







- 目录
- 概述
- Tutorial
- Part 1 - Creating the Count Matrix
- Part 2 - Modify the Counts with TFIDF
- Part 3 - Using the Singular Value Decomposition
- Part 4 - Clustering by Color
- Part 5 - Clustering by Value
- Advantages Disadvantages and Applications of LSA
- References Resources
-
概述
这一篇关于关于潜在语义分析LSA(Latent Semantic Analysis )的文章,文章较为详细地介绍LSA的工作原理,并有一个基于pyhon的源码剖析,整体来说是否浅白,原文地址在这里,有兴趣的同学可以直接阅读。下面是对文章翻译,由于本人不是做文本分析,不到位的地方欢迎指教。
转载请注明出处: http://blog.csdn.net/zhzhji440Tutorial
潜在语义分析LSA(Latent Semantic Analysis )也叫作潜在语义索引LSI( Latent Semantic Indexing ) 顾名思义是通过分析文章(documents )来挖掘文章的潜在意思或语义(concepts )。如果每个单词都仅以着一个语义,同时每个语义仅仅由一个单词来表示,那么LSA将十分简单,即简单地将进行语义和单词间的映射。
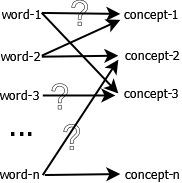
不幸的是,LSA并没有这么简单。因为不同的单词可以表示同一个语义,或一个单词同时具有多个不同的意思,这些的模糊歧义使语义的准确识别变得十分困难。
例如,bank 这个单词如果和mortgage, loans, rates 这些单词同时出现时,bank 很可能表示金融机构的意思。可是如果bank 这个单词和lures, casting, fish一起出现,那么很可能表示河岸的意思
LSA的工作原理: How Latent Semantic Analysis Works
LSA目的是解决如通过搜索词/关键词(search words)定位出相关文章。如何通过对比单词来定位文章是一个难点,因为我们正在要做的是对比单词背后的语义。潜在语义分析的基本原理是将文章和单词懂映射到语义空间( “concept” space )上,并在该空间进行对比分析。
由于作家在创作文章可以随意地选择各种单词来表达,因此不同的作家的词语选择风格都大不相同,表达的语义也因此变得模糊。这种单词选择的随机性必然将噪声的引入到“单词-语义关系”(word-concept relationship)。LSA能过滤掉一些噪声,同时能在语料库中找出一个最小的语义子集( to find the smallest set of concepts that spans all the documents)。为了让问题变得课解,LSA引入了一些重要的假设
- 文章通过”bags of words”的形式来表示,也就是说单词的出现顺数并不重要,而与单词在文中出现的次数相关
- 语义通过一组最有可能同时出现的单词来表示。例如”leash”, “treat”, “obey” 常出现在关于 dog training的文章里面。
- 每个单词假设只有一个意思,当然这个假设在遇到““banks””(既表示河岸也表示金融银行)这种情况当然不合适,但是这个假设将有助于简化问题难度。
实例:A Small Example
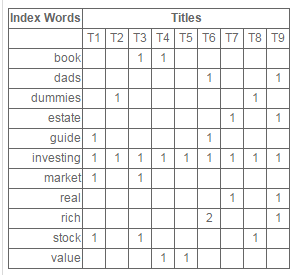
一个简单的例子是,当在Amazon.com上搜索“investing”时将返回10个书名,这些书名都有共同一个索引词(index word)。一个索引词可以是符合以下条件的如何单词:
- 出现在2个或以上的文章题目中
- 停止词:词意不过于一般,如“and”, “the”等( (known as stop words))。这些词对文章的语音并没起到突出的作用,因此应该被过滤掉。
在本例中,我们将过滤掉以下单词: “and”, “edition”, “for”, “in”, “little”, “of”, “the”, “to”
这里有9个标题。斜体的都是索引词(出现在2个或以上的文章题目中而且不是停止词)- The Neatest Little Guide to Stock Market Investing
- Investing**For **Dummies, 4th Edition
- The Little Book**of Common Sense **nvesting: The Only Way to Guarantee Your Fair Share of Stock Market Returns
- The Little Book of Value Investing
- Value Investing: From Graham to Buffett and Beyond
- Rich Dad’s Guide to Investing: What the Rich Invest in, That the Poor and the Middle Class Do Not!
- Investing in Real Estate, 5th Edition
- Stock Investing For Dummies
- Rich Dad’s Advisors: The ABC’s of Real Estate Investing: The Secrets of Finding Hidden Profits Most Investors Miss
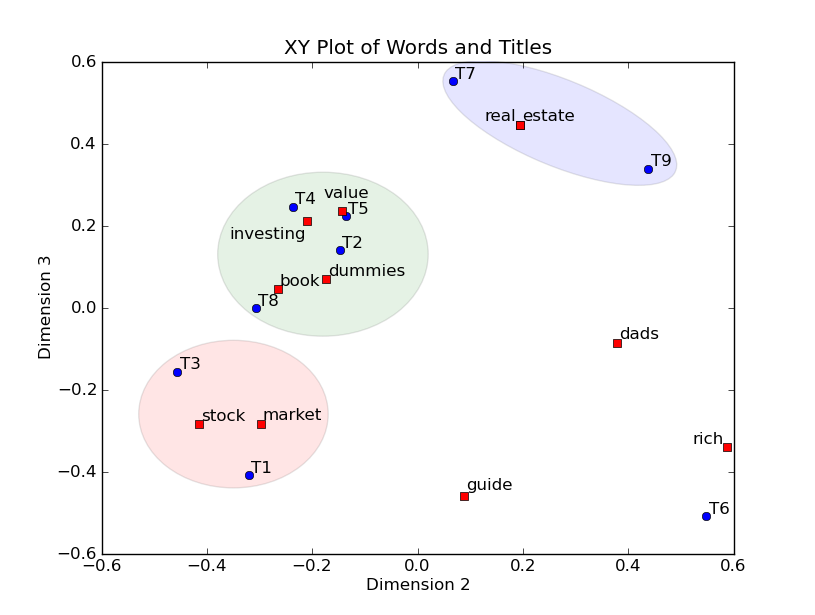
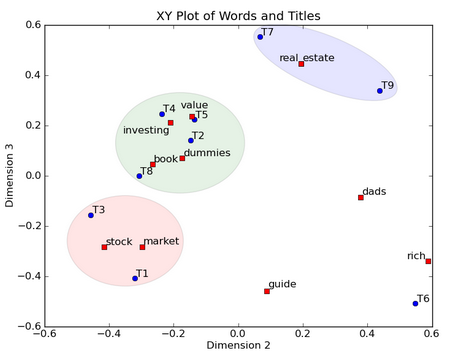
上面的例子进过LSA后,我们能画出索引词和文章标题的二位XY图,并能标注出文章的类簇。9个标题用户蓝点标注,11个索引词用红点标注。我们不仅能标注出文章的类簇,还能标注出相应的索引词,通过这些索引词来给类簇打上标签。如蓝色类簇包含了T7和T9,该类簇是有关real estate的文章。绿色类簇包含了T2, T4, T5, 和T8,,该类簇是有关 value investing的文章。最后红色类簇包含了T1 和T3,该类簇是有关 stock market的文章。而T6是一个异常
在下面几个章节,我们将详细介绍LSA的运行机制
Part 1 - Creating the Count Matrix
首先,LSA需要创建单词-标题(或文章)矩阵。在该矩阵中,行表示索引词,而列表示题目。每个元素表示对应的标题包含多少个相应的索引词。例如,”book” 在T3和T4中出现了1次,而”investing” 出现在所有的表中。一般情况下LSA创建的单词-标题矩阵会相对巨大,而且十分稀疏(大部分元素为0),这是因为每个标题或文章一般只包含十分少的频繁单词。改进的LSA通过这种稀疏性能有效降低内存的损耗和算法复杂度
Python - Import Functions
首先需要加载几个python的数学运算模块。NumPy 是一个进行线性代数包,我们将加载zeros函数,该函数用于创建0矩阵。通过线性代数包scipy能得到svd的算法函数,SVD是整个LSA算法的核心
from numpy import zeros from scipy.linalg import svd- 1
- 2
Python - Define Data
我们有9本书的标题,其中包含8个停止词,在计算词频时我们将忽略这些停止词,同时再进行分词是标点符号也将被忽略掉。
titles = [ "The Neatest Little Guide to Stock Market Investing", "Investing For Dummies, 4th Edition", "The Little Book of Common Sense Investing: The Only Way to Guarantee Your Fair Share of Stock Market Returns", "The Little Book of Value Investing", "Value Investing: From Graham to Buffett and Beyond", "Rich Dad's Guide to Investing: What the Rich Invest in, That the Poor and the Middle Class Do Not!", "Investing in Real Estate, 5th Edition", "Stock Investing For Dummies", "Rich Dad's Advisors: The ABC's of Real Estate Investing: The Secrets of Finding Hidden Profits Most Investors Miss" ] stopwords = ['and','edition','for','in','little','of','the','to'] ignorechars = ''',:'!'''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Python - Define LSA Class
LSA类的方法有初始化,文章解析,创建单词计数矩阵。初始化方法 __init__ 用于实例化LSA,并加载停止词集合和标点符号集合,还初始化词典(word dictionary)和文章计数变量
class LSA(object): def __init__(self, stopwords, ignorechars): self.stopwords = stopwords self.ignorechars = ignorechars self.wdict = {} self.dcount = 0- 1
- 2
- 3
- 4
- 5
- 6
Python - Parse Documents
文章解析方法是对文章进行分词,并将所有字母变成小写(指英文文章),最后滤掉停止词和标点。该方法将非停止词加入到词典,并进行词频计数。例如,单词“book”出现在再T3和T4,我们设self.wdict[‘book’] = [3, 4] 。当处理完一篇文章的所有分词,我们就递增文章计数变量,并输入下一篇文章进行解析
def parse(self, doc): words = doc.split(); for w in words: w = w.lower().translate(None, self.ignorechars) if w in self.stopwords: continue elif w in self.wdict: self.wdict[w].append(self.dcount) else: self.wdict[w] = [self.dcount] self.dcount += 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Python - Build the Count Matrix
当所有的文章都被解析,所有的索引词都将被提取和保存,接着将构建单词-标题(或文章)矩阵。矩阵的行数等于索引词的数目,矩阵的列数等于文章/标题的数目。最后每个单词-文章的配对值将加载到矩阵相应的单元格中。
def build(self): self.keys = [k for k in self.wdict.keys() if len(self.wdict[k]) > 1] self.keys.sort() self.A = zeros([len(self.keys), self.dcount]) for i, k in enumerate(self.keys): for d in self.wdict[k]: self.A[i,d] += 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
Python - Print the Count Matrix
printA()方法用于打印创建好的单词-标题(或文章)矩阵
def printA(self): print self.A- 1
- 2
Python - Test the LSA Class
现在我们用 LSA类来测试前面的9个标题。首先是实例化LSA为mylsa,然后初始化将忽略我们预先定义的停止词和标点,同时出书词典和文章计数变量
接着调用解析方法去解析各标题,从而提出索引词,并对词频进行计数
最后我们通过build() 方法构建单词-标题(或文章)矩阵。该矩阵过滤掉仅出现在1个标题的单词。mylsa = LSA(stopwords, ignorechars) for t in titles: mylsa.parse(t) mylsa.build() mylsa.printA()- 1
- 2
- 3
- 4
- 5
以下是输出结果
[[ 0. 0. 1. 1. 0. 0. 0. 0. 0.] [ 0. 0. 0. 0. 0. 1. 0. 0. 1.] [ 0. 1. 0. 0. 0. 0. 0. 1. 0.] [ 0. 0. 0. 0. 0. 0. 1. 0. 1.] [ 1. 0. 0. 0. 0. 1. 0. 0. 0.] [ 1. 1. 1. 1. 1. 1. 1. 1. 1.] [ 1. 0. 1. 0. 0. 0. 0. 0. 0.] [ 0. 0. 0. 0. 0. 0. 1. 0. 1.] [ 0. 0. 0. 0. 0. 2. 0. 0. 1.] [ 1. 0. 1. 0. 0. 0. 0. 1. 0.] [ 0. 0. 0. 1. 1. 0. 0. 0. 0.]]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Part 2 - Modify the Counts with TFIDF
在该井的LSA算法中,源单词-标题(或文章)矩阵一般会进行加权调整,其中稀少的词的的权重会大于一般性的单词。例如一个单词出现杂5%的文章,其权重应大于一个出现90%的文章中的单词。TFIDF 是最常用的度量指标(Term Frequency - Inverse Document Frequency),公式如下
TFIDFij=NijN⋅jlog(DDi)TFIDFij=NijN⋅jlog(DDi)NijNij是语料库文章出现索引词i的文章数,也就是源矩阵中i行中非零元素的个数
从公式得知,单词的词频越高,且包含该单词的文章越少,则相应的TFIDF 值越大。
本文例子规模不大,因此不对矩阵进行权重调整。但是我们依然将相关代码列出def TFIDF(self): WordsPerDoc = sum(self.A, axis=0) DocsPerWord = sum(asarray(self.A > 0, 'i'), axis=1) rows, cols = self.A.shape for i in range(rows): for j in range(cols): self.A[i,j] = (self.A[i,j] / WordsPerDoc[j]) * log(float(cols) / DocsPerWord[i])- 1
- 2
- 3
- 4
- 5
- 6
- 7
Part 3 - Using the Singular Value Decomposition
当单词-标题(或文章)矩阵创建完成,我们将使用强大的SVD算法进行矩阵分析。关于SVD的详细介绍可以阅读 “Singular Value Decomposition Tutorial”。
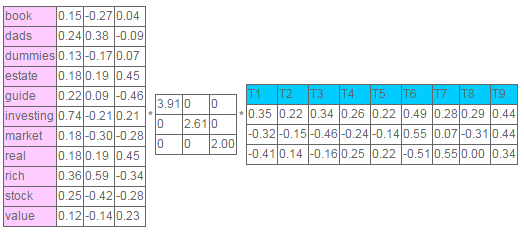
SVD的强大在于,其通过强调强的相关关系并过滤掉噪声来实现矩阵降维(it finds a reduced dimensional representation of our matrix that emphasizes the strongest relationships and throws away the noise)。换句话说,SVD使用尽可能少的信息来对原矩阵进行尽可能好的重构(这里的好应该是指重构矩阵失真少,且噪声少)。其实现手段是减低噪声,同时增强强模式和趋势(o do this, it throws out noise, which does not help, and emphasizes strong patterns and trends, which do help)。在LSA中使用SVD时为了确定单词-标题(或文章)矩阵有效维度数或包含“语义”数。经过压缩后,之后少量用于有用的维度或语义模式被留下,大量噪声将被过滤掉。这些噪声是由于作者的随机选择找出。SVD算法的实现有点复杂,幸运的是python有现成的的函数完成该工作。通过加装python的SVD函数,我们将矩阵分解成3个矩阵。矩阵UU告诉我们有词-标题(或文章)矩阵包含了多少语义或语义空间的有效维度是多少。
def calc(self): self.U, self.S, self.Vt = svd(self.A)- 1
- 2
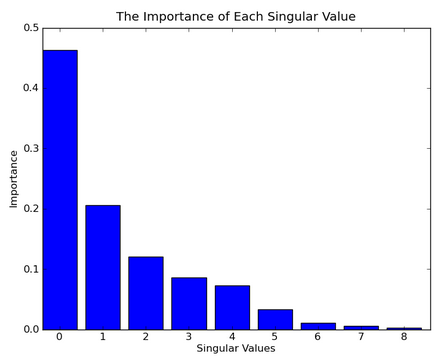
为了确定合适的有效维度,我们通过奇异值的平方的直方图来进行观察。图中演示出各奇异值的重要性
对于大规模的语料库,压缩后的有效一般是100-500维。在本例中,为了实现可视化,我们选择有效维度数为3 。最后,我们将选择选择第2和第3维进行可视化。
可视化是我们扔掉第1维是十分有意思的。从文章的角度来说,第1维表示文章的“长度”(length,我猜测length是指文章中索引词的数量)。从单词的角度来看,第1维表示该次出现在语料库的次数。如果我们中心化单词-标题(或文章)矩阵,即每列都减去该列的均值,那么我们将使用第1维。
这一段我不是理解得很好,作者还用高尔夫球来做类比,可是我这屌丝连球都没摸过真心翻译不下去了,所以把这段原文贴下,望各位指教
The reason we throw out the first dimension is interesting. For documents, the first dimension correlates with the length of the document. For words, it correlates with the number of times that word has been used in all documents. If we had centered our matrix, by subtracting the average column value from each column, then we would use the first dimension. As an analogy, consider golf scores. We don’t want to know the actual score, we want to know the score after subtracting it from par. That tells us whether the player made a birdie, bogie, etc.我们不对单词-标题(或文章)矩阵进行中心化,是为了避免将单词-标题(或文章)矩阵由稀疏矩阵变为稠密矩阵。稠密矩阵会增加内存的负荷和计算量。因此不对单词-标题(或文章)矩阵进行中心化和放弃第1维的做法根高效
这里我们计算出了3个奇异值,分别对应着3个维度。每个单词与这个3个维度与这些奇异值相关,第1维表示该单词在语料库中的频繁程度,因此没太大信息量。类似地,每篇文章也有3个维度分别对着3个奇异值。如之前所述,第1维反映了文章所包含索引词的数量,因此信息不大。
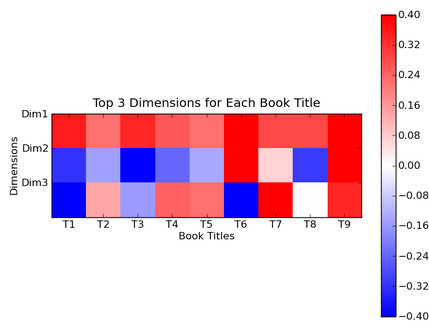
Part 4 - Clustering by Color
我们将数字用不同的颜色进行表示。例如,我们用同的颜色来表示VTVT矩阵反映的信息完全一致。蓝色表示负数,红色表示正数,0表示白色。如标题9,其3个维度的上值都正数,因此相应的颜色都是深红色
我们用这些颜色对聚类结果进行颜色标注。我们忽视第1维表示的颜色,因为所有文章在该维度上都是红色
Dim2 Titles red 6-7, 9 blue 1-5, 8 加上第3维,我们能用相同的方法区分出不同的语义群。在第3维上,标题6是蓝色,而标题7和标题9依然是红色的。通过这种方法我们将标题集分成4个群
Dim2 Dim3 Titles red red 7, 9 red blue 6 blue red 2,4,5,8 blue blue 1,3 Part 5 - Clustering by Value
将矩阵UU的第2,3维画在一个2维XY平面中,其中X表示第2维,Y表示第3维,并将所有索引词和标题画在该平面中。如图所示,单词“book”的坐标值为 (0.15, -0.27, 0.04),忽略第一维的值 0.15 后, “book” 的坐标点为 (x = -0.27, y = 0.04)。标题的画法也是类似。
这种可视化方法的优点在于将单词和标题都画在同一个空间。这种做法毕竟能实现标题的聚类,还能通过索引词标注出不同类簇的意义。例如,左下的簇包含含量了标题1和标题2,这两个标题均关于stock market investing。单词”stock”和”market”明显包含在标题1和标题2的簇中,这也很容易地理解这个语义簇所指代的意义。中间的簇包含了标题2,4,5,8。其中标题2,4,5与单词”value” 和”investing”代表的意思最为接近,因此 标题2,4,5的语义可表示为:”value” 和”investing”
Advantages, Disadvantages, and Applications of LSA
LSA具有很多优势让其被广泛应用于各种领域
- 首先文章和单词都映射到同一个语义空间。在该空间内即能对文章进行聚类也能对单词进行聚类。重要的是我们能通过这些聚类结果实现基于单词的文献检索,反之亦然。
- 语义空间的维度明显明显少于源单词-文章矩阵。更重要的是这样经过特定方式组合而成维度包含源矩阵的大量信息,同时降低了噪声的影响。这些特性有助于后续其他算法的加工处理。
- 最后,LSA 是一个全局最优化算法,其目标是寻找全局最优解而非局部最优解,因此它能求出基于局部求解算法得不到的全局信息。有时LSA会结合一些局部算法,如最近领域法,使得LSA性能得到进一步提升
LSA依然存在一些缺陷,在我们使用的时候需要特别注意。
- 首先LSA是假设服从高斯分布和2范数规范化的,因此它并非适合于所有场景。例如,单词在语料库中服从的是Poisson 分布而不是高斯分布
- LSA不能有效处理一词多义问题。因为LSA的基本假设之一是单词只有一个词义
- LSA的核心是SVD,而SVD的计算复杂度十分高并且难以更新新出现的文献。不过最近已经出现一些有效的方法用于解决SVD的基于文献更新问题。
即使SVD存在上述缺陷,当LSA依然被广泛用于文献检索,文本分类,垃圾邮件过滤,语言识别,模式检索以及文章评估自动化等场景
As an example, iMetaSearch uses LSA to map search results and words to a “concept” space. Users can then find which results are closest to which words and vice versa. The LSA results are also used to cluster search results together so that you save time when looking for related results.
References & Resources














05-09
11-19
 3万+
3万+
3万+
04-20
05-06
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









