







转自 http://blog.csdn.net/yusiguyuan/article/details/17591613
一、3点基础知识
一、3点基础知识
1、一个主机的端口号为所有进程所共享,但普通用户进程绑定不了一些特殊端口号如20、80等。
2、每个进程都有自己的文件描述符(包括file fd, socket fd, timer fd, event fd, signal fd),一般是1024,可以通过ulimit -n 设置,但所有进程打开的文件描述符总数有上限,跟主机的内存有关。
3、一个进程内的所有线程共享进程的文件描述符。
二、常见并发服务器方案:
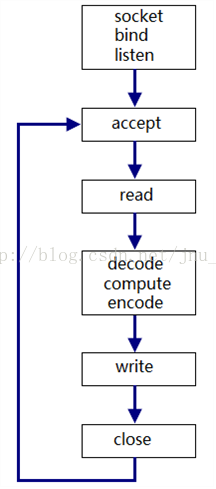
无法充分利用多核CPU,不适合执行时间较长的服务,即适用于短连接。如果是长连接则需要在read/write之间循环,那么只能服务一个客户端。
2、并发式(concurrent)服务器
one connection per process/one connection per thread
one connection per process/one connection per thread
适合执行时间比较长的服务
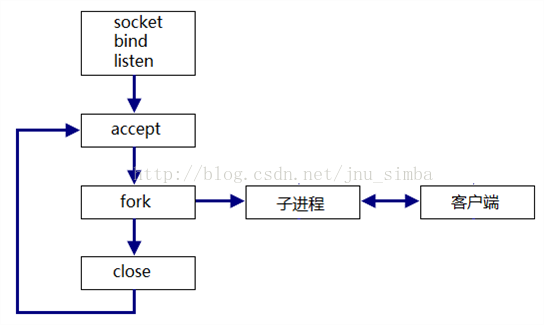
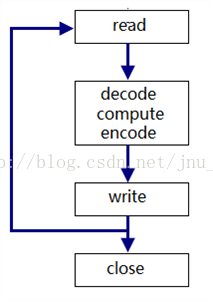
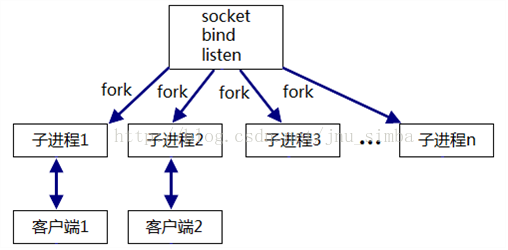
one connection per process : 主进程每次fork 之后要关闭connfd,子进程要关闭listenfd
one connection per thread : 主线程每次accept 回来就创建一个子线程服务,由于线程共享文件描述符,故不用关闭。
3、prefork or pre threaded(UNP2e 第27章)(容易发生“惊群”现象,即多个子进程都处于accept状态)
4、反应式( reactive )服务器 (reactor模式)(select/poll/epoll)
并发处理多个请求,实际上是在一个线程中完成。无法充分利用多核CPU
不适合执行时间比较长的服务,所以为了让客户感觉是在“并发”处理而不是“循环”处理,每个请求必须在相对较短时间内执行。
并发处理多个请求,实际上是在一个线程中完成。无法充分利用多核CPU
不适合执行时间比较长的服务,所以为了让客户感觉是在“并发”处理而不是“循环”处理,每个请求必须在相对较短时间内执行。
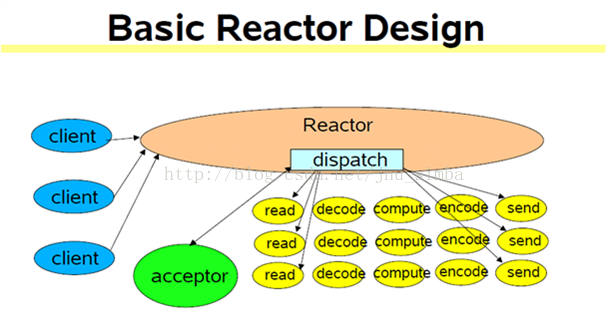
5、reactor + thread per request(过渡方案)
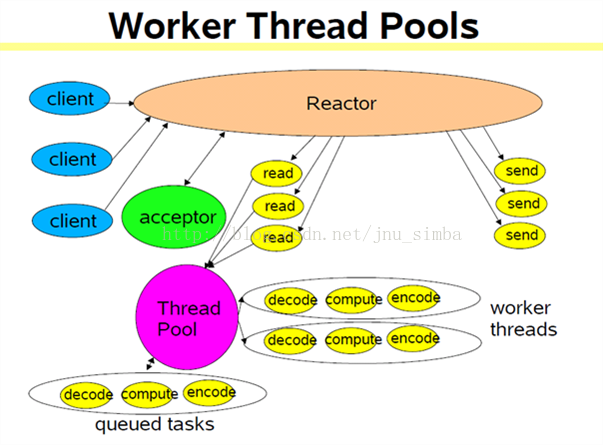
6、reactor + worker thread(过渡方案)
7、reactor + thread pool(能适应密集计算)
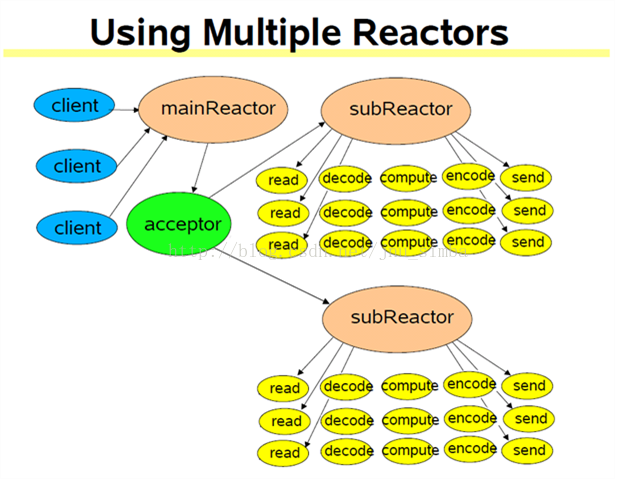
8、multiple reactors(能适应更大的突发I/O)
reactors in threads(one loop per thread)
reactors in processes
reactors in processes
一般来说一个subReactor适用于一个千兆网口
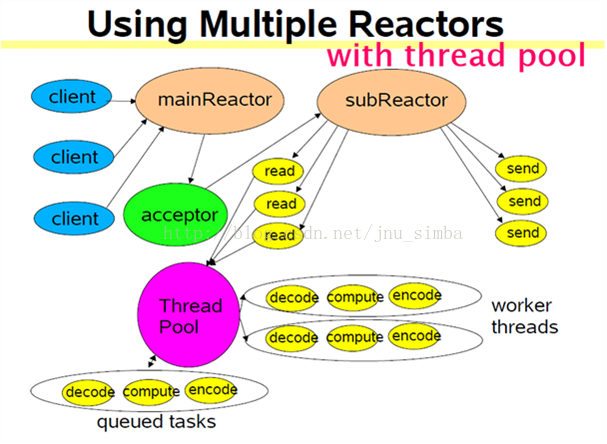
9、multiple reactors + thread pool(one loop per thread + threadpool)(突发I/O与密集计算)
subReactor可以有多个,但threadpool只有一个。
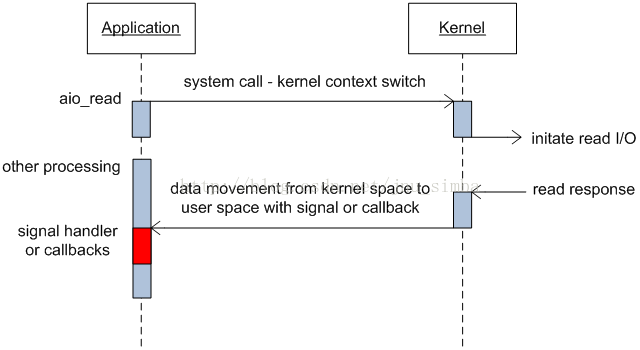
10、proactor服务器(proactor模式,基于异步I/O)
理论上proactor比reactor效率要高一些异步I/O能够让I/O操作与计算重叠。充分利用DMA特性。Linux异步IO
glibc aio(aio_*),有bugkernel native aio(io_*),也不完美。目前仅支持 O_DIRECT 方式来对磁盘读写,跳过系统缓存。要自已实现缓存,难度不小。
boost asio实现的proactor,实际上不是真正意义上的异步I/O,底层是用epoll来实现的,模拟异步I/O的。
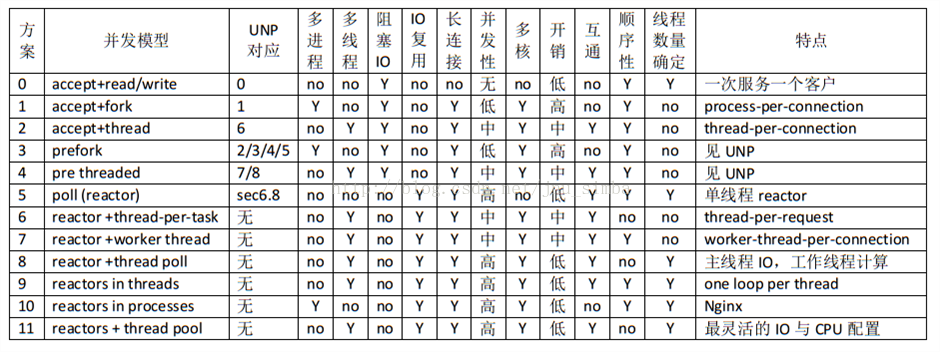
常见并发服务器方案比较:















 4423
4423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









