {
done = true;
}
if (front) {
footsteps.put(footstep, d);
}
while (!done && x < text1_length && y < text2_length
&& text1.charAt(text1_length - x - 1)
== text2.charAt(text2_length - y - 1)) {
x++;
y++;
footstep = diff_footprint(text1_length - x, text2_length - y);
if (!front && (footsteps.containsKey(footstep))) {
done = true;
}
if (front) {
footsteps.put(footstep, d);
}
}
v2.put(k, x);
v_map2.get(d).add(diff_footprint(x, y));
if (done) {
// Reverse path ran over front path.
v_map1 = v_map1.subList(0, footsteps.get(footstep) + 1);
LinkedList<Diff> a
= diff_path1(v_map1, text1.substring(0, text1_length - x),
text2.substring(0, text2_length - y));
a.addAll(diff_path2(v_map2, text1.substring(text1_length - x),
text2.substring(text2_length - y)));
return a;
}
}
}
}
// Number of diffs equals number of characters, no commonality at all.
return null;
}
/**
* Work from the middle back to the start to determine the path.
* @param v_map List of path sets.
* @param text1 Old string fragment to be diffed.
* @param text2 New string fragment to be diffed.
* @return LinkedList of Diff objects.
*/
protected LinkedList<Diff> diff_path1(List<Set<Long>> v_map,
String text1, String text2) {
LinkedList<Diff> path = new LinkedList<Diff>();
int x = text1.length();
int y = text2.length();
Operation last_op = null;
for (int d = v_map.size() - 2; d >= 0; d--) {
while (true) {
if (v_map.get(d).contains(diff_footprint(x - 1, y))) {
x--;
if (last_op == Operation.DELETE) {
path.getFirst().text = text1.charAt(x) + path.getFirst().text;
} else {
path.addFirst(new Diff(Operation.DELETE,
text1.substring(x, x + 1)));
}
last_op = Operation.DELETE;
break;
} else if (v_map.get(d).contains(diff_footprint(x, y - 1))) {
y--;
if (last_op == Operation.INSERT) {
path.getFirst().text = text2.charAt(y) + path.getFirst().text;
} else {
path.addFirst(new Diff(Operation.INSERT,
text2.substring(y, y + 1)));
}
last_op = Operation.INSERT;
break;
} else {
x--;
y--;
assert (text1.charAt(x) == text2.charAt(y))
: "No diagonal. Can't happen. (diff_path1)";
if (last_op == Operation.EQUAL) {
path.getFirst().text = text1.charAt(x) + path.getFirst().text;
} else {
path.addFirst(new Diff(Operation.EQUAL, text1.substring(x, x + 1)));
}
last_op = Operation.EQUAL;
}
}
}
return path;
}
/**
* Work from the middle back to the end to determine the path.
* @param v_map List of path sets.
* @param text1 Old string fragment to be diffed.
* @param text2 New string fragment to be diffed.
* @return LinkedList of Diff objects.
*/
protected LinkedList<Diff> diff_path2(List<Set<Long>> v_map,
String text1, String text2) {
LinkedList<Diff> path = new LinkedList<Diff>();
int x = text1.length();
int y = text2.length();
Operation last_op = null;
for (int d = v_map.size() - 2; d >= 0; d--) {
while (true) {
if (v_map.get(d).contains(diff_footprint(x - 1, y))) {
x--;
if (last_op == Operation.DELETE) {
path.getLast().text += text1.charAt(text1.length() - x - 1);
} else {
path.addLast(new Diff(Operation.DELETE,
text1.substring(text1.length() - x - 1, text1.length() - x)));
}
last_op = Operation.DELETE;
break;
} else if (v_map.get(d).contains(diff_footprint(x, y - 1))) {
y--;
if (last_op == Operation.INSERT) {
path.getLast().text += text2.charAt(text2.length() - y - 1);
} else {
path.addLast(new Diff(Operation.INSERT,
text2.substring(text2.length() - y - 1, text2.length() - y)));
}
last_op = Operation.INSERT;
break;
} else {
x--;
y--;
assert (text1.charAt(text1.length() - x - 1)
== text2.charAt(text2.length() - y - 1))
: "No diagonal. Can't happen. (diff_path2)";
if (last_op == Operation.EQUAL) {
path.getLast().text += text1.charAt(text1.length() - x - 1);
} else {
path.addLast(new Diff(Operation.EQUAL,
text1.substring(text1.length() - x - 1, text1.length() - x)));
}
last_op = Operation.EQUAL;
}
}
}
return path;
}
/**
* Compute a good hash of two integers.
* @param x First int.
* @param y Second int.
* @return A long made up of both ints.
*/
protected long diff_footprint(int x, int y) {
// The maximum size for a long is 9,223,372,036,854,775,807
// The maximum size for an int is 2,147,483,647
// Two ints fit nicely in one long.
long result = x;
result = result << 32;
result += y;
return result;
}
/**
* Determine the common prefix of two strings
* @param text1 First string.
* @param text2 Second string.
* @return The number of characters common to the start of each string.
*/
public int diff_commonPrefix(String text1, String text2) {
// Performance analysis: http://neil.fraser.name/news/2007/10/09/
int n = Math.min(text1.length(), text2.length());
for (int i = 0; i < n; i++) {
if (text1.charAt(i) != text2.charAt(i)) {
return i;
}
}
return n;
}
/**
* Determine the common suffix of two strings
* @param text1 First string.
* @param text2 Second string.
* @return The number of characters common to the end of each string.
*/
public int diff_commonSuffix(String text1, String text2) {
// Performance analysis: http://neil.fraser.name/news/2007/10/09/
int text1_length = text1.length();
int text2_length = text2.length();
int n = Math.min(text1_length, text2_length);
for (int i = 1; i <= n; i++) {
if (text1.charAt(text1_length - i) != text2.charAt(text2_length - i)) {
return i - 1;
}
}
return n;
}
/**
* Do the two texts share a substring which is at least half the length of
* the longer text?
* @param text1 First string.
* @param text2 Second string.
* @return Five element String array, containing the prefix of text1, the
* suffix of text1, the prefix of text2, the suffix of text2 and the
* common middle. Or null if there was no match.
*/
protected String[] diff_halfMatch(String text1, String text2) {
String longtext = text1.length() > text2.length() ? text1 : text2;
String shorttext = text1.length() > text2.length() ? text2 : text1;
if (longtext.length() < 10 || shorttext.length() < 1) {
return null; // Pointless.
}
// First check if the second quarter is the seed for a half-match.
String[] hm1 = diff_halfMatchI(longtext, shorttext,
(longtext.length() + 3) / 4);
// Check again based on the third quarter.
String[] hm2 = diff_halfMatchI(longtext, shorttext,
(longtext.length() + 1) / 2);
String[] hm;
if (hm1 == null && hm2 == null) {
return null;
} else if (hm2 == null) {
hm = hm1;
} else if (hm1 == null) {
hm = hm2;
} else {
// Both matched. Select the longest.
hm = hm1[4].length() > hm2[4].length() ? hm1 : hm2;
}
// A half-match was found, sort out the return data.
if (text1.length() > text2.length()) {
return hm;
//return new String[]{hm[0], hm[1], hm[2], hm[3], hm[4]};
} else {
return new String[]{hm[2], hm[3], hm[0], hm[1], hm[4]};
}
}
/**
* Does a substring of shorttext exist within longtext such that the
* substring is at least half the length of longtext?
* @param longtext Longer string.
* @param shorttext Shorter string.
* @param i Start index of quarter length substring within longtext.
* @return Five element String array, containing the prefix of longtext, the
* suffix of longtext, the prefix of shorttext, the suffix of shorttext
* and the common middle. Or null if there was no match.
*/
private String[] diff_halfMatchI(String longtext, String shorttext, int i) {
// Start with a 1/4 length substring at position i as a seed.
String seed = longtext.substring(i, i + longtext.length() / 4);
int j = -1;
String best_common = "";
String best_longtext_a = "", best_longtext_b = "";
String best_shorttext_a = "", best_shorttext_b = "";
while ((j = shorttext.indexOf(seed, j + 1)) != -1) {
int prefixLength = diff_commonPrefix(longtext.substring(i), shorttext.substring(j));
int suffixLength = diff_commonSuffix(longtext.substring(0, i),
shorttext.substring(0, j));
if (best_common.length() < suffixLength + prefixLength) {
best_common = shorttext.substring(j - suffixLength, j)
+ shorttext.substring(j, j + prefixLength);
best_longtext_a = longtext.substring(0, i - suffixLength);
best_longtext_b = longtext.substring(i + prefixLength);
best_shorttext_a = shorttext.substring(0, j - suffixLength);
best_shorttext_b = shorttext.substring(j + prefixLength);
}
}
if (best_common.length() >= longtext.length() / 2) {
return new String[]{best_longtext_a, best_longtext_b,
best_shorttext_a, best_shorttext_b, best_common};
} else {
return null;
}
}
/**
* Reduce the number of edits by eliminating semantically trivial equalities.
* @param diffs LinkedList of Diff objects.
*/
public void diff_cleanupSemantic(LinkedList<Diff> diffs) {
if (diffs.isEmpty()) {
return;
}
boolean changes = false;
Stack<Diff> equalities = new Stack<Diff>(); // Stack of qualities.
String lastequality = null; // Always equal to equalities.lastElement().text
ListIterator<Diff> pointer = diffs.listIterator();
// Number of characters that changed prior to the equality.
int length_changes1 = 0;
// Number of characters that changed after the equality.
int length_changes2 = 0;
Diff thisDiff = pointer.next();
while (thisDiff != null) {
if (thisDiff.operation == Operation.EQUAL) {
// equality found
equalities.push(thisDiff);
length_changes1 = length_changes2;
length_changes2 = 0;
lastequality = thisDiff.text;
} else {
// an insertion or deletion
length_changes2 += thisDiff.text.length();
if (lastequality != null && (lastequality.length() <= length_changes1)
&& (lastequality.length() <= length_changes2)) {
//System.out.println("Splitting: '" + lastequality + "'");
// Walk back to offending equality.
while (thisDiff != equalities.lastElement()) {
thisDiff = pointer.previous();
}
pointer.next();
// Replace equality with a delete.
pointer.set(new Diff(Operation.DELETE, lastequality));
// Insert a corresponding an insert.
pointer.add(new Diff(Operation.INSERT, lastequality));
equalities.pop(); // Throw away the equality we just deleted.
if (!equalities.empty()) {
// Throw away the previous equality (it needs to be reevaluated).
equalities.pop();
}
if (equalities.empty()) {
// There are no previous equalities, walk back to the start.
while (pointer.hasPrevious()) {
pointer.previous();
}
} else {
// There is a safe equality we can fall back to.
thisDiff = equalities.lastElement();
while (thisDiff != pointer.previous()) {
// Intentionally empty loop.
}
}
length_changes1 = 0; // Reset the counters.
length_changes2 = 0;
lastequality = null;
changes = true;
}
}
thisDiff = pointer.hasNext() ? pointer.next() : null;
}
if (changes) {
diff_cleanupMerge(diffs);
}
diff_cleanupSemanticLossless(diffs);
}
/**
* Look for single edits surrounded on both sides by equalities
* which can be shifted sideways to align the edit to a word boundary.
* e.g: The c<ins>at c</ins>ame. -> The <ins>cat </ins>came.
* @param diffs LinkedList of Diff objects.
*/
public void diff_cleanupSemanticLossless(LinkedList<Diff> diffs) {
String equality1, edit, equality2;
String commonString;
int commonOffset;
int score, bestScore;
String bestEquality1, bestEdit, bestEquality2;
// Create a new iterator at the start.
ListIterator<Diff> pointer = diffs.listIterator();
Diff prevDiff = pointer.hasNext() ? pointer.next() : null;
Diff thisDiff = pointer.hasNext() ? pointer.next() : null;
Diff nextDiff = pointer.hasNext() ? pointer.next() : null;
// Intentionally ignore the first and last element (don't need checking).
while (nextDiff != null) {
if (prevDiff.operation == Operation.EQUAL &&
nextDiff.operation == Operation.EQUAL) {
// This is a single edit surrounded by equalities.
equality1 = prevDiff.text;
edit = thisDiff.text;
equality2 = nextDiff.text;
// First, shift the edit as far left as possible.
commonOffset = diff_commonSuffix(equality1, edit);
if (commonOffset != 0) {
commonString = edit.substring(edit.length() - commonOffset);
equality1 = equality1.substring(0, equality1.length() - commonOffset);
edit = commonString + edit.substring(0, edit.length() - commonOffset);
equality2 = commonString + equality2;
}
// Second, step character by character right, looking for the best fit.
bestEquality1 = equality1;
bestEdit = edit;
bestEquality2 = equality2;
bestScore = diff_cleanupSemanticScore(equality1, edit)
+ diff_cleanupSemanticScore(edit, equality2);
while (edit.length() != 0 && equality2.length() != 0
&& edit.charAt(0) == equality2.charAt(0)) {
equality1 += edit.charAt(0);
edit = edit.substring(1) + equality2.charAt(0);
equality2 = equality2.substring(1);
score = diff_cleanupSemanticScore(equality1, edit)
+ diff_cleanupSemanticScore(edit, equality2);
// The >= encourages trailing rather than leading whitespace on edits.
if (score >= bestScore) {
bestScore = score;
bestEquality1 = equality1;
bestEdit = edit;
bestEquality2 = equality2;
}
}
if (!prevDiff.text.equals(bestEquality1)) {
// We have an improvement, save it back to the diff.
if (bestEquality1.length() != 0) {
prevDiff.text = bestEquality1;
} else {
pointer.previous(); // Walk past nextDiff.
pointer.previous(); // Walk past thisDiff.
pointer.previous(); // Walk past prevDiff.
pointer.remove(); // Delete prevDiff.
pointer.next(); // Walk past thisDiff.
pointer.next(); // Walk past nextDiff.
}
thisDiff.text = bestEdit;
if (bestEquality2.length() != 0) {
nextDiff.text = bestEquality2;
} else {
pointer.remove(); // Delete nextDiff.
nextDiff = thisDiff;
thisDiff = prevDiff;
}
}
}
prevDiff = thisDiff;
thisDiff = nextDiff;
nextDiff = pointer.hasNext() ? pointer.next() : null;
}
}
/**
* Given two strings, compute a score representing whether the internal
* boundary falls on logical boundaries.
* Scores range from 5 (best) to 0 (worst).
* @param one First string.
* @param two Second string.
* @return The score.
*/
private int diff_cleanupSemanticScore(String one, String two) {
if (one.length() == 0 || two.length() == 0) {
// Edges are the best.
return 5;
}
// Each port of this function behaves slightly differently due to
// subtle differences in each language's definition of things like
// 'whitespace'. Since this function's purpose is largely cosmetic,
// the choice has been made to use each language's native features
// rather than force total conformity.
int score = 0;
// One point for non-alphanumeric.
if (!Character.isLetterOrDigit(one.charAt(one.length() - 1))
|| !Character.isLetterOrDigit(two.charAt(0))) {
score++;
// Two points for whitespace.
if (Character.isWhitespace(one.charAt(one.length() - 1))
|| Character.isWhitespace(two.charAt(0))) {
score++;
// Three points for line breaks.
if (Character.getType(one.charAt(one.length() - 1)) == Character.CONTROL
|| Character.getType(two.charAt(0)) == Character.CONTROL) {
score++;
// Four points for blank lines.
if (BLANKLINEEND.matcher(one).find()
|| BLANKLINESTART.matcher(two).find()) {
score++;
}
}
}
}
return score;
}
private Pattern BLANKLINEEND
= Pattern.compile("\\n\\r?\\n\\Z", Pattern.DOTALL);
private Pattern BLANKLINESTART
= Pattern.compile("\\A\\r?\\n\\r?\\n", Pattern.DOTALL);
/**
* Reduce the number of edits by eliminating operationally trivial equalities.
* @param diffs LinkedList of Diff objects.
*/
public void diff_cleanupEfficiency(LinkedList<Diff> diffs) {
if (diffs.isEmpty()) {
return;
}
boolean changes = false;
Stack<Diff> equalities = new Stack<Diff>(); // Stack of equalities.
String lastequality = null; // Always equal to equalities.lastElement().text
ListIterator<Diff> pointer = diffs.listIterator();
// Is there an insertion operation before the last equality.
boolean pre_ins = false;
// Is there a deletion operation before the last equality.
boolean pre_del = false;
// Is there an insertion operation after the last equality.
boolean post_ins = false;
// Is there a deletion operation after the last equality.
boolean post_del = false;
Diff thisDiff = pointer.next();
Diff safeDiff = thisDiff; // The last Diff that is known to be unsplitable.
while (thisDiff != null) {
if (thisDiff.operation == Operation.EQUAL) {
// equality found
if (thisDiff.text.length() < Diff_EditCost && (post_ins || post_del)) {
// Candidate found.
equalities.push(thisDiff);
pre_ins = post_ins;
pre_del = post_del;
lastequality = thisDiff.text;
} else {
// Not a candidate, and can never become one.
equalities.clear();
lastequality = null;
safeDiff = thisDiff;
}
post_ins = post_del = false;
} else {
// an insertion or deletion
if (thisDiff.operation == Operation.DELETE) {
post_del = true;
} else {
post_ins = true;
}
/*
* Five types to be split:
* <ins>A</ins><del>B</del>XY<ins>C</ins><del>D</del>
* <ins>A</ins>X<ins>C</ins><del>D</del>
* <ins>A</ins><del>B</del>X<ins>C</ins>
* <ins>A</del>X<ins>C</ins><del>D</del>
* <ins>A</ins><del>B</del>X<del>C</del>
*/
if (lastequality != null
&& ((pre_ins && pre_del && post_ins && post_del)
|| ((lastequality.length() < Diff_EditCost / 2)
&& ((pre_ins ? 1 : 0) + (pre_del ? 1 : 0)
+ (post_ins ? 1 : 0) + (post_del ? 1 : 0)) == 3))) {
//System.out.println("Splitting: '" + lastequality + "'");
// Walk back to offending equality.
while (thisDiff != equalities.lastElement()) {
thisDiff = pointer.previous();
}
pointer.next();
// Replace equality with a delete.
pointer.set(new Diff(Operation.DELETE, lastequality));
// Insert a corresponding an insert.
pointer.add(thisDiff = new Diff(Operation.INSERT, lastequality));
equalities.pop(); // Throw away the equality we just deleted.
lastequality = null;
if (pre_ins && pre_del) {
// No changes made which could affect previous entry, keep going.
post_ins = post_del = true;
equalities.clear();
safeDiff = thisDiff;
} else {
if (!equalities.empty()) {
// Throw away the previous equality (it needs to be reevaluated).
equalities.pop();
}
if (equalities.empty()) {
// There are no previous questionable equalities,
// walk back to the last known safe diff.
thisDiff = safeDiff;
} else {
// There is an equality we can fall back to.
thisDiff = equalities.lastElement();
}
while (thisDiff != pointer.previous()) {
// Intentionally empty loop.
}
post_ins = post_del = false;
}
changes = true;
}
}
thisDiff = pointer.hasNext() ? pointer.next() : null;
}
if (changes) {
diff_cleanupMerge(diffs);
}
}
/**
* Reorder and merge like edit sections. Merge equalities.
* Any edit section can move as long as it doesn't cross an equality.
* @param diffs LinkedList of Diff objects.
*/
public void diff_cleanupMerge(LinkedList<Diff> diffs) {
diffs.add(new Diff(Operation.EQUAL, "")); // Add a dummy entry at the end.
ListIterator<Diff> pointer = diffs.listIterator();
int count_delete = 0;
int count_insert = 0;
String text_delete = "";
String text_insert = "";
Diff thisDiff = pointer.next();
Diff prevEqual = null;
int commonlength;
while (thisDiff != null) {
switch (thisDiff.operation) {
case INSERT:
count_insert++;
text_insert += thisDiff.text;
prevEqual = null;
break;
case DELETE:
count_delete++;
text_delete += thisDiff.text;
prevEqual = null;
break;
case EQUAL:
if (count_delete != 0 || count_insert != 0) {
// Delete the offending records.
pointer.previous(); // Reverse direction.
while (count_delete-- > 0) {
pointer.previous();
pointer.remove();
}
while (count_insert-- > 0) {
pointer.previous();
pointer.remove();
}
if (count_delete != 0 && count_insert != 0) {
// Factor out any common prefixies.
commonlength = diff_commonPrefix(text_insert, text_delete);
if (commonlength != 0) {
if (pointer.hasPrevious()) {
thisDiff = pointer.previous();
assert thisDiff.operation == Operation.EQUAL
: "Previous diff should have been an equality.";
thisDiff.text += text_insert.substring(0, commonlength);
pointer.next();
} else {
pointer.add(new Diff(Operation.EQUAL,
text_insert.substring(0, commonlength)));
}
text_insert = text_insert.substring(commonlength);
text_delete = text_delete.substring(commonlength);
}
// Factor out any common suffixies.
commonlength = diff_commonSuffix(text_insert, text_delete);
if (commonlength != 0) {
thisDiff = pointer.next();
thisDiff.text = text_insert.substring(text_insert.length()
- commonlength) + thisDiff.text;
text_insert = text_insert.substring(0, text_insert.length()
- commonlength);
text_delete = text_delete.substring(0, text_delete.length()
- commonlength);
pointer.previous();
}
}
// Insert the merged records.
if (text_delete.length() != 0) {
pointer.add(new Diff(Operation.DELETE, text_delete));
}
if (text_insert.length() != 0) {
pointer.add(new Diff(Operation.INSERT, text_insert));
}
// Step forward to the equality.
thisDiff = pointer.hasNext() ? pointer.next() : null;
} else if (prevEqual != null) {
// Merge this equality with the previous one.
prevEqual.text += thisDiff.text;
pointer.remove();
thisDiff = pointer.previous();
pointer.next(); // Forward direction
}
count_insert = 0;
count_delete = 0;
text_delete = "";
text_insert = "";
prevEqual = thisDiff;
break;
}
thisDiff = pointer.hasNext() ? pointer.next() : null;
}
// System.out.println(diff);
if (diffs.getLast().text.length() == 0) {
diffs.removeLast(); // Remove the dummy entry at the end.
}
/*
* Second pass: look for single edits surrounded on both sides by equalities
* which can be shifted sideways to eliminate an equality.
* e.g: A<ins>BA</ins>C -> <ins>AB</ins>AC
*/
boolean changes = false;
// Create a new iterator at the start.
// (As opposed to walking the current one back.)
pointer = diffs.listIterator();
Diff prevDiff = pointer.hasNext() ? pointer.next() : null;
thisDiff = pointer.hasNext() ? pointer.next() : null;
Diff nextDiff = pointer.hasNext() ? pointer.next() : null;
// Intentionally ignore the first and last element (don't need checking).
while (nextDiff != null) {
if (prevDiff.operation == Operation.EQUAL &&
nextDiff.operation == Operation.EQUAL) {
// This is a single edit surrounded by equalities.
if (thisDiff.text.endsWith(prevDiff.text)) {
// Shift the edit over the previous equality.
thisDiff.text = prevDiff.text + thisDiff.text.substring(0, thisDiff.text.length() - prevDiff.text.length());
nextDiff.text = prevDiff.text + nextDiff.text;
pointer.previous(); // Walk past nextDiff.
pointer.previous(); // Walk past thisDiff.
pointer.previous(); // Walk past prevDiff.
pointer.remove(); // Delete prevDiff.
pointer.next(); // Walk past thisDiff.
thisDiff = pointer.next(); // Walk past nextDiff.
nextDiff = pointer.hasNext() ? pointer.next() : null;
changes = true;
} else if (thisDiff.text.startsWith(nextDiff.text)) {
// Shift the edit over the next equality.
prevDiff.text += nextDiff.text;
thisDiff.text = thisDiff.text.substring(nextDiff.text.length())
+ nextDiff.text;
pointer.remove(); // Delete nextDiff.
nextDiff = pointer.hasNext() ? pointer.next() : null;
changes = true;
}
}
prevDiff = thisDiff;
thisDiff = nextDiff;
nextDiff = pointer.hasNext() ? pointer.next() : null;
}
// If shifts were made, the diff needs reordering and another shift sweep.
if (changes) {
diff_cleanupMerge(diffs);
}
}
/**
* loc is a location in text1, compute and return the equivalent location in
* text2.
* e.g. "The cat" vs "The big cat", 1->1, 5->8
* @param diffs LinkedList of Diff objects.
* @param loc Location within text1.
* @return Location within text2.
*/
public int diff_xIndex(LinkedList<Diff> diffs, int loc) {
int chars1 = 0;
int chars2 = 0;
int last_chars1 = 0;
int last_chars2 = 0;
Diff lastDiff = null;
for (Diff aDiff : diffs) {
if (aDiff.operation != Operation.INSERT) {
// Equality or deletion.
chars1 += aDiff.text.length();
}
if (aDiff.operation != Operation.DELETE) {
// Equality or insertion.
chars2 += aDiff.text.length();
}
if (chars1 > loc) {
// Overshot the location.
lastDiff = aDiff;
break;
}
last_chars1 = chars1;
last_chars2 = chars2;
}
if (lastDiff != null && lastDiff.operation == Operation.DELETE) {
// The location was deleted.
return last_chars2;
}
// Add the remaining character length.
return last_chars2 + (loc - last_chars1);
}
/**
* Convert a Diff list into a pretty HTML report.
* @param diffs LinkedList of Diff objects.
* @return HTML representation.
*/
public String diff_prettyHtml(LinkedList<Diff> diffs) {
StringBuilder html = new StringBuilder();
int i = 0;
for (Diff aDiff : diffs) {
String text = aDiff.text.replace("&", "&").replace("<", "<")
.replace(">", ">").replace("\n", "¶<BR>");
switch (aDiff.operation) {
case INSERT:
html.append("<INS STYLE=\"background:#E6FFE6;\" TITLE=\"i=").append(i)
.append("\">").append(text).append("</INS>");
break;
case DELETE:
html.append("<DEL STYLE=\"background:#FFE6E6;\" TITLE=\"i=").append(i)
.append("\">").append(text).append("</DEL>");
break;
case EQUAL:
html.append("<SPAN TITLE=\"i=").append(i).append("\">").append(text)
.append("</SPAN>");
break;
}
if (aDiff.operation != Operation.DELETE) {
i += aDiff.text.length();
}
}
return html.toString();
}
/**
* Compute and return the source text (all equalities and deletions).
* @param diffs LinkedList of Diff objects.
* @return Source text.
*/
public String diff_text1(LinkedList<Diff> diffs) {
StringBuilder text = new StringBuilder();
for (Diff aDiff : diffs) {
if (aDiff.operation != Operation.INSERT) {
text.append(aDiff.text);
}
}
return text.toString();
}
/**
* Compute and return the destination text (all equalities and insertions).
* @param diffs LinkedList of Diff objects.
* @return Destination text.
*/
public String diff_text2(LinkedList<Diff> diffs) {
StringBuilder text = new StringBuilder();
for (Diff aDiff : diffs) {
if (aDiff.operation != Operation.DELETE) {
text.append(aDiff.text);
}
}
return text.toString();
}
/**
* Compute the Levenshtein distance; the number of inserted, deleted or
* substituted characters.
* @param diffs LinkedList of Diff objects.
* @return Number of changes.
*/
public int diff_levenshtein(LinkedList<Diff> diffs) {
int levenshtein = 0;
int insertions = 0;
int deletions = 0;
for (Diff aDiff : diffs) {
switch (aDiff.operation) {
case INSERT:
insertions += aDiff.text.length();
break;
case DELETE:
deletions += aDiff.text.length();
break;
case EQUAL:
// A deletion and an insertion is one substitution.
levenshtein += Math.max(insertions, deletions);
insertions = 0;
deletions = 0;
break;
}
}
levenshtein += Math.max(insertions, deletions);
return levenshtein;
}
/**
* Crush the diff into an encoded string which describes the operations
* required to transform text1 into text2.
* E.g. =3\t-2\t+ing -> Keep 3 chars, delete 2 chars, insert 'ing'.
* Operations are tab-separated. Inserted text is escaped using %xx notation.
* @param diffs Array of diff tuples.
* @return Delta text.
*/
public String diff_toDelta(LinkedList<Diff> diffs) {
StringBuilder text = new StringBuilder();
for (Diff aDiff : diffs) {
switch (aDiff.operation) {
case INSERT:
try {
text.append("+").append(URLEncoder.encode(aDiff.text, "UTF-8")
.replace('+', ' ')).append("\t");
} catch (UnsupportedEncodingException e) {
// Not likely on modern system.
throw new Error("This system does not support UTF-8.", e);
}
break;
case DELETE:
text.append("-").append(aDiff.text.length()).append("\t");
break;
case EQUAL:
text.append("=").append(aDiff.text.length()).append("\t");
break;
}
}
String delta = text.toString();
if (delta.length() != 0) {
// Strip off trailing tab character.
delta = delta.substring(0, delta.length() - 1);
delta = unescapeForEncodeUriCompatability(delta);
}
return delta;
}
/**
* Given the original text1, and an encoded string which describes the
* operations required to transform text1 into text2, compute the full diff.
* @param text1 Source string for the diff.
* @param delta Delta text.
* @return Array of diff tuples or null if invalid.
* @throws IllegalArgumentException If invalid input.
*/
public LinkedList<Diff> diff_fromDelta(String text1, String delta)
throws IllegalArgumentException {
LinkedList<Diff> diffs = new LinkedList<Diff>();
int pointer = 0; // Cursor in text1
String[] tokens = delta.split("\t");
for (String token : tokens) {
if (token.length() == 0) {
// Blank tokens are ok (from a trailing \t).
continue;
}
// Each token begins with a one character parameter which specifies the
// operation of this token (delete, insert, equality).
String param = token.substring(1);
switch (token.charAt(0)) {
case '+':
// decode would change all "+" to " "
param = param.replace("+", "%2B");
try {
param = URLDecoder.decode(param, "UTF-8");
} catch (UnsupportedEncodingException e) {
// Not likely on modern system.
throw new Error("This system does not support UTF-8.", e);
} catch (IllegalArgumentException e) {
// Malformed URI sequence.
throw new IllegalArgumentException(
"Illegal escape in diff_fromDelta: " + param, e);
}
diffs.add(new Diff(Operation.INSERT, param));
break;
case '-':
// Fall through.
case '=':
int n;
try {
n = Integer.parseInt(param);
} catch (NumberFormatException e) {
throw new IllegalArgumentException(
"Invalid number in diff_fromDelta: " + param, e);
}
if (n < 0) {
throw new IllegalArgumentException(
"Negative number in diff_fromDelta: " + param);
}
String text;
try {
text = text1.substring(pointer, pointer += n);
} catch (StringIndexOutOfBoundsException e) {
throw new IllegalArgumentException("Delta length (" + pointer
+ ") larger than source text length (" + text1.length()
+ ").", e);
}
if (token.charAt(0) == '=') {
diffs.add(new Diff(Operation.EQUAL, text));
} else {
diffs.add(new Diff(Operation.DELETE, text));
}
break;
default:
// Anything else is an error.
throw new IllegalArgumentException(
"Invalid diff operation in diff_fromDelta: " + token.charAt(0));
}
}
if (pointer != text1.length()) {
throw new IllegalArgumentException("Delta length (" + pointer
+ ") smaller than source text length (" + text1.length() + ").");
}
return diffs;
}
// MATCH FUNCTIONS
/**
* Locate the best instance of 'pattern' in 'text' near 'loc'.
* Returns -1 if no match found.
* @param text The text to search.
* @param pattern The pattern to search for.
* @param loc The location to search around.
* @return Best match index or -1.
*/
public int match_main(String text, String pattern, int loc) {
loc = Math.max(0, Math.min(loc, text.length()));
if (text.equals(pattern)) {
// Shortcut (potentially not guaranteed by the algorithm)
return 0;
} else if (text.length() == 0) {
// Nothing to match.
return -1;
} else if (loc + pattern.length() <= text.length()
&& text.substring(loc, loc + pattern.length()).equals(pattern)) {
// Perfect match at the perfect spot! (Includes case of null pattern)
return loc;
} else {
// Do a fuzzy compare.
return match_bitap(text, pattern, loc);
}
}
/**
* Locate the best instance of 'pattern' in 'text' near 'loc' using the
* Bitap algorithm. Returns -1 if no match found.
* @param text The text to search.
* @param pattern The pattern to search for.
* @param loc The location to search around.
* @return Best match index or -1.
*/
protected int match_bitap(String text, String pattern, int loc) {
assert (Match_MaxBits == 0 || pattern.length() <= Match_MaxBits)
: "Pattern too long for this application.";
// Initialise the alphabet.
Map<Character, Integer> s = match_alphabet(pattern);
// Highest score beyond which we give up.
double score_threshold = Match_Threshold;
// Is there a nearby exact match? (speedup)
int best_loc = text.indexOf(pattern, loc);
if (best_loc != -1) {
score_threshold = Math.min(match_bitapScore(0, best_loc, loc, pattern),
score_threshold);
// What about in the other direction? (speedup)
best_loc = text.lastIndexOf(pattern, loc + pattern.length());
if (best_loc != -1) {
score_threshold = Math.min(match_bitapScore(0, best_loc, loc, pattern),
score_threshold);
}
}
// Initialise the bit arrays.
int matchmask = 1 << (pattern.length() - 1);
best_loc = -1;
int bin_min, bin_mid;
int bin_max = pattern.length() + text.length();
// Empty initialization added to appease Java compiler.
int[] last_rd = new int[0];
for (int d = 0; d < pattern.length(); d++) {
// Scan for the best match; each iteration allows for one more error.
// Run a binary search to determine how far from 'loc' we can stray at
// this error level.
bin_min = 0;
bin_mid = bin_max;
while (bin_min < bin_mid) {
if (match_bitapScore(d, loc + bin_mid, loc, pattern)
<= score_threshold) {
bin_min = bin_mid;
} else {
bin_max = bin_mid;
}
bin_mid = (bin_max - bin_min) / 2 + bin_min;
}
// Use the result from this iteration as the maximum for the next.
bin_max = bin_mid;
int start = Math.max(1, loc - bin_mid + 1);
int finish = Math.min(loc + bin_mid, text.length()) + pattern.length();
int[] rd = new int[finish + 2];
rd[finish + 1] = (1 << d) - 1;
for (int j = finish; j >= start; j--) {
int charMatch;
if (text.length() <= j - 1 || !s.containsKey(text.charAt(j - 1))) {
// Out of range.
charMatch = 0;
} else {
charMatch = s.get(text.charAt(j - 1));
}
if (d == 0) {
// First pass: exact match.
rd[j] = ((rd[j + 1] << 1) | 1) & charMatch;
} else {
// Subsequent passes: fuzzy match.
rd[j] = ((rd[j + 1] << 1) | 1) & charMatch
| (((last_rd[j + 1] | last_rd[j]) << 1) | 1) | last_rd[j + 1];
}
if ((rd[j] & matchmask) != 0) {
double score = match_bitapScore(d, j - 1, loc, pattern);
// This match will almost certainly be better than any existing
// match. But check anyway.
if (score <= score_threshold) {
// Told you so.
score_threshold = score;
best_loc = j - 1;
if (best_loc > loc) {
// When passing loc, don't exceed our current distance from loc.
start = Math.max(1, 2 * loc - best_loc);
} else {
// Already passed loc, downhill from here on in.
break;
}
}
}
}
if (match_bitapScore(d + 1, loc, loc, pattern) > score_threshold) {
// No hope for a (better) match at greater error levels.
break;
}
last_rd = rd;
}
return best_loc;
}
/**
* Compute and return the score for a match with e errors and x location.
* @param e Number of errors in match.
* @param x Location of match.
* @param loc Expected location of match.
* @param pattern Pattern being sought.
* @return Overall score for match (0.0 = good, 1.0 = bad).
*/
private double match_bitapScore(int e, int x, int loc, String pattern) {
float accuracy = (float) e / pattern.length();
int proximity = Math.abs(loc - x);
if (Match_Distance == 0) {
// Dodge divide by zero error.
return proximity == 0 ? accuracy : 1.0;
}
return accuracy + (proximity / (float) Match_Distance);
}
/**
* Initialise the alphabet for the Bitap algorithm.
* @param pattern The text to encode.
* @return Hash of character locations.
*/
protected Map<Character, Integer> match_alphabet(String pattern) {
Map<Character, Integer> s = new HashMap<Character, Integer>();
char[] char_pattern = pattern.toCharArray();
for (char c : char_pattern) {
s.put(c, 0);
}
int i = 0;
for (char c : char_pattern) {
s.put(c, s.get(c) | (1 << (pattern.length() - i - 1)));
i++;
}
return s;
}
// PATCH FUNCTIONS
/**
* Increase the context until it is unique,
* but don't let the pattern expand beyond Match_MaxBits.
* @param patch The patch to grow.
* @param text Source text.
*/
protected void patch_addContext(Patch patch, String text) {
if (text.length() == 0) {
return;
}
String pattern = text.substring(patch.start2, patch.start2 + patch.length1);
int padding = 0;
// Look for the first and last matches of pattern in text. If two different
// matches are found, increase the pattern length.
while (text.indexOf(pattern) != text.lastIndexOf(pattern)
&& pattern.length() < Match_MaxBits - Patch_Margin - Patch_Margin) {
padding += Patch_Margin;
pattern = text.substring(Math.max(0, patch.start2 - padding),
Math.min(text.length(), patch.start2 + patch.length1 + padding));
}
// Add one chunk for good luck.
padding += Patch_Margin;
// Add the prefix.
String prefix = text.substring(Math.max(0, patch.start2 - padding),
patch.start2);
if (prefix.length() != 0) {
patch.diffs.addFirst(new Diff(Operation.EQUAL, prefix));
}
// Add the suffix.
String suffix = text.substring(patch.start2 + patch.length1,
Math.min(text.length(), patch.start2 + patch.length1 + padding));
if (suffix.length() != 0) {
patch.diffs.addLast(new Diff(Operation.EQUAL, suffix));
}
// Roll back the start points.
patch.start1 -= prefix.length();
patch.start2 -= prefix.length();
// Extend the lengths.
patch.length1 += prefix.length() + suffix.length();
patch.length2 += prefix.length() + suffix.length();
}
/**
* Compute a list of patches to turn text1 into text2.
* A set of diffs will be computed.
* @param text1 Old text.
* @param text2 New text.
* @return LinkedList of Patch objects.
*/
public LinkedList<Patch> patch_make(String text1, String text2) {
// No diffs provided, compute our own.
LinkedList<Diff> diffs = diff_main(text1, text2, true);
if (diffs.size() > 2) {
diff_cleanupSemantic(diffs);
diff_cleanupEfficiency(diffs);
}
return patch_make(text1, diffs);
}
/**
* Compute a list of patches to turn text1 into text2.
* text1 will be derived from the provided diffs.
* @param diffs Array of diff tuples for text1 to text2.
* @return LinkedList of Patch objects.
*/
public LinkedList<Patch> patch_make(LinkedList<Diff> diffs) {
// No origin string provided, compute our own.
String text1 = diff_text1(diffs);
return patch_make(text1, diffs);
}
/**
* Compute a list of patches to turn text1 into text2.
* text2 is ignored, diffs are the delta between text1 and text2.
* @param text1 Old text
* @param text2 Ignored.
* @param diffs Array of diff tuples for text1 to text2.
* @return LinkedList of Patch objects.
* @deprecated Prefer patch_make(String text1, LinkedList<Diff> diffs).
*/
public LinkedList<Patch> patch_make(String text1, String text2,
LinkedList<Diff> diffs) {
return patch_make(text1, diffs);
}
/**
* Compute a list of patches to turn text1 into text2.
* text2 is not provided, diffs are the delta between text1 and text2.
* @param text1 Old text.
* @param diffs Array of diff tuples for text1 to text2.
* @return LinkedList of Patch objects.
*/
public LinkedList<Patch> patch_make(String text1, LinkedList<Diff> diffs) {
LinkedList<Patch> patches = new LinkedList<Patch>();
if (diffs.isEmpty()) {
return patches; // Get rid of the null case.
}
Patch patch = new Patch();
int char_count1 = 0; // Number of characters into the text1 string.
int char_count2 = 0; // Number of characters into the text2 string.
// Start with text1 (prepatch_text) and apply the diffs until we arrive at
// text2 (postpatch_text). We recreate the patches one by one to determine
// context info.
String prepatch_text = text1;
String postpatch_text = text1;
for (Diff aDiff : diffs) {
if (patch.diffs.isEmpty() && aDiff.operation != Operation.EQUAL) {
// A new patch starts here.
patch.start1 = char_count1;
patch.start2 = char_count2;
}
switch (aDiff.operation) {
case INSERT:
patch.diffs.add(aDiff);
patch.length2 += aDiff.text.length();
postpatch_text = postpatch_text.substring(0, char_count2)
+ aDiff.text + postpatch_text.substring(char_count2);
break;
case DELETE:
patch.length1 += aDiff.text.length();
patch.diffs.add(aDiff);
postpatch_text = postpatch_text.substring(0, char_count2)
+ postpatch_text.substring(char_count2 + aDiff.text.length());
break;
case EQUAL:
if (aDiff.text.length() <= 2 * Patch_Margin
&& !patch.diffs.isEmpty() && aDiff != diffs.getLast()) {
// Small equality inside a patch.
patch.diffs.add(aDiff);
patch.length1 += aDiff.text.length();
patch.length2 += aDiff.text.length();
}
if (aDiff.text.length() >= 2 * Patch_Margin) {
// Time for a new patch.
if (!patch.diffs.isEmpty()) {
patch_addContext(patch, prepatch_text);
patches.add(patch);
patch = new Patch();
// Unlike Unidiff, our patch lists have a rolling context.
// http://code.google.com/p/google-diff-match-patch/wiki/Unidiff
// Update prepatch text & pos to reflect the application of the
// just completed patch.
prepatch_text = postpatch_text;
char_count1 = char_count2;
}
}
break;
}
// Update the current character count.
if (aDiff.operation != Operation.INSERT) {
char_count1 += aDiff.text.length();
}
if (aDiff.operation != Operation.DELETE) {
char_count2 += aDiff.text.length();
}
}
// Pick up the leftover patch if not empty.
if (!patch.diffs.isEmpty()) {
patch_addContext(patch, prepatch_text);
patches.add(patch);
}
return patches;
}
/**
* Given an array of patches, return another array that is identical.
* @param patches Array of patch objects.
* @return Array of patch objects.
*/
public LinkedList<Patch> patch_deepCopy(LinkedList<Patch> patches) {
LinkedList<Patch> patchesCopy = new LinkedList<Patch>();
for (Patch aPatch : patches) {
Patch patchCopy = new Patch();
for (Diff aDiff : aPatch.diffs) {
Diff diffCopy = new Diff(aDiff.operation, aDiff.text);
patchCopy.diffs.add(diffCopy);
}
patchCopy.start1 = aPatch.start1;
patchCopy.start2 = aPatch.start2;
patchCopy.length1 = aPatch.length1;
patchCopy.length2 = aPatch.length2;
patchesCopy.add(patchCopy);
}
return patchesCopy;
}
/**
* Merge a set of patches onto the text. Return a patched text, as well
* as an array of true/false values indicating which patches were applied.
* @param patches Array of patch objects
* @param text Old text.
* @return Two element Object array, containing the new text and an array of
* boolean values.
*/
public Object[] patch_apply(LinkedList<Patch> patches, String text) {
if (patches.isEmpty()) {
return new Object[]{text, new boolean[0]};
}
// Deep copy the patches so that no changes are made to originals.
patches = patch_deepCopy(patches);
String nullPadding = patch_addPadding(patches);
text = nullPadding + text + nullPadding;
patch_splitMax(patches);
int x = 0;
// delta keeps track of the offset between the expected and actual location
// of the previous patch. If there are patches expected at positions 10 and
// 20, but the first patch was found at 12, delta is 2 and the second patch
// has an effective expected position of 22.
int delta = 0;
boolean[] results = new boolean[patches.size()];
for (Patch aPatch : patches) {
int expected_loc = aPatch.start2 + delta;
String text1 = diff_text1(aPatch.diffs);
int start_loc;
int end_loc = -1;
if (text1.length() > this.Match_MaxBits) {
// patch_splitMax will only provide an oversized pattern in the case of
// a monster delete.
start_loc = match_main(text,
text1.substring(0, this.Match_MaxBits), expected_loc);
if (start_loc != -1) {
end_loc = match_main(text,
text1.substring(text1.length() - this.Match_MaxBits),
expected_loc + text1.length() - this.Match_MaxBits);
if (end_loc == -1 || start_loc >= end_loc) {
// Can't find valid trailing context. Drop this patch.
start_loc = -1;
}
}
} else {
start_loc = match_main(text, text1, expected_loc);
}
if (start_loc == -1) {
// No match found. :(
results[x] = false;
// Subtract the delta for this failed patch from subsequent patches.
delta -= aPatch.length2 - aPatch.length1;
} else {
// Found a match. :)
results[x] = true;
delta = start_loc - expected_loc;
String text2;
if (end_loc == -1) {
text2 = text.substring(start_loc,
Math.min(start_loc + text1.length(), text.length()));
} else {
text2 = text.substring(start_loc,
Math.min(end_loc + this.Match_MaxBits, text.length()));
}
if (text1.equals(text2)) {
// Perfect match, just shove the replacement text in.
text = text.substring(0, start_loc) + diff_text2(aPatch.diffs)
+ text.substring(start_loc + text1.length());
} else {
// Imperfect match. Run a diff to get a framework of equivalent
// indices.
LinkedList<Diff> diffs = diff_main(text1, text2, false);
if (text1.length() > this.Match_MaxBits
&& diff_levenshtein(diffs) / (float) text1.length()
> this.Patch_DeleteThreshold) {
// The end points match, but the content is unacceptably bad.
results[x] = false;
} else {
diff_cleanupSemanticLossless(diffs);
int index1 = 0;
for (Diff aDiff : aPatch.diffs) {
if (aDiff.operation != Operation.EQUAL) {
int index2 = diff_xIndex(diffs, index1);
if (aDiff.operation == Operation.INSERT) {
// Insertion
text = text.substring(0, start_loc + index2) + aDiff.text
+ text.substring(start_loc + index2);
} else if (aDiff.operation == Operation.DELETE) {
// Deletion
text = text.substring(0, start_loc + index2)
+ text.substring(start_loc + diff_xIndex(diffs,
index1 + aDiff.text.length()));
}
}
if (aDiff.operation != Operation.DELETE) {
index1 += aDiff.text.length();
}
}
}
}
}
x++;
}
// Strip the padding off.
text = text.substring(nullPadding.length(), text.length()
- nullPadding.length());
return new Object[]{text, results};
}
/**
* Add some padding on text start and end so that edges can match something.
* Intended to be called only from within patch_apply.
* @param patches Array of patch objects.
* @return The padding string added to each side.
*/
public String patch_addPadding(LinkedList<Patch> patches) {
int paddingLength = this.Patch_Margin;
String nullPadding = "";
for (int x = 1; x <= paddingLength; x++) {
nullPadding += String.valueOf((char) x);
}
// Bump all the patches forward.
for (Patch aPatch : patches) {
aPatch.start1 += paddingLength;
aPatch.start2 += paddingLength;
}
// Add some padding on start of first diff.
Patch patch = patches.getFirst();
LinkedList<Diff> diffs = patch.diffs;
if (diffs.isEmpty() || diffs.getFirst().operation != Operation.EQUAL) {
// Add nullPadding equality.
diffs.addFirst(new Diff(Operation.EQUAL, nullPadding));
patch.start1 -= paddingLength; // Should be 0.
patch.start2 -= paddingLength; // Should be 0.
patch.length1 += paddingLength;
patch.length2 += paddingLength;
} else if (paddingLength > diffs.getFirst().text.length()) {
// Grow first equality.
Diff firstDiff = diffs.getFirst();
int extraLength = paddingLength - firstDiff.text.length();
firstDiff.text = nullPadding.substring(firstDiff.text.length())
+ firstDiff.text;
patch.start1 -= extraLength;
patch.start2 -= extraLength;
patch.length1 += extraLength;
patch.length2 += extraLength;
}
// Add some padding on end of last diff.
patch = patches.getLast();
diffs = patch.diffs;
if (diffs.isEmpty() || diffs.getLast().operation != Operation.EQUAL) {
// Add nullPadding equality.
diffs.addLast(new Diff(Operation.EQUAL, nullPadding));
patch.length1 += paddingLength;
patch.length2 += paddingLength;
} else if (paddingLength > diffs.getLast().text.length()) {
// Grow last equality.
Diff lastDiff = diffs.getLast();
int extraLength = paddingLength - lastDiff.text.length();
lastDiff.text += nullPadding.substring(0, extraLength);
patch.length1 += extraLength;
patch.length2 += extraLength;
}
return nullPadding;
}
/**
* Look through the patches and break up any which are longer than the
* maximum limit of the match algorithm.
* @param patches LinkedList of Patch objects.
*/
public void patch_splitMax(LinkedList<Patch> patches) {
int patch_size;
String precontext, postcontext;
Patch patch;
int start1, start2;
boolean empty;
Operation diff_type;
String diff_text;
ListIterator<Patch> pointer = patches.listIterator();
Patch bigpatch = pointer.hasNext() ? pointer.next() : null;
while (bigpatch != null) {
if (bigpatch.length1 <= Match_MaxBits) {
bigpatch = pointer.hasNext() ? pointer.next() : null;
continue;
}
// Remove the big old patch.
pointer.remove();
patch_size = Match_MaxBits;
start1 = bigpatch.start1;
start2 = bigpatch.start2;
precontext = "";
while (!bigpatch.diffs.isEmpty()) {
// Create one of several smaller patches.
patch = new Patch();
empty = true;
patch.start1 = start1 - precontext.length();
patch.start2 = start2 - precontext.length();
if (precontext.length() != 0) {
patch.length1 = patch.length2 = precontext.length();
patch.diffs.add(new Diff(Operation.EQUAL, precontext));
}
while (!bigpatch.diffs.isEmpty()
&& patch.length1 < patch_size - Patch_Margin) {
diff_type = bigpatch.diffs.getFirst().operation;
diff_text = bigpatch.diffs.getFirst().text;
if (diff_type == Operation.INSERT) {
// Insertions are harmless.
patch.length2 += diff_text.length();
start2 += diff_text.length();
patch.diffs.addLast(bigpatch.diffs.removeFirst());
empty = false;
} else if (diff_type == Operation.DELETE && patch.diffs.size() == 1
&& patch.diffs.getFirst().operation == Operation.EQUAL
&& diff_text.length() > 2 * patch_size) {
// This is a large deletion. Let it pass in one chunk.
patch.length1 += diff_text.length();
start1 += diff_text.length();
empty = false;
patch.diffs.add(new Diff(diff_type, diff_text));
bigpatch.diffs.removeFirst();
} else {
// Deletion or equality. Only take as much as we can stomach.
diff_text = diff_text.substring(0, Math.min(diff_text.length(),
patch_size - patch.length1 - Patch_Margin));
patch.length1 += diff_text.length();
start1 += diff_text.length();
if (diff_type == Operation.EQUAL) {
patch.length2 += diff_text.length();
start2 += diff_text.length();
} else {
empty = false;
}
patch.diffs.add(new Diff(diff_type, diff_text));
if (diff_text.equals(bigpatch.diffs.getFirst().text)) {
bigpatch.diffs.removeFirst();
} else {
bigpatch.diffs.getFirst().text = bigpatch.diffs.getFirst().text
.substring(diff_text.length());
}
}
}
// Compute the head context for the next patch.
precontext = diff_text2(patch.diffs);
precontext = precontext.substring(Math.max(0, precontext.length()
- Patch_Margin));
// Append the end context for this patch.
if (diff_text1(bigpatch.diffs).length() > Patch_Margin) {
postcontext = diff_text1(bigpatch.diffs).substring(0, Patch_Margin);
} else {
postcontext = diff_text1(bigpatch.diffs);
}
if (postcontext.length() != 0) {
patch.length1 += postcontext.length();
patch.length2 += postcontext.length();
if (!patch.diffs.isEmpty()
&& patch.diffs.getLast().operation == Operation.EQUAL) {
patch.diffs.getLast().text += postcontext;
} else {
patch.diffs.add(new Diff(Operation.EQUAL, postcontext));
}
}
if (!empty) {
pointer.add(patch);
}
}
bigpatch = pointer.hasNext() ? pointer.next() : null;
}
}
/**
* Take a list of patches and return a textual representation.
* @param patches List of Patch objects.
* @return Text representation of patches.
*/
public String patch_toText(List<Patch> patches) {
StringBuilder text = new StringBuilder();
for (Patch aPatch : patches) {
text.append(aPatch);
}
return text.toString();
}
/**
* Parse a textual representation of patches and return a List of Patch
* objects.
* @param textline Text representation of patches.
* @return List of Patch objects.
* @throws IllegalArgumentException If invalid input.
*/
public List<Patch> patch_fromText(String textline)
throws IllegalArgumentException {
List<Patch> patches = new LinkedList<Patch>();
if (textline.length() == 0) {
return patches;
}
List<String> textList = Arrays.asList(textline.split("\n"));
LinkedList<String> text = new LinkedList<String>(textList);
Patch patch;
Pattern patchHeader
= Pattern.compile("^@@ -(\\d+),?(\\d*) \\+(\\d+),?(\\d*) @@$");
Matcher m;
char sign;
String line;
while (!text.isEmpty()) {
m = patchHeader.matcher(text.getFirst());
if (!m.matches()) {
throw new IllegalArgumentException(
"Invalid patch string: " + text.getFirst());
}
patch = new Patch();
patches.add(patch);
patch.start1 = Integer.parseInt(m.group(1));
if (m.group(2).length() == 0) {
patch.start1--;
patch.length1 = 1;
} else if ("0".equals(m.group(2))) {
patch.length1 = 0;
} else {
patch.start1--;
patch.length1 = Integer.parseInt(m.group(2));
}
patch.start2 = Integer.parseInt(m.group(3));
if (m.group(4).length() == 0) {
patch.start2--;
patch.length2 = 1;
} else if ("0".equals(m.group(4))) {
patch.length2 = 0;
} else {
patch.start2--;
patch.length2 = Integer.parseInt(m.group(4));
}
text.removeFirst();
while (!text.isEmpty()) {
try {
sign = text.getFirst().charAt(0);
} catch (IndexOutOfBoundsException e) {
// Blank line? Whatever.
text.removeFirst();
continue;
}
line = text.getFirst().substring(1);
line = line.replace("+", "%2B"); // decode would change all "+" to " "
try {
line = URLDecoder.decode(line, "UTF-8");
} catch (UnsupportedEncodingException e) {
// Not likely on modern system.
throw new Error("This system does not support UTF-8.", e);
} catch (IllegalArgumentException e) {
// Malformed URI sequence.
throw new IllegalArgumentException(
"Illegal escape in patch_fromText: " + line, e);
}
if (sign == '-') {
// Deletion.
patch.diffs.add(new Diff(Operation.DELETE, line));
} else if (sign == '+') {
// Insertion.
patch.diffs.add(new Diff(Operation.INSERT, line));
} else if (sign == ' ') {
// Minor equality.
patch.diffs.add(new Diff(Operation.EQUAL, line));
} else if (sign == '@') {
// Start of next patch.
break;
} else {
// WTF?
throw new IllegalArgumentException(
"Invalid patch mode '" + sign + "' in: " + line);
}
text.removeFirst();
}
}
return patches;
}
/**
* Class representing one diff operation.
*/
public static class Diff {
/**
* One of: INSERT, DELETE or EQUAL.
*/
public Operation operation;
/**
* The text associated with this diff operation.
*/
public String text;
/**
* Constructor. Initializes the diff with the provided values.
* @param operation One of INSERT, DELETE or EQUAL.
* @param text The text being applied.
*/
public Diff(Operation operation, String text) {
// Construct a diff with the specified operation and text.
this.operation = operation;
this.text = text;
}
/**
* Display a human-readable version of this Diff.
* @return text version.
*/
@Override
public String toString() {
String prettyText = this.text.replace('\n', '\u00b6');
return "Diff(" + this.operation + ",\"" + prettyText + "\")";
}
/**
* Is this Diff equivalent to another Diff?
* @param d Another Diff to compare against.
* @return true or false.
*/
@Override
public boolean equals(Object d) {
try {
return (((Diff) d).operation == this.operation)
&& (((Diff) d).text.equals(this.text));
} catch (ClassCastException e) {
return false;
}
}
}
/**
* Class representing one patch operation.
*/
public static class Patch {
public LinkedList<Diff> diffs;
public int start1;
public int start2;
public int length1;
public int length2;
/**
* Constructor. Initializes with an empty list of diffs.
*/
public Patch() {
this.diffs = new LinkedList<Diff>();
}
/**
* Emmulate GNU diff's format.
* Header: @@ -382,8 +481,9 @@
* Indicies are printed as 1-based, not 0-based.
* @return The GNU diff string.
*/
@Override
public String toString() {
String coords1, coords2;
if (this.length1 == 0) {
coords1 = this.start1 + ",0";
} else if (this.length1 == 1) {
coords1 = Integer.toString(this.start1 + 1);
} else {
coords1 = (this.start1 + 1) + "," + this.length1;
}
if (this.length2 == 0) {
coords2 = this.start2 + ",0";
} else if (this.length2 == 1) {
coords2 = Integer.toString(this.start2 + 1);
} else {
coords2 = (this.start2 + 1) + "," + this.length2;
}
StringBuilder text = new StringBuilder();
text.append("@@ -").append(coords1).append(" +").append(coords2)
.append(" @@\n");
// Escape the body of the patch with %xx notation.
for (Diff aDiff : this.diffs) {
switch (aDiff.operation) {
case INSERT:
text.append('+');
break;
case DELETE:
text.append('-');
break;
case EQUAL:
text.append(' ');
break;
}
try {
text.append(URLEncoder.encode(aDiff.text, "UTF-8").replace('+', ' '))
.append("\n");
} catch (UnsupportedEncodingException e) {
// Not likely on modern system.
throw new Error("This system does not support UTF-8.", e);
}
}
return unescapeForEncodeUriCompatability(text.toString());
}
}
/**
* Unescape selected chars for compatability with JavaScript's encodeURI.
* In speed critical applications this could be dropped since the
* receiving application will certainly decode these fine.
* Note that this function is case-sensitive. Thus "%3f" would not be
* unescaped. But this is ok because it is only called with the output of
* URLEncoder.encode which returns uppercase hex.
*
* Example: "%3F" -> "?", "%24" -> "$", etc.
*
* @param str The string to escape.
* @return The escaped string.
*/
private static String unescapeForEncodeUriCompatability(String str) {
return str.replace("%21", "!").replace("%7E", "~")
.replace("%27", "'").replace("%28", "(").replace("%29", ")")
.replace("%3B", ";").replace("%2F", "/").replace("%3F", "?")
.replace("%3A", ":").replace("%40", "@").replace("%26", "&")
.replace("%3D", "=").replace("%2B", "+").replace("%24", "$")
.replace("%2C", ",").replace("%23", "#");
}
public String getHtmlDiffString(String text1,String text2){
return diff_prettyHtml(diff_main(text1,text2));
}
}
2.3 实现自定义动态计算列宽度
在生成对比结果Excel文件中,需要根据不同的内容动态计算列宽,详细代码如下:
package com.demo.common.excel;
import com.alibaba.excel.metadata.Head;
import com.alibaba.excel.metadata.data.WriteCellData;
import com.alibaba.excel.write.metadata.holder.WriteSheetHolder;
import com.alibaba.excel.write.style.column.AbstractColumnWidthStyleStrategy;
import org.apache.poi.ss.usermodel.Cell;
import java.util.List;
/**
* 导出表格宽度设置
*/
public class LongestCellWidthHandler extends AbstractColumnWidthStyleStrategy {
/*列宽计算逻辑:以下标为1的列的宽度计算逻辑说明下,正常情况下设置的列宽是33乘以256,
但实际上我们生成的excel中列宽是32.22,因为字体样式、大小以及单元格边框等占用额外的像素,
所以实际的列宽比代码中设置的列宽要小0.78英寸(excel中的列宽单位是英寸),代码中设置的33也是英寸单位,
那么实际我们需要设置成33.78英寸,但33.78乘以256是Double类型的数值,
setColumnWidth的第二个参数必须是整数,所以在33.78*256=8647.68的基础上向上取整为8648*//*
*/
@Override
protected void setColumnWidth(WriteSheetHolder writeSheetHolder, List<WriteCellData<?>> cellDataList, Cell cell, Head head, Integer relativeRowIndex, Boolean isHead) {
if (Boolean.TRUE.equals(isHead)) {
int columnWidth = cell.getStringCellValue().length();
columnWidth = Math.max(columnWidth * 5, 20);
if (columnWidth > 255) {
columnWidth = 255;
}
writeSheetHolder.getSheet().setColumnWidth(cell.getColumnIndex(), "对比结果".equals(cell.getStringCellValue().trim()) ? 12800 : columnWidth * 256);
writeSheetHolder.getSheet().setColumnWidth(cell.getColumnIndex(), "参考文件".equals(cell.getStringCellValue().trim()) ? 12800 : columnWidth * 256);
}
}
}
2.4 实现Excel特定列的样式
比对结果为富文本样式,需要对Excel制定列的样式进行特殊处理,具体代码如下:
import com.alibaba.excel.metadata.Head;
import com.alibaba.excel.metadata.data.WriteCellData;
import com.alibaba.excel.write.handler.CellWriteHandler;
import com.alibaba.excel.write.metadata.holder.WriteSheetHolder;
import com.alibaba.excel.write.metadata.holder.WriteTableHolder;
import com.alibaba.fastjson.JSON;
import com.demmo.common.utils.DiffMatchPatch;
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.ss.util.CellAddress;
import org.apache.poi.xssf.usermodel.XSSFRichTextString;
import java.util.List;
/**
* 自定义导出样式
*/
public class CustomCellWriteHandler implements CellWriteHandler {
@Override
public void afterCellDispose(WriteSheetHolder writeSheetHolder, WriteTableHolder writeTableHolder, List<WriteCellData<?>> cellDataList, Cell cell, Head head, Integer relativeRowIndex, Boolean isHead) {
CellAddress address = cell.getAddress();
int column = address.getColumn();
if (!isHead && (column == 1)) {//指定那些列需要做定制化样式
Sheet sheet = writeSheetHolder.getSheet();
Workbook workbook = sheet.getWorkbook();
// xlsx格式,如果是老版本格式的话就用 HSSFRichTextString
String stringCellValue = cell.getStringCellValue();
try {
List<DiffMatchPatch.Diff> diffs = JSON.parseArray(stringCellValue, DiffMatchPatch.Diff.class);
XSSFRichTextString richString = new XSSFRichTextString(cell.getStringCellValue());
// 再设置回每个单元格里
cell.setCellValue(diff_prettyHtml(diffs, workbook, richString, cell));
} catch (Exception e) {
System.out.println("stringCellValue:" + stringCellValue);
}
}
}
public XSSFRichTextString diff_prettyHtml(List<DiffMatchPatch.Diff> diffs, Workbook workbook, XSSFRichTextString richString, Cell cell) {
int i = 0;
StringBuffer sourceBuffer = new StringBuffer("");
for (DiffMatchPatch.Diff diff : diffs) {
sourceBuffer.append(diff.text);
}
richString.setString(sourceBuffer.toString());
for (DiffMatchPatch.Diff aDiff : diffs) {
int startIndex = i;
i += aDiff.text.length();
int endIndex = i;
switch (aDiff.operation) {
case INSERT:
Font font = workbook.createFont();
font.setColor(IndexedColors.SKY_BLUE.index);
richString.applyFont(startIndex, endIndex, font);
break;
case DELETE:
Font font2 = workbook.createFont();
font2.setColor(Font.COLOR_RED);
font2.setStrikeout(true);
richString.applyFont(startIndex, endIndex, font2);
break;
case EQUAL:
Font font3 = workbook.createFont();
richString.applyFont(startIndex, endIndex, font3);
break;
}
}
return richString;
}
}
2.5 编写测试程序,查看效果
可自行编写测试程序,查看完整的效果。这里简单举例,具体代码如下:
import com.demo.common.excel.CellStyleUtils;
import com.demo.common.excel.CustomCellWriteHandler;
import com.demo.common.excel.LongestCellWidthHandler;
import com.demo.common.utils.DiffMatchPatch;
import com.demo.common.utils.JsonUtils;
import com.demo.common.utils.MapUtils;
import com.demo.common.utils.StringUtils;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.*;
public class ExcelDiffExportDemo {
public static void main(String[] args){
List<Map<String,String>> list=new ArrayList<>();
Map<String,String> mapObj1=new HashMap<>();
mapObj1.put("name","张三");
mapObj1.put("like1","我喜欢吃苹果");
mapObj1.put("like2","我喜欢吃草莓");
list.add(mapObj1);
Map<String,String> mapObj2=new HashMap<>();
mapObj2.put("name","李四");
mapObj2.put("like1","我喜欢吃西瓜");
mapObj2.put("like2","我喜欢吃西瓜和草莓");
list.add(mapObj2);
Map<String,String> mapObj3=new HashMap<>();
mapObj3.put("name","王五");
mapObj3.put("like2","我喜欢吃苹果");
mapObj3.put("like1","我不喜欢吃苹果,喜欢吃香蕉");
list.add(mapObj3);
List<List<String>> exportData = new ArrayList<>();
for (Map<String,String> mapObj : list) {
DiffMatchPatch dmp = new DiffMatchPatch();
System.out.println(mapObj);
LinkedList<DiffMatchPatch.Diff> diffs = dmp.diff_main(MapUtils.getValueString(mapObj,"like1"), MapUtils.getValueString(mapObj,"like2"));
List<String> itemList = new ArrayList<>();
itemList.add(MapUtils.getValueString(mapObj,"name"));
itemList.add(JsonUtils.toJsonString(diffs));
exportData.add(itemList);
}
String fileName="水果喜好";
List<List<String>> headList=new ArrayList<List<String>>();
List<String> head1 = new ArrayList<>();
head1.add(fileName);
head1.add("姓名");
List<String> head2 = new ArrayList<>();
head2.add(fileName);
head2.add("爱好对比结果");
headList.add(head1);
headList.add(head2);
FileOutputStream outputStream = null;
try {
outputStream = new FileOutputStream(new File("D:\\doc\\202304\\like.xlsx"));
EasyExcel.write(outputStream).inMemory(true).registerWriteHandler(CellStyleUtils.getHorizontalCellStyleStrategy())
.registerWriteHandler(new LongestCellWidthHandler()).registerWriteHandler(new CustomCellWriteHandler())
.head(headList).sheet("小朋友水果爱好比对").doWrite(exportData);
outputStream.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
// 关闭文件流
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
以上是完整的实现过程和代码,相信JAVA开发的小伙伴们一定用的上。















 611
611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









