







内存管理分为两个方面,一个是单个用户进程怎么布局和使用内存空间,这里的内存空间一般是虚拟内存;一个是操作系统内核如何管理内存,这里指的是真实的物理内存。前者是程序员可以考虑的,后者是对程序员彻底透明的,但是我们为了学习操作系统的原理,两个方面都需要理解。
本文只是理论概述,细节上还相当复杂。
Linux的虚拟内存管理技术:
对于32位操作系统,每个进程有4G的进程地址空间,该地址空间被人为的分为两个部分,用户空间与内核空间。
用户空间从0到3G(0xC0000000)。
内核空间从3G到4G。
用户进程通常情况下(用户态/目态)只能访问用户空间的虚拟地址,不能访问内核空间虚拟地址。只有用户进程进行系统调用(代表用户进程在内核态/管态执行)等时刻可以访问到内核空间。
对于一个进程,有属于自己的地址空间和内存空间,怎么使用这片空间是程序自己说的算的。此时我并不关心真正的内存条多大,即使内存条小于4G,我的地址空间也是4G,怎么做到的那是内核的事情。
进程如何布局自己的地址空间?
进程对内存的使用和管理方法跟程序本身的编译方法有关,一般的内存布局为:
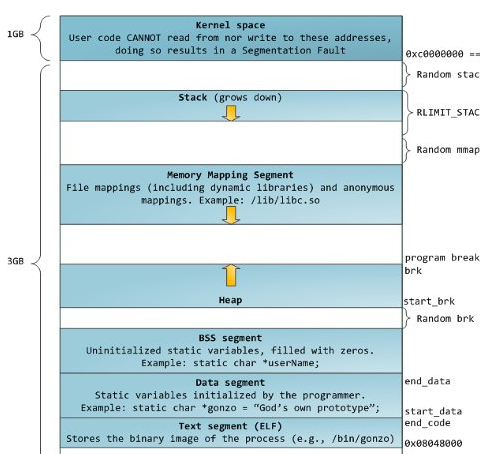
注意图片右侧的说明:program break程序中断点是堆空间的尾部边界。
如何管理自己的虚拟内存空间?:mm_strcut
每个进程都有自己独立的mm_struct,使得每个进程都有一个抽象的平坦的独立的32位地址空间,各个进程都在各自的地址空间中相同的地址内存存放不同的数据而且互不干扰。mm_struct用来描述一个进程的虚拟地址空间。
struct mm_struct {
struct vm_area_struct * mmap; /* 指向虚拟区间(VMA)链表 */
rb_root_t mm_rb; /*指向red_black树*/
struct vm_area_struct * mmap_cache; /* 指向最近找到的虚拟区间*/
pgd_t * pgd; /*指向进程的页目录*/
atomic_t mm_users; /* 用户空间中的有多少用户*/
atomic_t mm_count; /* 对"struct mm_struct"有多少引用*/
int map_count; /* 虚拟区间的个数*/
struct rw_semaphore mmap_sem;
spinlock_t page_table_lock; /* 保护任务页表和 mm->rss */
struct list_head mmlist; /*所有活动(active)mm的链表 */
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long rss, total_vm, locked_vm;
unsigned long def_flags;
unsigned long cpu_vm_mask;
unsigned long swap_address;
unsigned dumpable:1;
/* Architecture-specific MM context */
mm_context_t context;
}; 由于一般情况进程的3GB虚拟地址空间不可能是全部映射到物理内存中的,mm_struct结构中的vm_area_struct记录了虚拟地址空间的使用情况,描述了虚拟地址空间的一个区间。
vm_area_struct结构是以链表形式链接,不过为了方便查找,内核又以红黑树的形式组织内存区域,以便降低搜索耗时。并存的两种组织形式,并非冗余:链表用于需要遍历全部节点的时候用,而红黑树适用于在地址空间中定位特定内存区域的时候。内核为了内存区域上的各种不同操作都能获得高性能,同时使用了这两种数据结构。
struct vm_area_struct
struct mm_struct * vm_mm; /* 虚拟区间所在的地址空间*/
unsigned long vm_start; /* 在vm_mm中的起始地址*/
unsigned long vm_end; /*在vm_mm中的结束地址 */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next;
pgprot_t vm_page_prot; /* 对这个虚拟区间的存取权限 */
unsigned long vm_flags; /* 虚拟区间的标志. */
rb_node_t vm_rb;
/*
* For areas with an address space and backing store,
* one of the address_space->i_mmap{,shared} lists,
* for shm areas, the list of attaches, otherwise unused.
*/
struct vm_area_struct *vm_next_share;
struct vm_area_struct **vm_pprev_share;
/*对这个区间进行操作的函数 */
struct vm_operations_struct * vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units, *not* PAGE_CACHE_SIZE */
struct file * vm_file; /* File we map to (can be NULL). */
unsigned long vm_raend; /* XXX: put full readahead info here. */
void * vm_private_data; /* was vm_pte (shared mem) */
};什么时候才出现物理内存?
实际的物理内存只有当进程真的去访问新获取的虚拟地址时,才会由“请求页机制”产生“缺页”异常,从而进入分配实际页面的例程。也就是说,进程内存空间没有使用过的地址一定不占用实际内存,进程内存空间有使用但没有访问的地址也不一定占用实际内存。这样才能使得一个4G的物理内存却能“容得下”几十个4G的虚拟内存空间。
实际物理内存如何分配?:
1、页面 + 伙伴关系
Linux内核管理物理内存是通过分页机制实现的,它将整个内存划分成无数个4KB(i386体系结构)大小的页,作为分配和回收内存的基本单位。利用分页管理有助于灵活分配内存地址,分配物理内存时不必要求必须有大块的连续内存,系统可以东一页、西一页的凑出所需要的内存供进程使用。
虽然能够分配离散的物理内存页面给进程,但实际系统使用内存时使用离散的内存时间效率要低些,因为分配连续内存时,页表不需要更改,因此能降低TLB的刷新率。为了更完善的管理,避免物理内存页面的使用过于离散,采用了“伙伴”关系来管理空闲页面。把所有的空闲页面分组为11个块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续页面的页面块。只能从这些快链表中申请页面,每次只能是申请2的幂倍页面大小,那么最大可以申请1024个连续页面,对应4MB大小的连续内存。如果申请时没有合适的页面块,则需要把更大的块分裂成两个较小的块,分配一个出去,另一个加入对应的块链表。
内核中分配空闲页面的基本函数是get_free_page/get_free_pages。
2、Slab缓冲
4KB的页面对于某些小的数据,尤其是内核一些数据结构来讲仍然是太大了,不仅一个页面内部用不完,并且还会出现很多单个的离散页面。为解决这类问题引入了Slab。
slab分配器是基于对象进行管理的,相同类型的对象归为一类(如进程描述符就是一类)。每当要申请这样一个对象,slab分配器就从一个slab列表中分配一个这样大小的单元出去。而当要释放该对象时,将其重新保存在该列表中,而不是直接返回给伙伴系统,从而避免这些内碎片。
slab分配器并不丢弃已分配的对象,而是释放并把它们保存在内存中。当以后又要请求新的对象时,就可以从内存直接获取而不用重复初始化。
内存分配函数
malloc函数在进程虚拟空间中的堆中进行动态分配,实际上是调用brk()系统调用,该调用的作用是扩大或缩小进程堆空间。
·如果当前分配给进程的页面的剩余空间足够,则直接扩大即可;
·如果现有的内存区域不够容纳堆空间,则会以页面大小的倍数为单位,扩张或收缩对应的内存区域,但堆空间并非以页面大小为倍数修改,而是按实际请求修改。
因此,malloc在用户空间分配内存以字节为单位分配,但内核在内部以页为单位分配的。















 188
188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









