







函数
object FunctionTest { def testPro(name:String,age:Int): Unit ={ println(name+":"+"age"); } def main(args: Array[String]): Unit = { testPro("lee",30) } }
本地函数
object FunctionTest { def main(args: Array[String]): Unit = { processFile("c:/a.txt",20); } def processFile(fileName:String,width:Int): Unit = { def processLine(fileName: String, width: Int, line: String): Unit = { if (line.length > width) { println(fileName + ":" + line); } } val source = Source.fromFile(fileName); for (line <- source.getLines()) { processLine(fileName, width, line); } } }为什么要使用本地函数:在拆解函数时往往将函数拆分成很多小函数。这些函数往往称之为辅助函数。程序打成包部署生产环境下,这些函数是没有任何意义的(除了对本地对象或类)。因此存在命名空间污染。在Java中本地函数/方法是用private修饰,这种办法同样适用于scala语言中。
object FunctionTest { def main(args: Array[String]): Unit = { processFile("c:/a.txt",20); } def processFile(fileName:String,width:Int): Unit = { def processLine(line :String): Unit = { if (line.length > width) { println(fileName + ":" + line); } } val source = Source.fromFile(fileName); for (line <- source.getLines()) { processLine(fileName, width, line); } } }
头等函数
函数字面量——值函数
函数字面量(function literal),也称值函数(function values),指的是函数可以赋值给变量。一般函数具有如下形式:
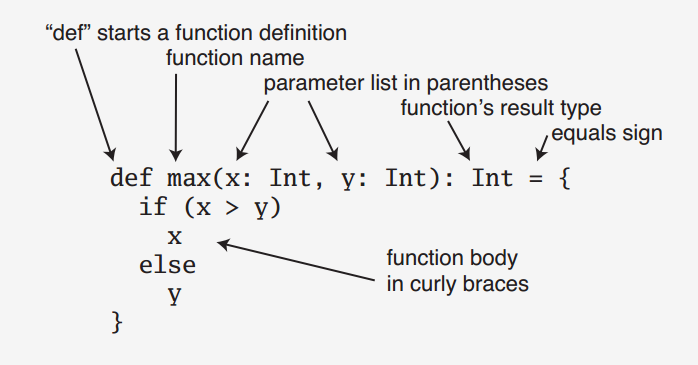
/**
* 函数字面量 function literal
* =>左侧的表示输入,右侧表示转换操作
*/
scala> val increase=(x:Int)=>x+1
increase: Int => Int = <function1>
scala> println(increase(10))//前面的语句等同于
scala> def increaseAnother(x:Int)=x+1
increaseAnother: (x: Int)Int
scala> println(increaseAnother(10))
11//数组的map方法中调用(写法1)
scala> println(Array(1,2,3,4).map(increase).mkString(","))
1,2,3,4,5函数字面量还可以写的更加简短,例如上面的例子:
还可以这么写(把参数类型去掉,filter是过滤器)
scala> somenums
res39: List[Int] = List(1, 2, 3, 4, 5)
scala> somenums.filter(_>0);
res40: List[Int] = List(1, 2, 3, 4, 5)
还有一种简化函数字面量的方式——占位符。如果想让函数字面量变得更清洁,占位符是一个很不错的选择。scala中使用下划线做占位符。可以把占位符看成表达式里需要被“填入”的“空白”,也可以理解为“预留”。这个空白在每次函数被调用的时候,参数填入。有时编译器无法推断确实的参数类型,例如:val f = _+_,编译器是无法推断数据类型的。因此可以写成(_:Int)+(_:Int)。谨记:每个参数在函数字面量中最多出现一次。多个下划线出现时需指定类型,依次代表1,2...参数,而不是一个参数的重复利用。
部分应用函数
部分应用函数是一种表达式,不需要提供函数所需要的所有参数,而是提供一部分获不提供参数。例如:
object FunctionTest { val somenums = List(1,2,3,4); somenums.foreach(println _);//注意空格 }在看一个
object FunctionTest { def sum (x:Int,y:Int,z:Int) = x + y +z val a = sum _; sum(1,2,3) }
高阶函数
柯里化
闭包
到这里为止,所有函数字面量的例子仅参考了传入的参数。例如:(x:Int) => x>0,表达式x>0中用到了参数x,x被称为函数参数。然后也可以参考定义在其他地方的变量。例如(x:Int)=> x+more;这里x是绑定变量,more是自由变量,且more必须有定义。

scala编程中是这么说闭包的--闭包源自于通过捕获自由变量的绑定,从而对函数字面量执行关闭操作。不带自由变量的函数字变量,如(x:Int)=>
x+1,被称为封闭项,项指的是一部分源代码,因此按照函数字面量在运行的时创建的函数值严格意义上讲不是闭包,因为在编写的时候就封闭了。任何带有自由变量的字面量都是开放项。因此任何以(x:Int)=> x+more为模板在运行期间创建的函数值必将捕获自由变量。因此得到的函数值有指向捕获自由变量的索引,又由于函数值是关闭这个开放项(x:Int)=>x+more的最终产物,因此被称作闭包。
object FunctionTest { val someNumbers = List(-11,-10,5,0,5,10); var sum = 0; someNumbers.foreach(sum += _); }
重复参数
def echo(str : String*): Unit ={ for(arg <- str){ println(arg); } }这样定义的echo可以被一个或者多个参数调用:
object FunctionTest { def echo(str : String*): Unit ={ for(arg <- str){ println(arg); } } def main(args: Array[String]): Unit = { echo("hello"); echo("hello","world","scala"); } //输出结果 hello hello world scala Process finished with exit code 0 }在函数内部,重复参数的类型实际上是声明参数的类型的数组。在ehco被声明为String类型的str,是基上是Array[String]。但是往echo里传入数组类型编译报错, 例如val arr=Array("s","b")。 应该使用echo(arr : _*)。














 653
653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









