







一、高可用集群简介
1、高可用概念
高可用集群( High Availability Cluster, HA 集群),其中高可用的含义是最大限度地可以使用。从集群的名字上可以看出,此类集群实现的功能是保障用户的应用程序持久、不间断地提供服务。 当应用程序出现故障或者系统硬件、网络出现故障时,应用可以自动、快速从一个节点切换到另一个节点,从而保证应用持续、不间断地对外提供服务,这就是高可用集群实现的功能 。
2、常见的HA集群
我们常说的双机热备、双机互备、多机互备等都属于高可用集群的范畴,这类集群一般都由两个或两个以上节点组成。典型的双机热备结构如下图所示 :

3、高可用集群软件
高可用集群一般是通过高可用软件来实现的。在 Linux 下常用的高可用软件有开源HeartBeatHA、 Red Hat 提供的 RHCS、商业软件 ROSE、Keepalived、pacemaker 等。
4、心跳监测与漂移IP地址
(1)心跳监测
为了能实现负载均衡、提供高可用服务和执行错误恢复,集群系统提供了心跳监测技术。心跳监测是通过心跳线实现的,可以做心跳线的设备有 RS232 串口线,也可以用独立的一块网卡来跑心跳,还可以共享磁盘阵列等。心跳线的数量应该为集群节点数减 I。需要注意的 是,如果通过网卡来做心跳,每个节点需要两块网卡。其中,一块作为私有网络直接连接到对方机器相应的网卡,用来监测对方心跳。另外一块连接到公共网络对外提供服务,同时心跳网卡和服务网卡的 IP 地址尽量不要在一个网段内。心跳监控的效率直接影响故障切换时间的长短,集群系统正是通过心跳技术保持节点间内部通信的有效性 。
(2)漂移 IP 地址
在集群系统中,除了每个服务节点自身的真实 IP 地址外,还存在一个漂移 1P 地址。为什么说是漂移 IP 地址呢?因为这个 IP 地址并不固定。例如,在两个节点的双机热备中,正常状态下,这个漂移 1P 地址位于主节点上,当主节点出现故障后,漂移 IP 地址自动切换到备用节点。因此,为了保证服务的不间断性,在集群系统中,对外提供的服务 IP 地址一定要是这个漂移 IP 地址。虽然节点本身的 IP 地址也能对外提供服务,但是当此节点失效后,服务切换到了另一个节点,连接服务的 IP 地址仍然是故障节点的 IP 地址,此时,服务就随之中断。
二、keepalived服务介绍
Keepalived起初是为LVS设计的,专门用来监控集群系统中各个服务节点的状态,后来有加入VRRP的功能,VRRP是Virtual Router Redundancy protocol(虚拟路由器冗余协议)的缩写,VRRP出现的目的就是为了解决静态路由器出现的单点故障问题,它能偶保证网络的不间断、稳定的运行。所有,keepalived一方面具有LVS cluster nodes healthchecks功能,另一方面也具有LVS directors faiover功能。
三、keepalived服务的两大用途
1、LVS directors failover功能
Ha failover功能:实现LB Master主机和Backup主机之间故障转移和自动切换。
这是针对有两个负载均衡器Director同时工作而采取的故障转移措施。当主负载均衡器(MASTER)失效或出现故障时,备份负载均衡器(BACKUP)将自动接管主负载均衡器的所有工作;一旦主负载均衡器(MASTER)故障修复,MASTER又会接管回它原来处理的工作,而备份负载均衡管理器(BACKUP)会释放master失效时它接管的工作,此时两者将恢复到最初各自的角色状态。
LVS directors failover功能原理图:
图一:keepalived集群正常工作双主架构简图
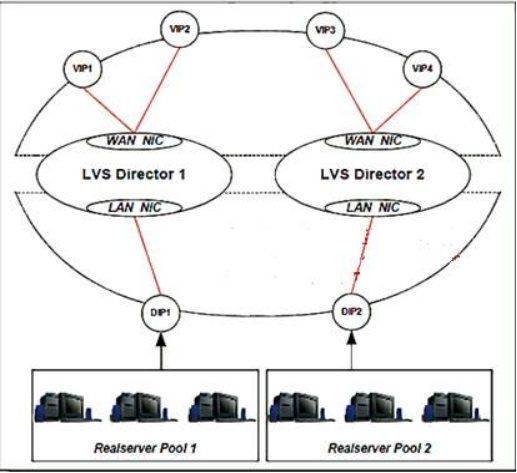
图二:keepalived集群LVS director2宕机状态
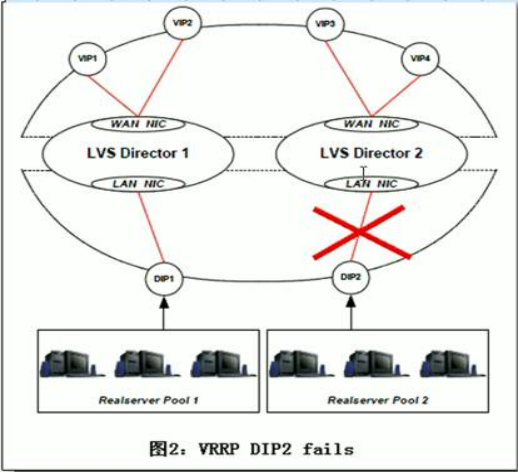
图三:keepalived集群DIP2 takeover图
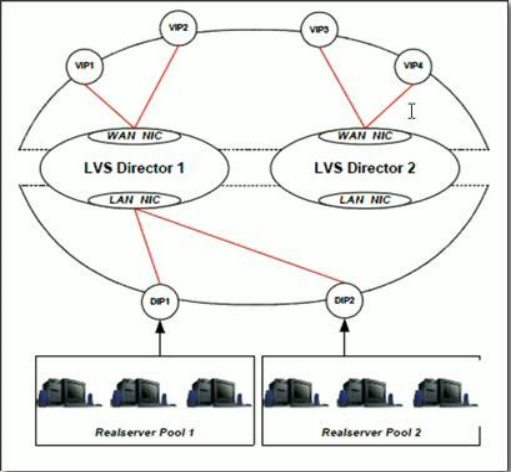
图四:keepalived集群takeover后正常架构简图
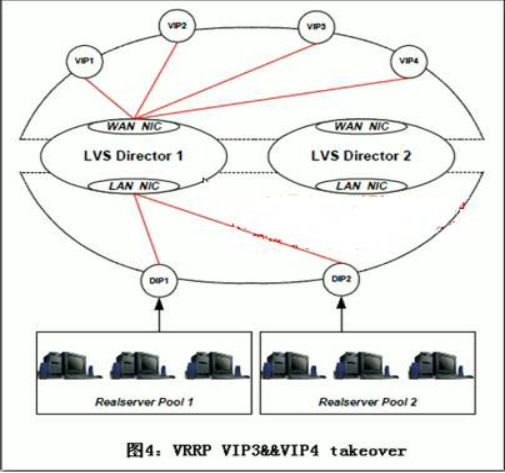
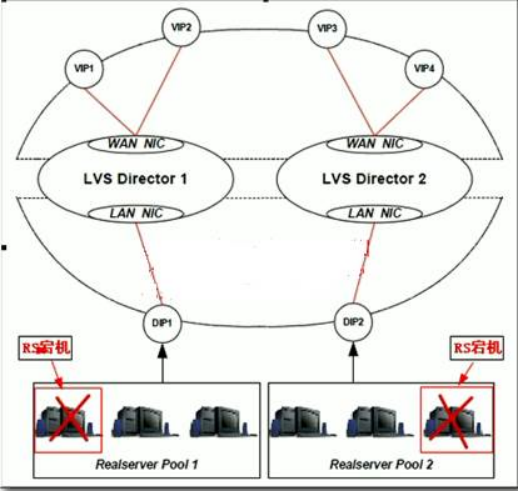
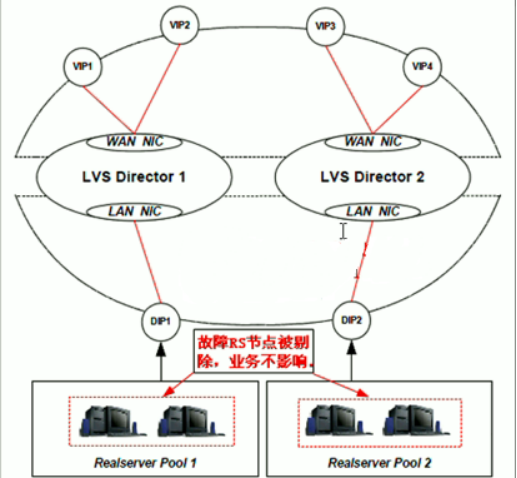
2、LVS cluster nodes healthchecks功能
rs healthcheck功能:负载均衡定期检查RS的可用性决定是否非其分发请求。
当虚拟服务器中的某一个甚至是几个真实服务器同时发生故障无法提供服务时,负载均衡器会自动将失效的服务器从转发队列中清除出去,从而保证用户的访问不受影响;当故障的服务器被修复以后,系统又会自动地把他们加入转发队列,分发请求提供正常服务。
LVS cluster nodes healthchecks功能原理图:
图一:keepalived集群双主LVS cluser nodes意外宕机示意图
图二:keepalived集群双主LVS cluster nodes意外宕机RS自动清理示意图
四、keepalived故障切换转移原理介绍
Keepalived dirctors之间的故障切换转移,是通过VRRP协议来实现的。
在keepalived directors正常工作时,主Directors节点会不断的向备节点广播心跳信息,用以告诉备节点自己还活着,当主节点发生故障时,备节点就无法继续检测到主节点的心跳,进而调用自身的接管程序,接管主节点的IP资源及服务。而当主节点恢复故障时,备节点会释放主节点故障时,备节点会释放主节点故障时自身接管的IP资源及服务,恢复到原来的自身的备用角色。
五、VRRP协议简单介绍
vrrp协议,英文名称:Virtual Router Redundancy Protocol,中文名称:虚拟路由器冗余协议。vrrp出现就是为了解决静态路由的单点故障,vrrp是通过一种竞选协议机制来将路由任务交给某台vrrp路由器。
(1)MASTER和BACKUP
在一个VRRP虚拟路由器中,有多台物理的VRRP路由器,但是这多台物理的机器并不同时工作,而是由一台称为MASTER的负责路由工作,其他的都是BACKUP,MASTER并非一成不变,VRRP协议让每个VRRP路由器参与竞选,最终获胜的就是MASTER。MASTER有一些特权,比如拥有虚拟路由器的IP地址,我们的主机就是用这个IP地址作为静态路由的。拥有特权的MASTER要负责转发发送给网关地址的包和响应ARP请求。
VRRP通过竞选协议来实现虚拟路由器的功能,所有的协议报文都是通过IP多播(multicast)包(多播地址224.0.0.18)形式发送的。虚拟路由器有VRID(范围0-255)和一组IP地址组成,对外表现为一个周知的MAC地址:00-00-5E-00-01{VRID}。所有,在一个虚拟路由器中,不管谁是MASTER,对外都是相同的MAC和IP(称之为VIP)。客户端主机并不需要因为MASTER的改变而修改自己的路由配置,对他们来说,这周主从的切换时透明的。
在一个虚拟路由器中,只有作为MASTER的VRRP路由器会一直发送VRRP广告包(VRRP Advertisement message),BACKUP不会抢占MASTER,除非它的优先级(priority)更高。当MASTER不可用时(BACKUP收不到广告包),多台BACKUP中优先级最高的这台会被抢占为MASTER。这种抢占式非常快速的(<1s),以保证服务的连续性。
出于安全性考虑,VRRP包使用了加密协议进行加密。
六、keepaliived主要特点
1)Keepalived是LVS的扩展项目,因此它们之间具备良好的兼容性。 这点应该是 Keepalived部署比其他类似工具更简洁的原因,尤其是相对于Heartbeat而言,Heartbeat作为HA软件,其复杂的配置流程让许多人望而生畏。
2)通过对服务器池对象的健康检查,实现对失效机器/服务的故障隔离。
3)负载均衡器之间的失败切换,是通过VRRPv2(Virtual Router Redundancy Protocol)stack实现的,VRRP当初被设计出来就是为了解决静态路由器的单点故障问题。
4)iptables的启用是不会影响Keepalived的运行的。 但为了更好的性能,我们通常会将整套系统内所有主机的iptables都停用。
5)Keepalived产生的VIP就是整个系统对外的IP,如果最外端的防火墙采用的是路由模式,那就映射此内网IP为公网IP。

















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









