







文章目录
概要
我们将以一个以英雄联盟对局胜负预测任务为基础为例
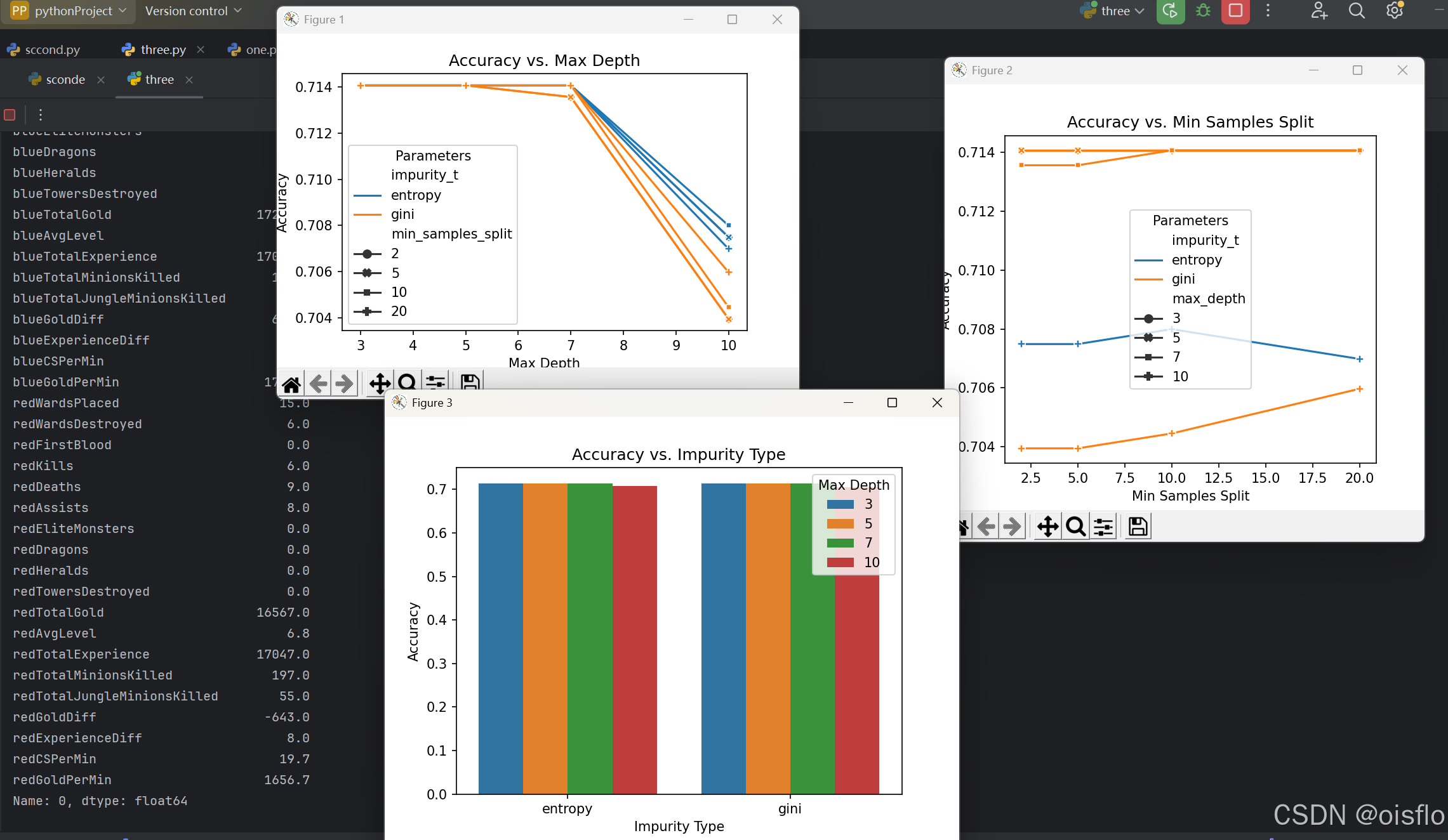
构建一个决策树模型,从数据预处理到模型训练和评估,再到参数优化(不同max_depth下的准确率,不同min_samples_split下的准确率,不同impurity_t下的准确率)和结果可视化
成果
通过网格搜索找到了最优的决策树参数配置,并在测试集上取得了较高的准确率。通过绘制不同参数组合下的准确率图,直观地展示了参数对模型性能的影响
完整代码
from collections import Counter
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import seaborn as sns
import matplotlib.pyplot as plt
# 固定随机种子
RANDOM_SEED = 2020
# 数据路径
csv_data = r'C:\Users\16397\Desktop\tree\tree\data/high_diamond_ranked_10min.csv'
data_df = pd.read_csv(csv_data, sep=',') # 读入csv文件为pandas的DataFrame
data_df = data_df.drop(columns='gameId') # 舍去对局标号列
print(data_df.iloc[0]) # 输出第一行数据
data_df.describe() # 每列特征的简单统计信息
# 需要舍去的特征列
drop_features = ['blueGoldDiff', 'redGoldDiff',
'blueExperienceDiff', 'redExperienceDiff',
'blueCSPerMin', 'redCSPerMin',
'blueGoldPerMin', 'redGoldPerMin']
df = data_df.drop(columns=drop_features) # 舍去特征列
# 取出要作差值的特征名字(除去red前缀)
info_names = [c[3:] for c in df.columns if c.startswith('red')]
for info in info_names: # 对于每个特征名字
df['br' + info] = df['blue' + info] - df['red' + info] # 构造一个新的特征,由蓝色特征减去红色特征,前缀为br
# 原有的FirstBlood可删除
df = df.drop(columns=['blueFirstBlood', 'redFirstBlood'])
# 离散化每一列特征
discrete_df = df.copy() # 先复制一份数据
for c in df.columns[1:]: # 遍历每一列特征,跳过标签列
unique_values = df[c].nunique()
if unique_values <= 10: # 如果特征取值少于等于10个,直接跳过
continue
# 使用等区间离散化
discrete_df[c] = pd.cut(df[c], bins=10, labels=False)
# 准备数据
all_y = discrete_df['blueWins'].values # 所有标签数据
feature_names = discrete_df.columns[1:] # 所有特征的名称
all_x = discrete_df[feature_names].values # 所有原始特征值,pandas的DataFrame.values取出为numpy的array矩阵
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(all_x, all_y, test_size=0.2, random_state=RANDOM_SEED)
all_y.shape, all_x.shape, x_train.shape, x_test.shape, y_train.shape, y_test.shape # 输出数据行列信息
# 定义决策树类
class DecisionTree(object):
def __init__(self, classes, features, max_depth=10, min_samples_split=10, impurity_t='entropy'):
self.classes = classes
self.features = features
self.max_depth = max_depth
self.min_samples_split = min_samples_split
self.impurity_t = impurity_t
self.root = None # 定义根节点,未训练时为空
def impurity(self, labels):
if self.impurity_t == 'entropy':
counter = Counter(labels)
probabilities = [count / len(labels) for count in counter.values()]
entropy = -sum(p * np.log2(p) for p in probabilities)
return entropy
elif self.impurity_t == 'gini':
counter = Counter(labels)
probabilities = [count / len(labels) for count in counter.values()]
gini = 1 - sum(p ** 2 for p in probabilities)
return gini
else:
raise ValueError("Unsupported impurity type")
def gain(self, feature, labels):
total_impurity = self.impurity(labels)
values = np.unique(feature)
weighted_impurity = 0
for value in values:
subset_labels = labels[feature == value]
weight = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1559
1559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











