







 文章详细解析了SHOWENGINEINNODBSTATUS命令返回的各种信息,包括信号量(CPU自旋、OSWAITARRAYINFO)、死锁情况、外键冲突、事务状态、I/O操作和缓冲池等,这些都是数据库性能诊断的关键指标。通过对这些信息的理解,可以帮助优化数据库性能,解决死锁和资源争用问题。
文章详细解析了SHOWENGINEINNODBSTATUS命令返回的各种信息,包括信号量(CPU自旋、OSWAITARRAYINFO)、死锁情况、外键冲突、事务状态、I/O操作和缓冲池等,这些都是数据库性能诊断的关键指标。通过对这些信息的理解,可以帮助优化数据库性能,解决死锁和资源争用问题。
文章目录
1、SHOW ENGINE INNODB STATUS概述
MySQL的SHOW ENGINE INNODB STATUS命令用于显示InnoDB存储引擎的状态信息,包括在途事务、锁、缓冲池和日志文件等,从而帮助诊断数据库性能问题。
2、信号量(Semaphores)
2.1、信号量信息示例
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 966159
OS WAIT ARRAY INFO: signal count 977049
RW-shared spins 0, rounds 1931889, OS waits 956497
RW-excl spins 0, rounds 87774, OS waits 1228
RW-sx spins 11669, rounds 180155, OS waits 3364
Spin rounds per wait: 1931889.00 RW-shared, 87774.00 RW-excl, 15.44 RW-sx
2.2、信号量信息说明
- “OS WAIT ARRAY INFO”:提供了关于InnoDB存储引擎等待操作系统的信息。
- “reservation count”:当前已经在等待操作系统资源的请求数量。
- “signal count”:InnoDB已经完成等待并收到来自操作系统的信号的数量。"reservation count"和"signal count"这两个值的差异通常表示正在等待的请求数量。
- “RW-shared spins 0, rounds 1931889, OS waits 956497”:表示已经有1931889次获取共享读锁,其中没有自旋等待(即"RW-shared spins"的值为0),操作系统层面等待(即上下文切换)次数为为956497次(即"OS waits"的值为956497)。之所以有操作系统层面等待,是由于锁资源被其他事务占用,共享锁的获取请求需要在操作系统层面等待。
- “RW-excl spins 0, rounds 87774, OS waits 1228”:表示已经有87774次获取排它锁,其中没有自旋等待(即"RW-excl spins"的值为0),操作系统层面等待次数为1228次。
- “RW-sx spins 11669, rounds 180155, OS waits 3364”:表示已经有180155次获取意向锁,其中自旋等待次数为11669次,操作系统层面等待有3364次。
- “Spin rounds per wait: 1931889.00 RW-shared, 87774.00 RW-excl, 15.44 RW-sx”:“Spin rounds per wait”
2.3、知识点:CPU自旋(SPIN)
- CPU的自旋用于等待共享资源的可用性。当一个线程需要使用一个共享资源时,如果该资源当前正在被另一个线程占用,那么该线程可以选择自旋等待,而不是立即挂起或进入睡眠状态。在自旋等待期间,线程会反复执行一个短小的循环,检查共享资源是否已经可用。如果该资源仍然不可用,线程会继续自旋,直到该资源变得可用或达到了一定的自旋次数后再挂起或进入睡眠状态进行等待(OS WAIT)。
- 自旋等待的优点:可以避免线程上下文切换的开销,从而提高程序的性能。
- 自旋等待的缺点:会占用CPU的时间,导致其他线程无法获得CPU时间片,从而影响整个程序的性能。所以有时我们看到系统的CPU利用率很高,但也许并不是真正地在做事,而是CPU正在空转等待资源。
- 自旋等待适用于共享资源的竞争情况较少,且自旋等待时间较短的情况下,可以提高程序的性能。而在竞争激烈或自旋等待时间较长的情况下,应该避免使用自旋等待,而选择其他的同步机制,如信号量、互斥锁等。
2.3、信号量中的OS WAIT ARRAY INFO
- OS WAIT ARRAY INFO表示当前的操作系统等待,如果每秒有几万次的OS WAIT,那么很可能系统中存在性能问题。对数据库有高并发访问时,可能会看到这部分信息,因为InnoDB自旋等待超过了阈值,就会触发操作系统等待,如果等待通过自旋能够解决,那么这些信息就不会显示了。通过检查这部分信息,可以大致判断负荷的热点在哪里。
- 由于输出行只包含了一些文件名,因此还需要有一些源码的知识,才能判断出现等待的真实原因。reservation count和signal count的值表征了InnoDB需要OS WAIT的频率。也可以使用操作系统命令,如vmstat,通过检查上下文切换(context switch)的频率来确认OS WAIT的严重程度。
- 大量的spin waits和spin rounds,意味着CPU在空转而没有实际做事,这会消耗大量的CPU资源。
- 通过调整innodb_sync_spin_loops参数,可以在CPU资源消耗和上下文切换之间找到平衡点。
3、死锁
3.1、死锁信息示例
以下是一个SHOW ENGINE INNODB STATUS中的死锁信息示例:
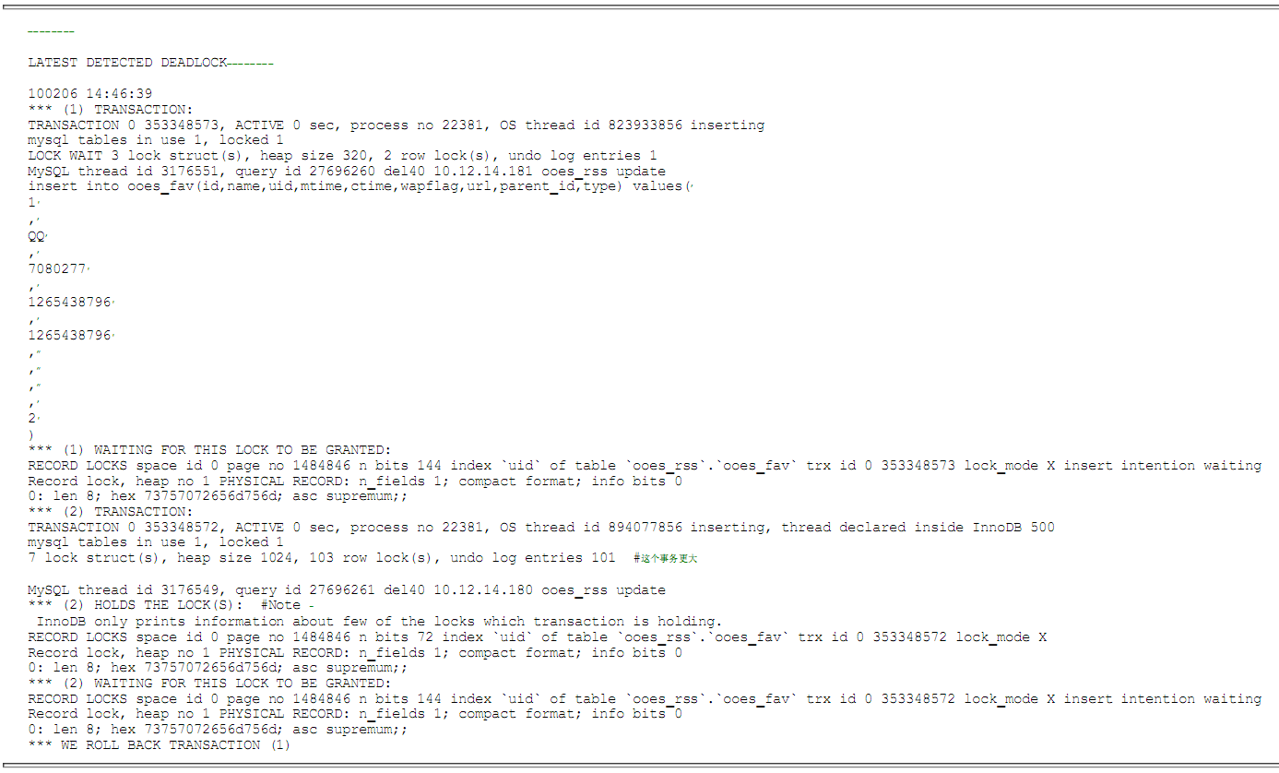
3.2、死锁信息说明
- 死锁信息展示了是哪些事务导致了死锁、死锁过程中它们的状态、它们持有的锁、要等待的锁、回退到哪个事务等内容。需要留意的是,死锁信息这里只显示了事务中最近的语句,而实际上占据资源的可能是事务中前面的语句。在一些简单情况下,可以通过SHOW ENGINE INNODB STATUS的输出确认导致死锁的原因;在复杂的情况下,则需要打开通用日志,检查具体各个事务是如何互相等待资源从而导致死锁的。MySQL 5.6可以通过参数innodb_print_all_deadlocks将死锁信息打印到错误日志中。
- 这里由输出的最后一行可以得知,回退到了事务1。
4、外键冲突
4.1、外键冲突信息示例
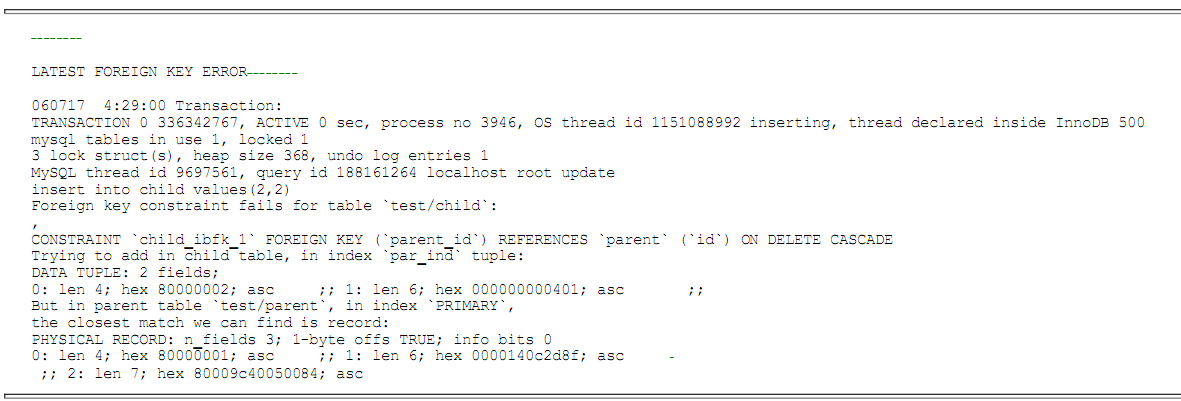
4.2、外键冲突信息说明
外键冲突信息主要需要开发人员注意。
5、事务信息
SHOW ENGINE INNOD STATUS一般只显示部分事务,因为事务列表可能会很长。
5.1、事务信息示例
------------
TRANSACTIONS
------------
Trx id counter 1752317
Purge done for trx's n:o < 1747534 undo n:o < 0 state: running but idle
History list length 0
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 421837837867744, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 421837837866832, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 421837837872304, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 421837837870480, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 421837837869568, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 421837837868656, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
5.2、事务信息说明
5.2.1、Trx id counter ...
Trx id counter后面跟的事当前事务号。trx id counter其实表示已分配的事务ID(transaction ID)计数器的值,每新增一个事务就加1,直到达到最大值,然后重新循环使用。
5.2.2、Purge done for trx's n:o < ...
- "<"后的值是最近一次进行线程清理的事务号,这个值表示已经完成了所有小于该事务ID的清理操作。
- 事务如果过期,则可以被清除,清除的标准是这些事务已经提交,且不会再被其他的事务所需要。在InnoDB存储引擎中,Purge操作是一个重要的后台任务,它负责删除已经标记为已提交的事务的undo log和版本。因为undo log是用来撤消事务所做的更改,而版本是用来实现多版本并发控制(MVCC)的机制,所以Purge操作的完成很重要,可以释放磁盘空间并保持系统的稳定性。
- 我们可以检查当前事务号和最近一次进行线程清理的事务号的差异,例如,0(64位)80154573(32位)与0(64位)80157601(32位),如果差异很大,则可能有大量事务或者长事务,可能会导致UNDO空间暴涨。
- "Purge done for trx’s n:o < 1747534"表示已经完成了所有小于事务ID 1747534 的Purge操作。这意味着所有小于1747534的已提交事务的版本和undo log都已经被删除。
5.2.3、undo n:o < ...
- "<"后的值是最近一次进行线程清理的UNDO日志号。注意,这里不是事务号,而是UNDO日志号。
- "undo n:o < 0"表示所有的undo log都已经被清理。这是因为在InnoDB存储引擎中,所有的undo log都是从事务ID 1 开始创建的,而"undo n:o < 0"的意思是所有小于事务ID 0 的undo log都已经被清理,这实际上就是所有的undo log都已经被清理了。
5.2.4、state: running but idle
- "state: running but idle"意味着InnoDB存储引擎当前没有正在执行的查询或事务,但它仍在运行并等待下一个操作,意味着InnoDB引擎正在运行但处于空闲状态,这通常是一个正常的状态。
5.2.5、History list length ...
- "History list length"表示InnoDB存储引擎中的历史记录列表长度。InnoDB使用历史记录列表(history list)来跟踪每个数据页的修改历史记录。当一个数据页发生修改时,InnoDB会将修改前的数据页复制到历史记录列表中,以便在需要回滚时可以使用。
- 如果这个值比较大,说明系统中有很多数据页发生过修改,因此历史记录列表中的数据页也比较多。这可能会导致一些性能问题,因为历史记录列表的长度会影响InnoDB存储引擎的内存使用和性能。
- LIST OF TRANSACTIONS FOR EACH SESSION:每个事务都有两个状态,即not started或active。在生产系统中,同时运行的线程一般最多只有几个,所以大部分事务都是not started。如果SHOW INNODB STATUS显示有很多线程在等待(wai ting in InnoDB queue或sleeping before joining InnoDB queue)进入队列,那么往往是有性能上的问题,导致系统挂死。
5.2.6、LIST OF TRANSACTIONS FOR EACH SESSION: ...
- "LIST OF TRANSACTIONS FOR EACH SESSION:"会列出正在运行的事务的列表,但通常只显示部分事务,因为整个列表可能很长。
- 每个事务都有两个状态,即not started或active。在生产系统中,同时运行的线程一般最多只有几个,所以大部分事务都是not started。
- "lock struct(s)"表示当前系统中的锁定结构数量,"heap size"表示锁定结构在内存中的大小,"row lock(s)"表示当前系统中的行锁数量。
6、I/O信息
6.1、I/O信息示例
--------
FILE I/O
--------
I/O thread 0 state: waiting for completed aio requests (insert buffer thread)
I/O thread 1 state: waiting for completed aio requests (log thread)
I/O thread 2 state: waiting for completed aio requests (read thread)
I/O thread 3 state: waiting for completed aio requests (read thread)
I/O thread 4 state: waiting for completed aio requests (read thread)
I/O thread 5 state: waiting for completed aio requests (read thread)
I/O thread 6 state: waiting for completed aio requests (write thread)
I/O thread 7 state: waiting for completed aio requests (write thread)
I/O thread 8 state: waiting for completed aio requests (write thread)
I/O thread 9 state: waiting for completed aio requests (write thread)
Pending normal aio reads: [0, 0, 0, 0] , aio writes: [0, 0, 0, 0] ,
ibuf aio reads:, log i/o's:, sync i/o's:
Pending flushes (fsync) log: 0; buffer pool: 0
141917 OS file reads, 7409797 OS file writes, 5774363 OS fsyncs
0.00 reads/s, 0 avg bytes/read, 0.00 writes/s, 0.00 fsyncs/s
6.2、I/O信息说明
- “Pending normal aio reads: [0, 0, 0, 0] , aio writes: [0, 0, 0, 0]”:"aio"是异步输入输出(Asynchronous I/O)的缩写。“Pending normal aio reads"表示当前等待完成的异步读请求数量,每个数字对应不同的线程池。例如,”[0, 0, 0, 0]"表示四个线程池中没有等待完成的异步读请求。同样地,“aio writes"表示当前等待完成的异步写请求数量,每个数字对应不同的线程池。例如,”[0, 0, 0, 0]"表示四个线程池中没有等待完成的异步写请求。如果为非零值,则可能存在I/O瓶颈。
- “Pending flushes (fsync) log: 0; buffer pool: 0”:"Pending flushes"表示待刷新的数据页数量,"fsync"是一种同步刷新磁盘缓存的方式,"log"和"buffer pool"分别表示日志和缓冲池。"Pending flushes (fsync) log"表示待刷新到磁盘的日志页数量,如果该数字过高,可能意味着系统出现了日志写入瓶颈,需要进行进一步的调优。同样地,"Pending flushes (fsync) buffer pool"表示待刷新到磁盘的缓冲池页数量,如果该数字过高,可能意味着系统出现了缓冲池写入瓶颈,需要进行进一步的调优。
7、插入缓存和自适应索引信息
7.1、插入缓存和自适应索引信息示例
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 1036 merges
merged operations:
insert 1037, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 1106407, node heap has 1 buffer(s)
Hash table size 1106407, node heap has 2 buffer(s)
Hash table size 1106407, node heap has 1 buffer(s)
Hash table size 1106407, node heap has 1 buffer(s)
Hash table size 1106407, node heap has 2 buffer(s)
Hash table size 1106407, node heap has 225 buffer(s)
Hash table size 1106407, node heap has 34 buffer(s)
Hash table size 1106407, node heap has 2 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
7.2、插入缓存和自适应索引信息说明
- “Ibuf: size 1, free list len 0, seg size 2, 1036 merges”:"Ibuf"表示Insert Buffer,"size 1"表示当前Insert Buffer的大小,"free list len 0"表示空闲列表的长度,"seg size 2"表示Insert Buffer中每个段的大小,"1036 merges"表示已经执行的合并次数。
7.3、Insert Buffer(插入缓存)
Insert Buffer是一种用于缓存插入操作的数据结构,可以减少磁盘I/O的次数,提高插入性能。在执行插入操作时,Insert Buffer首先将数据写入内存中的缓存,然后在合适的时机将缓存中的数据刷新到磁盘上。由于磁盘I/O的速度比内存慢很多,Insert Buffer可以大大提高插入操作的效率。
8、LOG
8.1、LOG信息示例
---
LOG
---
Log sequence number 1676631265
Log flushed up to 1676631265
Pages flushed up to 1676631265
Last checkpoint at 1676631256
0 pending log flushes, 0 pending chkp writes
4216688 log i/o's done, 0.00 log i/o's/second
8.2、LOG信息说明
- “Log sequence number 1676631265”:表空间创建后写入log buffer的字节数,这个值可以用来衡量日志的写入速度。通过多次采样Log sequence number的输出,可以获取每秒写入的日志量。如果我们要设置InnoDB事务日志的大小,那么能保持连续写入日志30~60分钟为佳。
- “Log flushed up to 1676631265”:最近刷写到事务日志文件的位置。由此可以计算还有多少未刷新到日志文件(logfile)的数据。如果这些数据大于innodb_log_buffer_size的30%,那么就要考虑是否应增加日志缓冲(log buffer)了。
- “Pages flushed up to 1676631265”:最近刷写到磁盘的数据页的位置。
- “Last checkpoint at 1676631256”:最近一次检查点的位置。
- “0 pending log flushes, 0 pending chkp writes”:pending如果大于0,则可能有I/O瓶颈。
9、缓冲池信息
9.1、缓冲池信息示例
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 2198863872
Dictionary memory allocated 1344344
Buffer pool size 131072
Free buffers 100351
Database pages 30453
Old database pages 11221
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 540506, not young 12530638
0.00 youngs/s, 0.00 non-youngs/s
Pages read 141806, created 56566, written 2655957
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 30453, unzip_LRU len: 0
I/O sum[6]:cur[0], unzip sum[0]:cur[0]
9.2、缓冲池信息说明
- “Total large memory allocated”、“Dictionary memory allocated”、“Buffer pool size”、"Free buffers "单位都是字节。
- "xx pages"的单位都是页面个数
- “Buffer pool hit rate”(缓冲池命中率):这是这段信息里最重要的指标。在这个例子中,缓冲池命中率为1000/1000,表示所有请求都可以从缓冲池中得到所需的页面,这是非常理想的情况。如果命中率较低,可能意味着缓冲池设置过小或者存在过多的数据读取请求,需要进一步进行调整和优化。
10、ROW OPERATIONS信息
10.1、ROW OPERATIONS信息示例
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
0 read views open inside InnoDB
Process ID=17149, Main thread ID=140362560964352, state: sleeping
Number of rows inserted 11021637, updated 592, deleted 376466, read 233292619921
0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s
10.2、ROW OPERATIONS信息说明
- ROW OPERATIONS是行操作信息,需要留意的是如果“0 queries in queue”不为0,则是有查询需要等待,可能意味着系统忙,你需要做进一步的诊断。
11、总结
SHOW ENGINE INNODB STATUS会提供关于InnoDB引擎的很多有用信息,包括操作系统等待、死锁、外键冲突、在途事务、I/O、插入缓存、自适应索引、日志、缓冲池和行操作等信息。- 特别要注意事务中Undo清理是否足够及时(不会导致Undo空间暴涨)、输入输出是否存在Pending、日志刷写是否及时等。

















 21
21

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









